Chcemy, aby ta maszyna generowała cały zestaw danych treningowych samodzielnie lub generowała cały zestaw danych treningowych w oparciu o wskazówkę z oryginalnych danych. Na przykład, biorąc pod uwagę obraz bitmapy zawierający „SCI”, maszyna sama wygeneruje „ENCE” na podstawie wyuczonych wag.
Aby uzyskać obraz systemu w naszym umyśle, rozważmy rysunek 5.
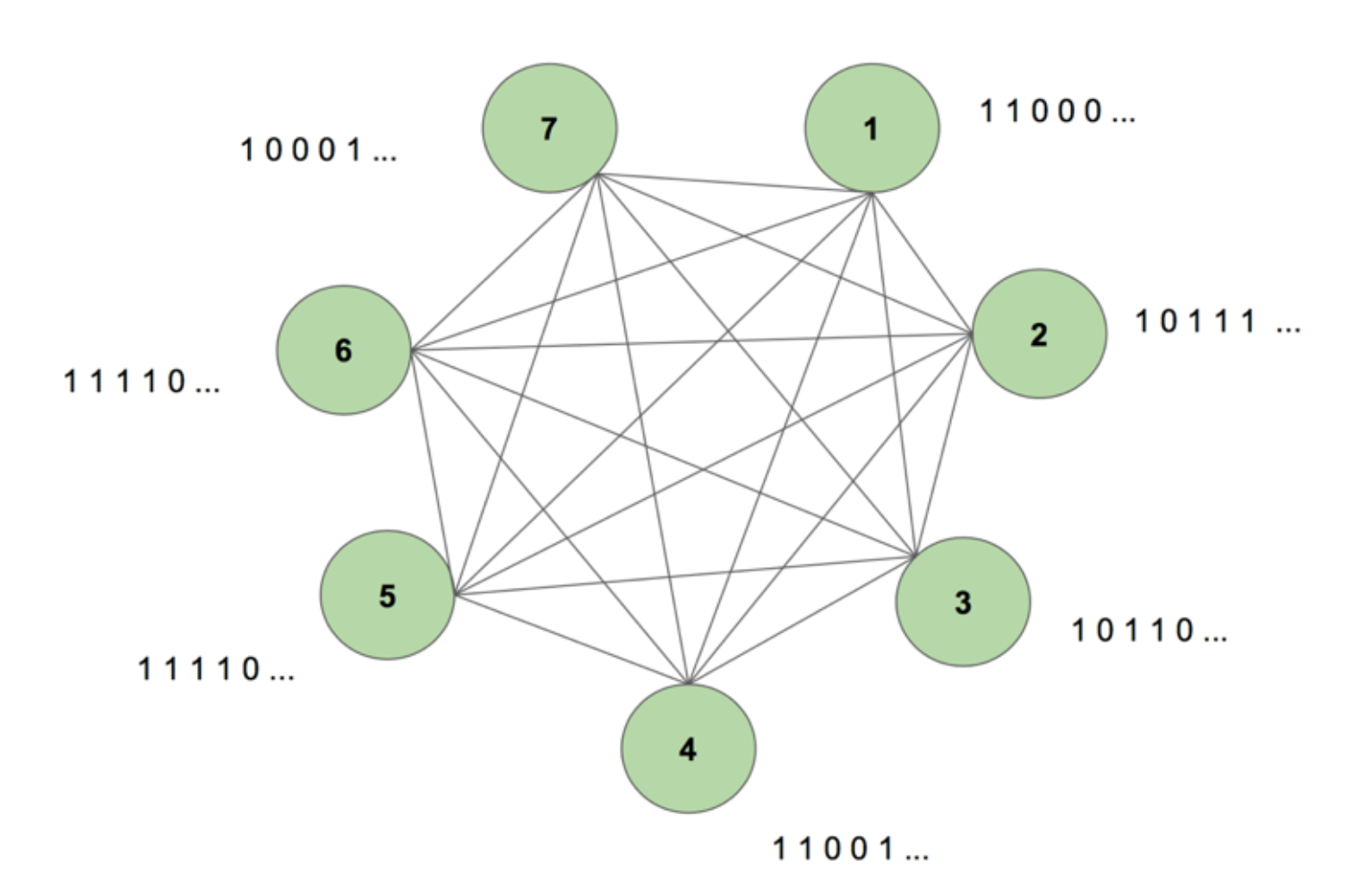
Maszyna zawiera siedem węzłów. Sekwencją docelową jest obraz bitmapy o wymiarach 7 na 35 przedstawiający słowo NAUKA. Jeden okres treningowy polega na jednokrotnym pokazaniu maszynie tej sekwencji. Cel jest dzielony na 35 pasków po 7 wartości i podawany do maszyny w takiej samej kolejności, w jakiej pojawia się w celu. Rysunek 5 pokazuje, jak wyglądałoby pięć takich pasków wejściowych. Widzimy, że pierwszy pasek naszej bitmapy, składający się ze wszystkich jedynek, jest odzwierciedlony w pierwszej wartości wejść węzłów. W ten właśnie sposób wprowadzamy wartości do maszyny podczas treningu.
Gdy po raz pierwszy inicjalizujemy maszynę z dowolnymi wagami i prosimy ją o wygenerowanie sekwencji, tworzy ona coś zupełnie przypadkowego. Po wytrenowaniu maszyny przez 130 000 okresów treningowych, jest ona w stanie samodzielnie wygenerować całą sekwencję. Oznacza to, że podczas treningu optymalizuje ona swoje wagi, aby nauczyć się nie tylko współwystępowania bitów w jednym kroku czasowym, ale w całej sekwencji.
Magiczne, prawda? Ale za tą magiczną sztuczką kryje się solidna logika. Rozwikłajmy tajemnicę i zobaczmy, dlaczego ta „maszyna Boltzmanna z pamięcią” działa.

Oto struktura dynamicznej maszyny Boltzmanna (DyBM). W dynamicznej maszynie Boltzmanna węzeł zawiera informacje o tym, które węzły aktywują go w danym momencie. To czyni go świadomym zdarzeń, które zachodzą razem, ale nie daje mu możliwości spojrzenia wstecz i budowania skojarzeń w różnych okresach czasu. Jednak w DyBM połączenia między węzłami reprezentują sposób, w jaki węzły oddziałują na siebie w czasie, a nie tylko w danym momencie. DyBM ułatwia to poprzez dodanie opóźnienia przewodzenia między węzłami.
Z tą nową architekturą, węzeł posiada informacje o tym, które inne węzły katalizowały jego aktywację w jakimś kroku czasowym T = t poprzez ich własne działania w przeszłych krokach czasowych T = t – 1, T = t – 2, i tak dalej. Ta „pamięć” jest dodawana do węzła w postaci jednostki pamięci. Ta jednostka zmienia prawdopodobieństwo, że węzeł jest aktywowany w dowolnym momencie, w zależności od poprzednich wartości innych węzłów i własnych powiązanych wag.
Zastanówmy się, że mamy 2 węzły A i B. Na wysokim poziomie, jesteśmy rozszerzenie pojęcia, że „neurony, które ogień razem, przewody razem” w wymiarze czasu. Na przykład, wyobraźmy sobie, że aktywacja A konsekwentnie prowadzi do aktywacji B po dwóch krokach czasowych. Niedynamiczna maszyna Boltzmanna nie uchwyci tego wzorca, ale z DyBM, ponieważ wartość A przemieszcza się do B z pewnym opóźnieniem, mogę uchwycić wzorzec, że B = 1 jakiś czas po A = 1. Teraz prawdopodobieństwo, że B = 1 w kroku czasowym T = t będzie się zmieniać w oparciu nie tylko o wartość A w T = t, ale także o wartości A w T = t – 1, T = t – 2, i tak dalej, w zależności od wielkości opóźnienia przewodzenia między A i B.
Maszyna przechowuje wartości tak, że ostatnie wartości mają większą wagę, co ma sens, ponieważ ogólnie rzecz biorąc najnowsze części serii czasowej są najbardziej informatywne o najnowszym trendzie. DyBM przechowuje te informacje w śladach kwalifikowalności. Synaptyczny ślad kwalifikacji B zawiera ważoną sumę wartości, które dotarły do B z A po pewnym opóźnieniu przewodzenia. Neuronowy ślad kwalifikacji B zawiera ważoną sumę jego przeszłych wartości.
Podobnie jak w przypadku standardowych rekurencyjnych sieci neuronowych, możemy rozwinąć DyBM w czasie. Rozłożona DyBM jest maszyną Boltzmanna posiadającą nieskończoną liczbę jednostek, z których każda reprezentuje wartość węzła w określonym czasie.
Jest to więc Dynamiczna Maszyna Boltzmanna: architektura, która ma moc odtwarzania danych treningowych nie tylko w jednym punkcie w czasie, ale w całej sekwencji tych danych.
DyBMy są fascynujące, a część, która następuje po nich, przybliża ten temat.
Część 4: Starcie między RNN-Gaussian-DyBM a LSTM
Wszystkie przykłady, które widzieliśmy do tej pory, dotyczyły danych binarnych (rozkład Bernoulliego). Naukowcy IBM poszli o krok dalej i stworzyli DyBM, który może modelować rozkłady gaussowskie i umożliwili użytkownikom takim jak my modelowanie danych szeregów czasowych za pomocą DyBM i jego odmian.
Aby sprawdzić efektywność DyBM, przeprowadziłem kilka testów porównujących RNN-Gaussian-DyBM (DyBM z warstwą RNN) i aktualny state-of-the-art, Long Short-Term Memory Neural Network. Wyniki były ekscytujące. Zapraszamy do przeprowadzenia tych testów na własną rękę, w oparciu o skrypt dostępny tutaj.
Zobaczmy, jak DyBM wypada w porównaniu z LSTM na przykładzie szeregu czasowego.
Przypadek użycia: Predict the value of the next sunspot number.
Użyjemy danych zawierających Monthly Sunspot Number obliczonych w laboratorium w Zurychu od roku 1749 do 1983. Dane są open source i dostępne w Datamarket – Monthly sunspot number, Zurich, 1749-1983.
Na początek zobaczmy, jak spisał się LSTM.
LSTM
- Architektura: LSTM Dimension = 10.
- Performance over 10 epochs: Mean Test Score LSTM = 0.08877 RMSE
- Per epoch time to learn: 8.689403 sek.

Teraz zobaczymy, jak RNN-Gaussian-DyBM wypadł na tych samych danych.
Obejmij się, to będzie bardzo interesująca podróż odkrywcza… Gotowi?
RNN-Gaussian-DyBM
- Architektura: RNN Dimension = 10 and Input Dimension = 1
- Performance over 10 epochs: Mean Test Score LSTM = 0.07848 RMSE
- Per epoch time to learn: 0.90547 sec.

Nie tylko RNN-Gaussian-DyBM działa 10 razy szybciej w tym przypadku, ale również oferuje lepszą wydajność.
W miarę jak skalujemy liczbę epok dla tych dwóch modeli, różnica czasu pomiędzy treningiem tych dwóch modeli drastycznie wzrasta. Czas odpowiedzi DyBM jest znacznie szybszy, więc cykl train – test – deploy kurczy się i można znacznie szybciej ulepszać modele.
Ale nie omówiliśmy jeszcze najlepszej części DyBM: Możesz je przyspieszyć dzięki akceleracji na GPU. DyBM działający na GPU w IBM Watson Studio Local z usługą Power AI IBM Cloud może tworzyć prognozy dla ponad 2000 szeregów czasowych, z których każdy ma długość ponad 500, w czasie krótszym niż 10 sekund na epokę. Dla porównania, DyBM działający na CPU potrzebuje nieco ponad 30 minut, aby wykonać to samo zadanie. Porównaj ten wynik z wydajnością LSTM na CPU z poprzedniego przykładu. Wyobraź sobie, jaką to daje moc obliczeniową. Więcej informacji na temat akceleracji DyBM za pomocą jednostek GPU można znaleźć tutaj. Warto zauważyć, że można również akcelerować LSTM na GPU, a porównanie wydajności pomiędzy akcelerowanym DyBM a akcelerowanym LSTM będzie inne.
Następnym razem, gdy będziesz chciał rozwiązać problem związany z szeregami czasowymi, wypróbuj Dynamic Boltzmann Machines. Rozważ rozpoczęcie od repozytorium IBM Research Tokyo GitHub dla Dynamic Boltzmann Machines, które można znaleźć tutaj.
Zobacz poniżej dodatkowe dogłębne badania na temat Energy-Based Models, Maszyn Boltzmanna i Dynamicznych Maszyn Boltzmanna:
- A Tutorial on Energy-Based Learning – Yann LeCun, Sumit Chopra, Raia Hadsell, Marc’Aurelio Ranzato, and Fu Jie Huang
- Maszyny Boltzmanna – Geoffrey Hinton
- Maszyny Boltzmanna i modele oparte na energii – Takayuki Osogami (IBM Research – Tokio)
- Siedem neuronów zapamiętujących sekwencje obrazów alfabetycznych poprzez plastyczność zależną od czasu spajków – Takayuki Osogami (IBM Research – Tokio)
- Seven neurons memorizing sequences of alphabetical images via spike-timing dependent plasticity – Takayuki Osogami and Makoto Otsuka
- Nonlinear Dynamic Boltzmann Machines for Time-Series Prediction – Sakyasingha Dasgupta and Takayuki Osogami (IBM Research – Tokyo)