A hibakezelés az RxJs alapvető része, hiszen szinte minden reaktív programban, amit írunk, szükségünk lesz rá.
A hibakezelés az RxJS-ben valószínűleg nem olyan jól ismert, mint a könyvtár más részei, de valójában elég egyszerű megérteni, ha először az Observable szerződés általános megértésére koncentrálunk.
Ebben a bejegyzésben az alapoktól (az Observable szerződés) kezdve egy teljes útmutatót adunk, amely tartalmazza a leggyakoribb hibakezelési stratégiákat, amelyekre a legtöbb gyakorlati forgatókönyv lefedéséhez szükségünk lesz.
- Tartalomjegyzék
- A megfigyelhető szerződés és a hibakezelés
- RxJs feliratkozás és hibahívások
- Teljesítési viselkedési példa
- A subscribe hibakezelő korlátjai
- A catchError operátor
- Hogyan működik a catchError?
- Mi történik, ha hibát dobunk?
- A Catch and Replace stratégia
- A Catch and Rethrow stratégia
- Catch és Rethrow bontás
- A catchError többszöri használata egy Observable-láncban
- A finalize operátor
- Finalize operátor példa
- A megismétlési stratégia
- Mikor kell újrapróbálni?
- RxJs retryWhen Operator márványdiagram
- Breaking down how retryWhen works
- Elkészíteni egy Notification Observable-t
- Immediate Retry Strategy
- Immediate Retry Console Output
- Késleltetett újrapróbálkozási stratégia
- A timer Observable létrehozási függvény
- A delayWhen operátor
- delayWhen Operator bontása
- Késleltetett újratöltési stratégia megvalósítása
- Retry Strategy Console Output
- Futó Github tároló (kódmintákkal)
- Következtetések
Tartalomjegyzék
Ebben a bejegyzésben a következő témákkal foglalkozunk:
- A megfigyelhető szerződés és a hibakezelés
- RxJs feliratkozás és hibahívások
- A catchError operátor
- A Catch és Replace. Stratégia
- throwError és a Catch and Rethrow stratégia
- A catchError többszöri használata egy Observable láncban
- A finalize operátor
- A Retry. Strategy
- Then retryWhen Operator
- Előzetes Observable létrehozása
- Immediate Retry Strategy
- Delayed Retry Strategy
- The delayWhen Operator
- Az időzítő Observable létrehozásának függvénye
- A Github repository futtatása (kódmintákkal)
- Következtetések
Szóval minden további nélkül, kezdjünk bele az RxJs hibakezelési mélymerülésünkbe!
A megfigyelhető szerződés és a hibakezelés
Az RxJs hibakezelés megértéséhez először is meg kell értenünk, hogy egy adott folyam csak egyszer hibázhat. Ezt az Observable szerződés határozza meg, amely kimondja, hogy egy stream nulla vagy több értéket adhat ki.
A szerződés azért működik így, mert a gyakorlatban éppen így működik az összes stream, amelyet a futásidőnkben megfigyelünk. A hálózati kérések például meghiúsulhatnak.
A folyam befejeződhet is, ami azt jelenti, hogy:
- a folyam hiba nélkül befejezte az életciklusát
- a befejezés után a folyam nem bocsát ki több értéket
A befejezés alternatívájaként a folyam hibázhat is, ami azt jelenti, hogy:
- a folyam hibával fejezte be életciklusát
- a hiba kidobása után a folyam nem fog további értékeket kibocsátani
Megjegyezzük, hogy a befejezés és a hiba kölcsönösen kizárják egymást:
- ha a folyam befejezi, utána nem hibázhat
- ha a folyam hibázik, utána nem fejezheti be
Megjegyezzük azt is, hogy a folyamnak nem kötelező befejezni vagy hibázni, ez a két lehetőség opcionális. De a kettő közül csak az egyik fordulhat elő, mindkettő nem.
Ez azt jelenti, hogy ha egy adott folyam hibásodik, akkor az Observable szerződés szerint nem használhatjuk tovább. Most biztosan arra gondolsz, hogy akkor hogyan tudjuk helyreállítani a hibát?
RxJs feliratkozás és hibahívások
Hogy az RxJs hibakezelési viselkedését a gyakorlatban is láthassuk, hozzunk létre egy folyamot és iratkozzunk fel rá. Ne feledjük, hogy a subscribe hívás három opcionális argumentumot fogad el:
- egy sikerkezelő függvényt, amely minden alkalommal meghívásra kerül, amikor a folyam értéket ad ki
- egy hibakezelő függvényt, amely csak akkor hívódik meg, ha hiba lép fel. Ez a kezelő maga is megkapja a hibát
- egy befejező kezelő függvény, amely csak akkor hívódik meg, ha a folyam befejeződik
Teljesítési viselkedési példa
Ha a folyam nem hibázik, akkor a konzolon ezt látnánk:
HTTP response {payload: Array(9)}HTTP request completed.Amint látjuk, ez a HTTP folyam csak egy értéket bocsát ki, majd befejeződik, ami azt jelenti, hogy nem történt hiba.
De mi történik, ha a folyam ehelyett hibát dob? Ebben az esetben helyette a következőket látjuk a konzolon:

Amint látjuk, a folyam nem bocsátott ki értéket, és azonnal hiba lépett fel. A hiba után nem történt befejezés.
A subscribe hibakezelő korlátjai
A hibák subscribe hívással történő kezelése néha elegendő, de ez a hibakezelési megközelítés korlátozott. Ezzel a megközelítéssel például nem tudjuk helyreállítani a hibát, vagy nem tudunk alternatív tartalékértéket kibocsátani, amely helyettesíti azt az értéket, amelyet a backendtől vártunk.
Majd ismerkedjünk meg néhány olyan operátorral, amelyek lehetővé teszik számunkra néhány fejlettebb hibakezelési stratégia megvalósítását.
A catchError operátor
A szinkron programozásban lehetőségünk van egy kódblokkot egy try záradékba csomagolni, egy catch blokkal elkapni minden hibát, amelyet az esetleg dob, majd kezelni a hibát.
Íme, így néz ki a szinkron catch szintaxis:
Ez a mechanizmus nagyon erős, mert egy helyen tudjuk kezelni a try/catch blokkban bekövetkező hibát.
A probléma az, hogy a Javascriptben sok művelet aszinkron, és egy HTTP-hívás egy ilyen példa, ahol a dolgok aszinkron történnek.
A RxJs az RxJs catchError operátoron keresztül biztosít számunkra valami ehhez közeli funkciót.
Hogyan működik a catchError?
A szokásos módon és mint minden RxJs operátor esetében, a catchError egyszerűen egy függvény, amely egy bemeneti Observable-t vesz fel, és egy kimeneti Observable-t ad ki.
A catchError minden egyes hívásával át kell adnunk neki egy függvényt, amelyet hibakezelő függvénynek hívunk.
A catchError operátor bemenetként egy olyan Observable-t vesz fel, amely esetleg hibázik, és a kimeneti Observable-ben elkezdi kibocsátani a bemeneti Observable értékeit.
Ha nem történik hiba, a catchError által előállított kimeneti Observable pontosan ugyanúgy működik, mint a bemeneti Observable.
Mi történik, ha hibát dobunk?
Ha azonban hiba történik, akkor a catchError logikája lép működésbe. A catchError operátor átveszi a hibát, és átadja a hibakezelő függvénynek.
Ez a függvény várhatóan egy Observable-t fog visszaadni, amely egy helyettesítő Observable lesz az éppen hibázó folyam számára.
Emlékezzünk arra, hogy a catchError bemeneti adatfolyama hibásodott meg, így az Observable szerződés szerint nem használhatjuk tovább.
Ezt a helyettesítő Observable-t ezután fel fogjuk jegyezni, és az értékeit a hibásodott bemeneti Observable helyett fogjuk használni.
A Catch and Replace stratégia
Mutatunk egy példát arra, hogyan lehet a catchError segítségével egy helyettesítő Observable-t biztosítani, amely fallback értékeket bocsát ki:
Bontjuk le a catch and replace stratégia megvalósítását:
- a catchError operátornak átadunk egy függvényt, ami a hibakezelő függvény
- a hibakezelő függvényt nem hívjuk meg azonnal, és általában nem is szoktuk meghívni
- csak akkor hívjuk meg a hibakezelő függvényt, ha a catchError bemeneti Observable-jében hiba lép fel
- ha a bemeneti folyamban hiba történik, ez a függvény ekkor egy
of()függvény segítségével felépített Observable-t ad vissza - a
of()függvény felépít egy Observable-t, amely csak egy értéket ad ki (), majd befejezi - a hibakezelő függvény visszaadja a helyreállító Observable-t (
of()), amelyre a catchError operátor feliratkozik - a recovery Observable értékei ezután a catchError
által visszaadott kimeneti Observable-ben helyettesítő értékként kerülnek kibocsátásra
A végeredmény az http$ Observable többé nem hibásodik meg! Íme az eredmény, amit a konzolon kapunk:
HTTP response HTTP request completed. Amint látjuk, a subscribe()-ban lévő hibakezelő callback többé nem hívódik meg. Ehelyett a következő történik:
- a
üres tömbérték kerül kibocsátásra - a
http$Observable ezután befejeződik
Amint látjuk, a helyettesítő Observable-t arra használták, hogy egy alapértelmezett visszaesési értéket () adjon a http$ feliratkozóinak, annak ellenére, hogy az eredeti Observable hibázott.
Megjegyezzük, hogy a helyettesítő Observable visszaadása előtt némi helyi hibakezelést is hozzáadhattunk volna!
Ezzel le is fedeztük a Catch and Replace stratégiát, most nézzük meg, hogyan használhatjuk a catchError-t is a hiba újradobására, ahelyett, hogy tartalékértékeket adnánk meg.
A Catch and Rethrow stratégia
Kezdésként vegyük észre, hogy a catchError segítségével megadott helyettesítő Observable maga is hibázhat, mint bármely más Observable.
És ha ez megtörténik, a hiba továbbterjed a catchError kimeneti Observable előfizetőire.
Ez a hibaterjesztési viselkedés egy mechanizmust ad nekünk arra, hogy a catchError által elkapott hibát a hiba helyi kezelése után újra eldobjuk. Ezt a következő módon tehetjük meg:
Catch és Rethrow bontás
Bontjuk le lépésről lépésre a Catch és Rethrow stratégia megvalósítását:
- csakúgy, mint korábban, elkapjuk a hibát, és visszaadunk egy helyettesítő Observable-t
- de ezúttal ahelyett, hogy helyettesítő kimeneti értéket adnánk, mint
, most helyileg kezeljük a hibát a catchError függvényben - a jelen esetben egyszerűen naplózzuk a hibát a konzolra, de ehelyett tetszőleges helyi hibakezelési logikát adhatunk hozzá, mint például egy hibaüzenet megjelenítése a felhasználónak
- Ezután egy helyettesítő Observable-t adunk vissza, amelyet ezúttal a throwError
- throwError segítségével hoztunk létre egy Observable-t, amely soha nem ad ki semmilyen értéket. Ehelyett azonnal hibázik ugyanazzal a hibával, amelyet a catchError
- fogott el, ami azt jelenti, hogy a catchError kimeneti Observable-je is pontosan ugyanazzal a hibával fog hibázni, amelyet a catchError
- bemenete dobott el, ami azt jelenti, hogy sikerült sikeresen visszadobnunk a catchError bemeneti Observable-je által eredetileg dobott hibát a kimeneti Observable
- a hibát most az Observable-lánc többi része tovább tudja kezelni, ha szükséges
Ha most lefuttatjuk a fenti kódot, itt az eredmény, amit a konzolon kapunk:

Mint láthatjuk, ugyanaz a hiba mind a catchError blokkban, mind a feliratkozási hibakezelő függvényben naplózásra került, ahogyan az várható volt.
A catchError többszöri használata egy Observable-láncban
Megjegyezzük, hogy szükség esetén a catchError-t többször is használhatjuk az Observable-lánc különböző pontjain, és a lánc egyes pontjain különböző hibastratégiákat alkalmazhatunk.
Elkaphatunk például egy hibát az Observable láncban feljebb, lokálisan kezelhetjük és újra eldobhatjuk, majd az Observable láncban lejjebb újra elkaphatjuk ugyanazt a hibát és ezúttal megadhatunk egy visszaesési értéket (az újra eldobás helyett):
Ha a fenti kódot futtatjuk, ezt a kimenetet kapjuk a konzolon:
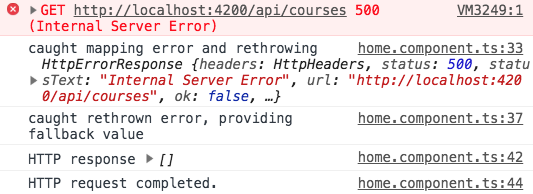
Amint láthatjuk, a hiba kezdetben valóban újra eldobásra került, de soha nem jutott el a subscribe hibakezelő függvényhez. Ehelyett a vártnak megfelelően a fallback értéket adta ki.
A finalize operátor
A hibakezelésre szolgáló catch blokk mellett a szinkron Javascript szintaxis egy finally blokkot is biztosít, amelyet olyan kód futtatására használhatunk, amelyet mindig szeretnénk végrehajtani.
A finally blokkot jellemzően drága erőforrások felszabadítására használjuk, mint például a hálózati kapcsolatok lezárása vagy a memória felszabadítása.
A catch blokkban lévő kódtól eltérően a finally blokkban lévő kód attól függetlenül végrehajtásra kerül, hogy hibát dob-e vagy sem:
A RxJs biztosít számunkra egy operátort, amely a finally funkcionalitáshoz hasonlóan viselkedik, az úgynevezett finalize operátort.
Figyelem: nem hívhatjuk helyette finally operátornak, mivel a finally egy fenntartott kulcsszó a Javascriptben
Finalize operátor példa
A catchError operátorhoz hasonlóan szükség esetén az Observable lánc különböző helyein több finalize hívást is hozzáadhatunk, hogy a több erőforrás megfelelő felszabadítása biztosított legyen:
Futtassuk most ezt a kódot, és nézzük meg, hogyan hajtódik végre a több finalize blokk:

Figyeljük meg, hogy az utolsó finalize blokk a subscribe value handler és a completion handler függvények után kerül végrehajtásra.
A megismétlési stratégia
A hiba újradobásának vagy a tartalékértékek megadásának alternatívájaként egyszerűen újra megpróbálhatunk feliratkozni a hibásodó Observable-re.
Ne feledjük, ha a folyam egyszer hibásodik, nem tudjuk helyreállítani, de semmi sem akadályozza meg, hogy újra feliratkozzunk az Observable-re, amelyből a folyam származik, és létrehozzunk egy másik folyamot.
Ez így működik:
- fogjuk a bemeneti Observable-t, és feliratkozunk rá, ami egy új folyamot hoz létre
- ha ez a folyam nem hibázik, hagyjuk, hogy az értékei megjelenjenek a kimeneten
- de ha a folyam hibázik, akkor újra feliratkozunk a bemeneti Observable-re, és létrehozunk egy teljesen új folyamot
Mikor kell újrapróbálni?
A nagy kérdés itt az, hogy mikor fogunk újra feliratkozni a bemeneti Observable-re, és újra megpróbáljuk végrehajtani a bemeneti folyamot?
- vagy azonnal újrapróbáljuk?
- vagy várunk egy kis késleltetést, remélve, hogy a probléma megoldódik, és aztán újra megpróbáljuk?
- csak korlátozott számúszor próbáljuk meg újra, és utána hibázzuk ki a kimeneti folyamot?
Ezek a kérdések megválaszolásához szükségünk lesz egy második segéd Observable-re, amit Notifier Observable-nek fogunk hívni. Ez a Notifier
Observable fogja meghatározni, hogy mikor történik meg az újbóli próbálkozás.
A Notifier Observable-t a retryWhen operátor fogja használni, ami a Retry stratégia szíve.
RxJs retryWhen Operator márványdiagram
Hogy megértsük, hogyan működik a retryWhen Observable, nézzük meg a márványdiagramját:

Nézzük meg, hogy az újrapróbált Observable a felülről második sorban lévő 1-2 Observable, és nem az első sorban lévő Observable.
Az első sorban lévő Observable r-r értékekkel a Notification Observable, amely meghatározza, hogy mikor történjen meg az újbóli próbálkozás.
Breaking down how retryWhen works
Bontjuk le, mi történik ezen a diagramon:
- Az Observable 1-2 feliratkozik, és értékei azonnal tükröződnek a retry által visszaküldött kimeneti Observable-benMikor
- még az Observable 1-2 befejezése után is újra lehet próbálkozni
- a notification Observable ekkor egy
rértéket ad ki, az Observable 1-2 befejezése után - A notification Observable által kibocsátott érték (ebben az esetben
r) bármi lehet - a lényeg az a pillanat, amikor a
rértéket kibocsátották, mert ez fogja kiváltani az 1-2 Observable újbóli próbálkozását - az 1-2 Observable-re a retryWhen ismét feliratkozik, és az értékei ismét megjelennek a retryWhen kimeneti Observable-jében
- A notification Observable ezután ismét kibocsát egy másik
rértéket, és ugyanez történik: Az újonnan feliratkozott 1-2 folyam értékei elkezdenek tükröződni a retryWhen - kimenetén, de aztán a notification Observable végül befejeződik
- abban a pillanatban, az 1-2 Observable folyamatban lévő újrapróbálkozása is idő előtt befejeződik, vagyis csak az 1-es érték került kibocsátásra, a 2-es nem
Amint látjuk, a retryWhen egyszerűen újrapróbálja a bemeneti Observable-t minden alkalommal, amikor a Notification Observable értéket bocsát ki!
Most, hogy megértettük, hogyan működik a retryWhen, nézzük meg, hogyan tudunk létrehozni egy Notification Observable-t.
Elkészíteni egy Notification Observable-t
A Notification Observable-t közvetlenül a retryWhen operátornak átadott függvényben kell létrehoznunk. Ez a függvény bemeneti argumentumként egy Errors Observable-t vesz fel, amely értékként kibocsátja a bemeneti Observable hibáit.
Azáltal, hogy feliratkozunk erre az Errors Observable-re, pontosan tudjuk, mikor történik hiba. Lássuk most, hogyan tudnánk megvalósítani egy azonnali újrapróbálkozási stratégiát az Errors Observable segítségével.
Immediate Retry Strategy
Hogy a hiba bekövetkezése után azonnal újrapróbáljuk a hibás Observable-t, csak annyit kell tennünk, hogy minden további változtatás nélkül visszaadjuk az Errors Observable-t. A hiba bekövetkezése után azonnal újrapróbálkozunk.
Ez esetben csak naplózási céllal pipáljuk a tap operátort, így az Errors Observable változatlan marad:
Ne feledjük, hogy az Observable, amit a retryWhen függvényhívásból visszaadunk, az a Notification Observable!
Az általa kibocsátott érték nem fontos, csak az a fontos, hogy mikor kerül kibocsátásra, mert ez fogja kiváltani az újbóli próbálkozást.
Immediate Retry Console Output
Ha most végrehajtjuk ezt a programot, a következő kimenetet fogjuk találni a konzolon:

Amint látjuk, a HTTP-kérés először sikertelen volt, de aztán megkíséreltünk egy újbóli próbálkozást, és másodszorra a kérés sikeresen átment.
Most nézzük meg a két próbálkozás közötti késedelmet a hálózati napló vizsgálatával:

Amint látjuk, a második próbálkozás a hiba bekövetkezte után azonnal megtörtént, ahogy az várható volt.
Késleltetett újrapróbálkozási stratégia
Végrehajtunk most egy alternatív hibaelhárítási stratégiát, ahol a hiba bekövetkezése után például 2 másodpercet várunk az újrapróbálkozással.
Ez a stratégia hasznos, ha bizonyos hibákból, például a nagy szerverforgalom okozta sikertelen hálózati kérésekből próbálunk helyreállni.
Azokban az esetekben, amikor a hiba időszakosan jelentkezik, rövid késleltetés után egyszerűen újrapróbálhatjuk ugyanazt a kérést, és előfordulhat, hogy a kérés másodszorra már gond nélkül átmegy.
A timer Observable létrehozási függvény
A késleltetett újratöltési stratégia megvalósításához létre kell hoznunk egy olyan Notification Observable-t, amelynek értékei minden egyes hiba előfordulása után két másodperccel kerülnek kibocsátásra.
Ezután próbáljunk meg létrehozni egy Notification Observable-t a timer létrehozási függvény segítségével. Ez az időzítő függvény néhány argumentumot fog elfogadni:
- egy kezdeti késleltetést, amely előtt nem fog értékeket kibocsátani
- egy periodikus intervallumot, arra az esetre, ha periodikusan szeretnénk új értékeket kibocsátani
Majd nézzük meg az időzítő függvény márványdiagramját:

Amint látjuk, az első 0 értéket csak 3 másodperc múlva bocsátjuk ki, és utána minden másodpercben kapunk egy új értéket.
Megjegyezzük, hogy a második argumentum opcionális, ami azt jelenti, hogy ha kihagyjuk, akkor az Observable-nk csak egy értéket (0) fog kibocsátani 3 másodperc után, majd befejeződik.
Ez az Observable jó kiindulópontnak tűnik ahhoz, hogy késleltetni tudjuk az újrapróbálkozási kísérleteinket, ezért nézzük meg, hogyan tudjuk kombinálni a retryWhen és delayWhen operátorokkal.
A delayWhen operátor
A retryWhen operátorral kapcsolatban fontos megjegyezni, hogy az Értesítés Observable-t definiáló függvényt csak egyszer hívjuk meg.
Ezért csak egyszer van lehetőségünk definiálni a Notification Observable-t, amely jelzi, hogy mikor kell megismételni a próbálkozásokat.
A Notification Observable-t úgy fogjuk definiálni, hogy vesszük az Errors Observable-t és alkalmazzuk rá a delayWhen operátort.
Képzeljük el, hogy ebben a márványdiagramban a forrás Observable a-b-c az Errors Observable, amely idővel sikertelen HTTP hibákat bocsát ki:

delayWhen Operator bontása
Követjük a diagramot, és tanuljuk meg, hogyan működik a delayWhen Operator:
- a bemeneti Errors Observable minden egyes értékét késleltetni fogjuk, mielőtt megjelenik a kimeneti Observable-ben
- a késleltetés minden egyes értékenként eltérő lehet, és teljesen rugalmasan fog létrejönni
- a késleltetés meghatározása érdekében, a delayWhen-nek átadott függvényt (az úgynevezett duration selector függvényt) a bemeneti Errors Observable
- minden egyes értéke után meg fogjuk hívni
- ez a függvény egy Observable-t fog kibocsátani, amely meghatározza, hogy mikor telt el az egyes bemeneti értékek késleltetése
- minden a-b-c értéknek saját duration selector Observable-je van, amely végül egy értéket fog kibocsátani (ez lehet bármi), majd befejezi
- mikor minden ilyen időtartam-választó Observable értéket bocsát ki, akkor a delayWhen
- megfigyeljük, hogy a
bérték acérték után jelenik meg a kimeneten, ez normális - ez azért van, mert a
bduration selector Observable (a harmadik vízszintes vonal felülről) csak acduration selector Observable után adta ki az értékét, és ez megmagyarázza, hogy acmiért jelenik meg a kimeneten ab
Késleltetett újratöltési stratégia megvalósítása
Vegyük most össze mindezt, és nézzük meg, hogyan tudjuk egymás után 2 másodperccel minden hiba bekövetkezése után újrapróbálni egy sikertelen HTTP kérést:
Bontjuk le, hogy mi történik itt:
- emlékezzünk arra, hogy a retryWhen-nek átadott függvényt csak egyszer fogjuk meghívni
- az adott függvényben egy Observable-t adunk vissza, amely értékeket fog kibocsátani, amikor újrapróbálkozásra van szükség
- minden alkalommal, amikor hiba lép fel, a delayWhen operátor létrehoz egy időtartam-választó Observable-t, az időzítő függvény meghívásával
- ez az időtartam-választó Observable 2 másodperc után 0 értéket fog kibocsátani, majd befejezi
- mihelyt ez megtörténik, a delayWhen Observable tudja, hogy egy adott bemeneti hiba késleltetése lejárt
- csak akkor, ha ez a késleltetés letelt (2 másodperccel a hiba bekövetkezése után), a hiba megjelenik a notification Observable kimenetén
- mihelyt egy értéket bocsát ki a notification Observable, a retryWhen operátor ekkor és csak ekkor hajt végre egy újbóli próbálkozást
Retry Strategy Console Output
Lássuk most, hogy néz ez ki a konzolon! Íme egy példa egy HTTP kérésre, amelyet 5 alkalommal próbáltak meg újra, mivel az első 4 alkalommal hiba történt:

És itt van ugyanennek az újrapróbálási sorozatnak a hálózati naplója:

Amint láthatjuk, az újrapróbálkozások csak 2 másodperccel a hiba bekövetkezése után történtek, ahogy az várható volt!
És ezzel befejeztük az idegenvezetést az elérhető leggyakrabban használt RxJs hibakezelési stratégiákról, most pedig csomagoljuk be a dolgokat, és adjunk néhány futó mintakódot.
Futó Github tároló (kódmintákkal)
Ezeknek a többféle hibakezelési stratégiáknak a kipróbálásához fontos, hogy legyen egy működő játszótér, ahol kipróbálhatjuk a hibás HTTP kérések kezelését.
Ez a játszótér egy kis futó alkalmazást tartalmaz egy backenddel, amellyel véletlenszerűen vagy szisztematikusan szimulálhatunk HTTP hibákat. Így néz ki az alkalmazás:

Következtetések
Amint láttuk, az RxJs hibakezelésének megértéséhez először az Observable szerződés alapjainak megértése szükséges.
Nem szabad elfelejtenünk, hogy egy adott folyam csak egyszer hibázhat, és ez a folyam befejezésével együtt kizárólagos; a két dolog közül csak az egyik történhet.
A hibából való felépüléshez az egyetlen lehetőség, hogy a hibásan kiesett folyam helyett valahogyan egy helyettesítő folyamot generálunk, mint ahogy ez a catchError vagy a retryWhen operátorok esetében történik.
Remélem, hogy tetszett ez a bejegyzés, ha még sokkal többet szeretnél megtudni az RxJs-ről, ajánljuk az RxJs In Practice Course kurzust, ahol sok hasznos mintát és operátort sokkal részletesebben tárgyalunk.