Diese Maschine soll den gesamten Trainingsdatensatz selbst erzeugen oder den gesamten Trainingsdatensatz auf der Grundlage eines Hinweises aus den Originaldaten erzeugen. Bei einem Bitmap-Bild, das den Hinweis „SCI“ enthält, würde die Maschine beispielsweise anhand der gelernten Gewichte selbständig „ENCE“ generieren.
Um sich ein Bild von dem System vor unserem geistigen Auge zu machen, betrachten wir Abbildung 5.
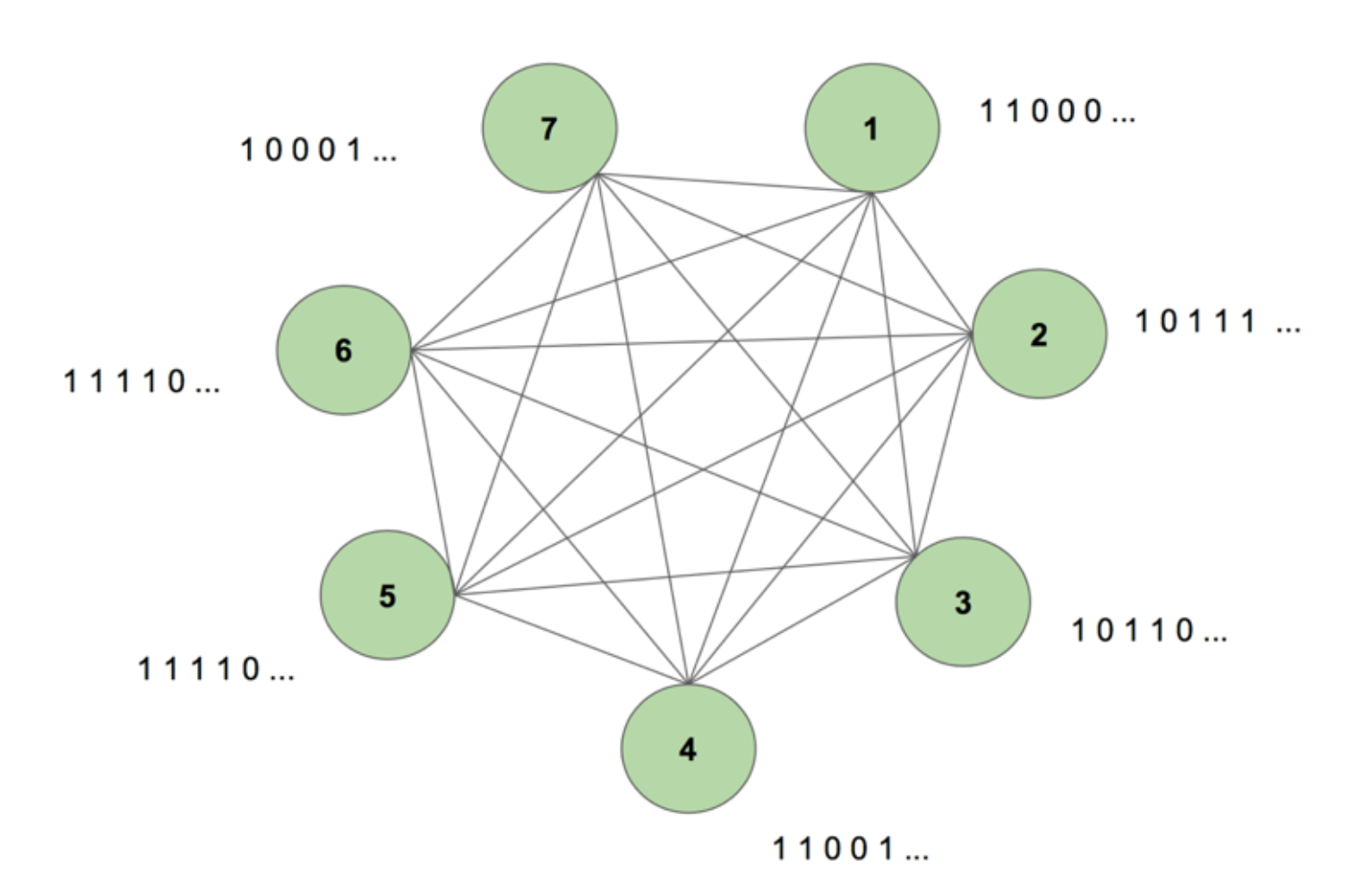
Die Maschine enthält sieben Knotenpunkte. Die Zielsequenz ist ein 7 x 35 Bitmap-Bild, das das Wort SCIENCE (Wissenschaft) darstellt. Eine Trainingsperiode besteht darin, der Maschine diese Zielsequenz einmal zu zeigen. Die Zielsequenz wird in 35 Streifen von 7 Werten zerlegt und in der gleichen Reihenfolge in die Maschine eingespeist, wie sie in der Zielsequenz erscheint. Abbildung 5 zeigt, wie fünf solcher Eingabestreifen aussehen würden. Wir sehen, dass der erste Streifen unserer Bitmap, bestehend aus allen 1en, sich im ersten Wert der Eingänge der Knoten widerspiegelt. Auf diese Weise geben wir während des Trainings Werte in die Maschine ein.
Wenn wir die Maschine zum ersten Mal mit beliebigen Gewichten initialisieren und sie auffordern, eine Sequenz zu erzeugen, erzeugt sie etwas völlig Zufälliges. Nachdem wir die Maschine 130.000 Trainingsperioden lang trainiert haben, ist sie in der Lage, die gesamte Sequenz selbständig zu erzeugen. Das bedeutet, dass sie während des Trainings ihre Gewichte so optimiert, dass sie nicht nur das gleichzeitige Auftreten von Bits in einem Zeitschritt lernt, sondern über eine ganze Sequenz hinweg.
Zauberhaft, nicht wahr? Aber hinter diesem Zaubertrick steckt eine solide Logik. Lassen Sie uns das Geheimnis lüften und sehen, warum diese „Boltzmann-Maschine mit Speicher“ funktioniert.

Dies ist die Struktur einer dynamischen Boltzmann-Maschine (DyBM). In einer Boltzmann-Maschine enthält ein Knoten Informationen darüber, welche Knoten ihn zu einem bestimmten Zeitpunkt aktivieren. Dadurch wird er auf Ereignisse aufmerksam, die zusammen auftreten, hat aber nicht die Möglichkeit, zurückzublicken und Assoziationen über verschiedene Zeitschritte hinweg herzustellen. In einem DyBM stellen die Verbindungen zwischen den Knoten jedoch dar, wie die Knoten im Laufe der Zeit interagieren, nicht nur zu einem bestimmten Zeitpunkt. Das DyBM erleichtert dies, indem es eine Leitungsverzögerung zwischen den Knoten hinzufügt.
Mit dieser neuen Architektur verfügt ein Knoten über Informationen darüber, welche anderen Knoten seine Aktivierung zu einem bestimmten Zeitschritt T = t durch ihre eigenen Aktivitäten in den vergangenen Zeitschritten T = t – 1, T = t – 2 usw. katalysiert haben. Dieses „Gedächtnis“ wird einem Knoten in Form einer Speichereinheit hinzugefügt. Diese Einheit verändert die Wahrscheinlichkeit, dass ein Knoten zu einem beliebigen Zeitpunkt aktiviert wird, in Abhängigkeit von den vorherigen Werten anderer Knoten und den eigenen zugehörigen Gewichten.
Angenommen, wir haben zwei Knoten A und B. Auf einer hohen Ebene erweitern wir die Vorstellung, dass „Neuronen, die zusammen feuern, zusammen verdrahtet sind“, über die Dimension der Zeit. Stellen Sie sich zum Beispiel vor, dass die Aktivierung von A nach zwei Zeitschritten konsequent zur Aktivierung von B führt. Eine nicht-dynamische Boltzmann-Maschine kann dieses Muster nicht erfassen, aber mit einer DyBM kann ich das Muster, dass B = 1 irgendwann nach A = 1 ist, erfassen, da der Wert von A nach einer gewissen Verzögerung zu B wandert. Nun variiert die Wahrscheinlichkeit, dass B = 1 zum Zeitpunkt T = t ist, nicht nur auf der Grundlage des Werts von A zum Zeitpunkt T = t, sondern auch auf der Grundlage der Werte von A zum Zeitpunkt T = t – 1, T = t – 2 usw., je nachdem, wie groß die Leitungsverzögerung zwischen A und B ist.
Die Maschine speichert die Werte so, dass die jüngsten Werte stärker gewichtet werden, was sinnvoll ist, da im Allgemeinen die jüngsten Teile einer Zeitreihe am aufschlussreichsten über den jüngsten Trend sind. Ein DyBM speichert diese Information in den Berechtigungsspuren. Die Synaptic Eligibility Trace von B enthält die gewichtete Summe der Werte, die B von A nach einer gewissen Leitungsverzögerung erreicht haben. Die neuronale Eignungsspur von B enthält die gewichtete Summe seiner vergangenen Werte.
Ähnlich wie bei standardmäßigen rekurrenten neuronalen Netzen können wir das DyBM über die Zeit entfalten. Die entfaltete DyBM ist eine Boltzmann-Maschine mit einer unendlichen Anzahl von Einheiten, von denen jede den Wert eines Knotens zu einem bestimmten Zeitpunkt repräsentiert.
Das ist also die Dynamische Boltzmann-Maschine: eine Architektur, die in der Lage ist, die Trainingsdaten nicht nur zu einem bestimmten Zeitpunkt, sondern über eine ganze Sequenz dieser Daten neu zu erstellen.
DyBMs sind faszinierend, und der folgende Teil bringt es auf den Punkt.
Teil 4: Gegenüberstellung von RNN-Gaussian-DyBM und LSTM
Alle Beispiele, die wir bisher gesehen haben, haben sich mit binären Daten (Bernoulli-Verteilung) beschäftigt. IBM-Forscher sind einen Schritt weiter gegangen und haben ein DyBM entwickelt, das Gaußsche Verteilungen modellieren kann und es Benutzern wie uns ermöglicht, Zeitreihendaten mit DyBM und seinen Variationen zu modellieren.
Um die Effizienz eines DyBM zu überprüfen, habe ich einige Tests durchgeführt, in denen ich ein RNN-Gauß-DyBM (ein DyBM mit RNN-Schicht) mit dem aktuellen Stand der Technik, dem Long Short-Term Memory Neural Network, verglichen habe. Die Ergebnisse waren aufregend. Sie können diese Tests auf der Grundlage des hier verfügbaren Skripts gerne selbst durchführen.
Lassen Sie uns sehen, wie ein DyBM im Vergleich zu einem LSTM in einem Zeitreihen-Anwendungsfall abschneidet.
Anwendungsfall: Vorhersage des Wertes der nächsten Sonnenfleckenzahl.
Wir werden Daten verwenden, die die monatliche Sonnenfleckenzahl enthalten, die in einem Labor in Zürich von 1749 bis 1983 berechnet wurde. Die Daten sind Open Source und erhältlich bei Datamarket – Monthly sunspot number, Zurich, 1749-1983.
Zunächst wollen wir sehen, wie der LSTM funktioniert.
LSTM
- Architektur: LSTM Dimension = 10.
- Leistung über 10 Epochen: Mittleres Testergebnis LSTM = 0.08877 RMSE
- Pro Epoche Lernzeit: 8.689403 sec.

Nun werden wir sehen, wie ein RNN-Gaussian-DyBM auf den gleichen Daten abgeschnitten hat.
Halten Sie sich fest, dies wird eine sehr interessante Entdeckungsreise… Bereit?
RNN-Gaussian-DyBM
- Architektur: RNN Dimension = 10 und Input Dimension = 1
- Leistung über 10 Epochen: Mean Test Score LSTM = 0.07848 RMSE
- Pro Epoche Zeit zum Lernen: 0.90547 sec.

Das RNN-Gauß-DyBM läuft in diesem Fall nicht nur 10-mal schneller, sondern bietet auch eine bessere Leistung.
Wenn wir die Anzahl der Epochen für die beiden Modelle skalieren, nimmt der Zeitunterschied zwischen dem Training dieser beiden Modelle drastisch zu. Die DyBM-Antwortzeit ist viel schneller, so dass der Zyklus „Trainieren – Testen – Bereitstellen“ schrumpft und die Modelle viel schneller verbessert werden können.
Aber wir haben noch nicht über den besten Teil der DyBMs gesprochen: Man kann sie mit GPU-Beschleunigung beschleunigen. Ein DyBM, das auf einem Grafikprozessor auf IBM Watson Studio Local mit Power AI IBM Cloud Service läuft, kann Vorhersagen für mehr als 2000 Zeitreihen mit einer Länge von jeweils mehr als 500 in weniger als 10 Sekunden pro Epoche machen. Im Gegensatz dazu benötigt ein DyBM, das auf einer CPU läuft, etwas mehr als 30 Minuten für dieselbe Aufgabe. Vergleichen Sie dieses Ergebnis mit der Leistung eines LSTM auf der CPU aus dem vorherigen Beispiel. Stellen Sie sich nur einmal die Rechenleistung vor, die dadurch erzielt wird. Weitere Informationen über die Beschleunigung von DyBMs mit GPUs finden Sie hier. Es ist erwähnenswert, dass Sie auch LSTMs mit GPUs beschleunigen können, und der Leistungsvergleich zwischen einer beschleunigten DyBM und einer beschleunigten LSTM wird unterschiedlich ausfallen.
Wenn Sie das nächste Mal ein Zeitreihenproblem lösen möchten, sollten Sie Dynamic Boltzmann Machines ausprobieren. Ziehen Sie in Erwägung, mit dem IBM Research Tokyo GitHub Repository für Dynamic Boltzmann Machines zu beginnen, das Sie hier finden können.
Siehe unten für weitere vertiefte Forschung über energiebasierte Modelle, Boltzmann-Maschinen und dynamische Boltzmann-Maschinen:
- A Tutorial on Energy-Based Learning – Yann LeCun, Sumit Chopra, Raia Hadsell, Marc’Aurelio Ranzato, und Fu Jie Huang
- Boltzmann-Maschinen – Geoffrey Hinton
- Boltzmann-Maschinen und energiebasierte Modelle – Takayuki Osogami (IBM Research – Tokio)
- Sieben Neuronen, die sich Sequenzen von alphabetischen Bildern über spike-timing dependent plasticity – Takayuki Osogami and Makoto Otsuka
- Nonlinear Dynamic Boltzmann Machines for Time-Series Prediction – Sakyasingha Dasgupta and Takayuki Osogami (IBM Research – Tokyo)