Azért, hogy megfelelő bevezetést adjunk a Gauss-kernelekbe, e heti bejegyzésünk a szokásosnál kicsit absztraktabb lesz. Ez az absztrakciós szint nem feltétlenül szükséges ahhoz, hogy megértsük, hogyan működnek a Gauss-kernelek, de az absztrakt szemlélet rendkívül hasznos lehet az intuíció forrásaként, amikor megpróbáljuk megérteni a valószínűségi eloszlásokat általában. Tehát a következő a helyzet: megpróbálom lassan felépíteni az absztrakciót, de ha egyszer reménytelenül eltévedsz, vagy egyszerűen nem bírod tovább, akkor ugorj le a “A gyakorlati rész” félkövér betűvel írt címsorhoz – ott átváltok a Gauss-kernel algoritmus konkrétabb leírására. Továbbá, ha még mindig gondjai vannak, ne aggódjon túlságosan – A blog későbbi bejegyzései közül a legtöbb nem fogja megkövetelni, hogy megértse a Gauss-kernelt, így nyugodtan megvárhatja a jövő heti bejegyzést (vagy átugorhatja azt, ha ezt később olvassa).
Emlékezzünk arra, hogy a kernel egy adattér egy magasabb dimenziós vektortérbe helyezésének egy módja, hogy az adattérnek a magasabb dimenziós térben lévő hipersíkokkal való metszéspontjai bonyolultabb, görbe döntési határokat határozzanak meg az adattérben. A fő példa, amit vizsgáltunk, az a kernel volt, amely egy kétdimenziós adattérből egy ötdimenziós térbe helyezi az egyes 


Ezen a héten a magasabb dimenziós vektortereken túl a végtelen dimenziós vektorterekbe megyünk. Láthatjuk, hogy a fenti kilencdimenziós kernel az ötdimenziós kernel kiterjesztése – lényegében csak a végére ragasztottunk még négy dimenziót. Ha ilyen módon egyre több dimenziót ragasztunk rá, egyre nagyobb és nagyobb dimenziójú kerneleket kapunk. Ha ezt “örökké” folytatnánk, akkor a végén végtelen sok dimenziót kapnánk. Vegyük észre, hogy ezt csak elvontan tudjuk megtenni. A számítógépek csak véges dolgokkal tudnak foglalkozni, így nem tudnak végtelen dimenziós vektorterekben számításokat tárolni és feldolgozni. De egy pillanatra tegyünk úgy, mintha megtehetnénk, csak hogy lássuk, mi történik. Aztán fordítsuk vissza a dolgokat a véges világba.
Ebben a feltételezett végtelen dimenziós vektortérben ugyanúgy összeadhatunk vektorokat, mint a hagyományos vektorok esetében, egyszerűen a megfelelő koordináták összeadásával. Ebben az esetben azonban végtelen számú koordinátát kell hozzáadnunk. Hasonlóképpen skalárokkal is szorozhatunk úgy, hogy minden (végtelen sok) koordinátát megszorozunk egy adott számmal. A végtelen polinommagot úgy határozzuk meg, hogy minden egyes 

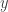


Hogy visszatérjünk a számítási világba, az eredeti ötdimenziós kernelünket úgy nyerhetjük vissza, hogy az első öt bejegyzés kivételével egyszerűen elfelejtjük az összeset. Valójában az eredeti ötdimenziós teret tartalmazza ez a végtelen dimenziós tér. (Az eredeti ötdimenziós kernel az, amit akkor kapunk, ha a végtelen polinomiális kernelt kivetítjük erre az ötdimenziós térre.)
Most vegyünk egy mély lélegzetet, mert most egy lépéssel tovább megyünk. Gondoljuk végig egy pillanatra, hogy mi is az a vektor. Ha valaha vettél részt matematikai lineáris algebra órán, talán emlékszel, hogy a vektorokat hivatalosan az összeadási és szorzási tulajdonságaik alapján definiálják. De ezt most átmenetileg figyelmen kívül hagyom (elnézést kérek minden matematikustól, aki ezt olvassa.) A számítástechnika világában általában úgy gondolunk a vektorra, mint számok listájára. Ha eddig elolvastad, akkor talán hajlandó vagy megengedni, hogy ez a lista végtelen legyen. Én azonban azt szeretném, ha úgy gondolnátok a vektorra, mint számok gyűjteményére, amelyben minden egyes szám egy adott dologhoz van rendelve. Például a szokásos vektortípusunkban minden egyes számot az egyik koordinátához/tulajdonsághoz rendelünk. Az egyik végtelen vektorunkban minden számot a végtelen hosszú listánk egy pontjához rendelünk.
De mit szólsz ehhez: Mi történne, ha úgy definiálnánk egy vektort, hogy a (véges dimenziós) adattérünk minden egyes pontjához hozzárendelünk egy számot? Egy ilyen vektor nem az adattér egyetlen pontját választja ki, hanem ha egyszer kiválasztjuk ezt a vektort, ha az adattér bármelyik pontjára mutatunk, a vektor egy számot mond. Nos, tulajdonképpen erre már van is egy nevünk: Valami, ami az adattér minden egyes pontjához egy számot rendel, az egy függvény. Valójában ezen a blogon már sokat foglalkoztunk függvényekkel, a valószínűségi eloszlásokat definiáló sűrűségfüggvények formájában. De a lényeg az, hogy ezeket a sűrűségfüggvényeket vektoroknak tekinthetjük egy végtelen dimenziós vektortérben.
Hogyan lehet egy függvény vektor? Nos, összeadhatunk két függvényt úgy, hogy egyszerűen összeadjuk az értékeiket az egyes pontokban. Ez volt az első séma, amelyet az eloszlások kombinálására tárgyaltunk a múlt heti, keverékmodellekről szóló bejegyzésben. Két vektor (Gauss-folt) sűrűségfüggvénye és az összeadásuk eredménye az alábbi ábrán látható. Hasonló módon megszorozhatunk egy függvényt egy számmal, aminek eredményeképpen a teljes sűrűség világosabbá vagy sötétebbé válik. Valójában mindkettő olyan művelet, amelyekkel valószínűleg sok gyakorlatot szereztél az algebraórán és a számtanórán. Tehát még nem csinálunk semmi újat, csak másképp gondolkodunk a dolgokról.

A következő lépés az, hogy az eredeti adattérből egy kernelt definiálunk ebbe a végtelen dimenziós térbe, és itt rengeteg lehetőségünk van. Az egyik leggyakoribb választás a Gauss-féle blobfüggvény, amellyel már többször találkoztunk korábbi bejegyzésekben. Ehhez a kernelhez a Gauss-féle pacák standard méretét választjuk, azaz az eltérés fix értékét 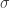
Most, itt van a probléma: Ahhoz, hogy a dolgokat visszavigyük a számítási világba, ki kell választanunk egy véges dimenziós vektortérből, amely ebben a végtelen dimenziós vektortérben ül, és a végtelen dimenziós teret “kivetíteni” a véges dimenziós altérbe. A véges dimenziós teret úgy választjuk ki, hogy kiválasztunk az adattérben egy (véges) számú pontot, majd vesszük azt a vektortérséget, amelyet az e pontok középpontjában lévő Gauss-foltok átfognak. Ez egyenértékű a végtelen polinommag első öt koordinátája által meghatározott vektortérrel, mint fentebb. Ezeknek a pontoknak a kiválasztása fontos, de erre később még visszatérünk. Egyelőre az a kérdés, hogyan vetítünk?
Véges dimenziós vektorok esetében a vetítés meghatározásának legáltalánosabb módja a pontszorzat használata: Ez az a szám, amelyet két vektor megfelelő koordinátáinak szorzásából, majd összeadásából kapunk. Így például a 


Hasonlót tehetünk a függvényekkel is, ha az adathalmaz megfelelő pontjaira felvett értékeket szorozzuk. (Más szóval, összeszorozzuk a két függvényt.) De akkor nem adhatjuk össze ezeket a számokat, mert végtelen sok van belőlük. Ehelyett egy integrált fogunk venni! (Megjegyzem, hogy itt rengeteg részletet elhallgatok, és még egyszer elnézést kérek minden matematikustól, aki ezt olvassa.) A szép dolog itt az, hogy ha két Gauss-függvényt megszorozunk és integrálunk, akkor a szám egyenlő a középpontok közötti távolság Gauss-függvényével. (Bár az új Gauss-függvénynek más lesz az eltérés értéke.)
Más szóval a Gauss-mag a végtelen dimenziós térben a pontszorzatot az adattérben lévő pontok közötti távolság Gauss-függvényévé alakítja: Ha az adattér két pontja közel van egymáshoz, akkor az őket a kerneltérben reprezentáló vektorok közötti szög kicsi lesz. Ha a pontok távol vannak egymástól, akkor a megfelelő vektorok közel “merőlegesek” lesznek.”
A gyakorlati rész
Nézzük tehát át az eddigieket: Egy 
Hogy jobban megértsük, hogyan működik ez a kernel, találjuk ki, hogyan néz ki egy hipersík és az adattér metszéspontja. (A legtöbbször egyébként is ezt tesszük a kernelekkel.) Emlékezzünk vissza, hogy egy síkot egy 


Ezt még mindig elég nehéz kibogozni, ezért nézzünk egy példát, ahol az 

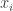





Ha a
Ez tehát nagyobb rugalmasságot ad a döntési határ megválasztásában (vagy legalábbis másfajta rugalmasságot), de a végeredmény nagyban függ az általunk választott
A pontok ilyen gyűjteményének megtalálása egy teljesen más probléma, mint amire a blog eddigi bejegyzéseiben összpontosítottunk, és a felügyelet nélküli tanulás/leíró analitika kategóriájába tartozik. (A kernelek kontextusában feature selection/engineering néven is elképzelhető). A következő néhány bejegyzésben sebességet váltunk, és elkezdjük megvizsgálni az ilyen irányú ötleteket.