La gestion des erreurs est une partie essentielle de RxJs, car nous en aurons besoin dans à peu près tous les programmes réactifs que nous écrivons.
La gestion des erreurs dans RxJS n’est probablement pas aussi bien comprise que d’autres parties de la bibliothèque, mais elle est en fait assez simple à comprendre si nous nous concentrons sur la compréhension d’abord du contrat Observable en général.
Dans ce post, nous allons fournir un guide complet contenant les stratégies de gestion des erreurs les plus courantes dont vous aurez besoin pour couvrir la plupart des scénarios pratiques, en commençant par les bases (le contrat Observable).
- Table des matières
- Le contrat Observable et la gestion des erreurs
- RxJs subscribe et error callbacks
- Exemple de comportement d’achèvement
- Limitations du gestionnaire d’erreur subscribe
- L’opérateur catchError
- Comment fonctionne catchError ?
- Que se passe-t-il lorsqu’une erreur est lancée ?
- La stratégie catch and replace
- La stratégie Catch and Rethrow
- Décomposition de Catch and Rethrow
- Utilisation de catchError plusieurs fois dans une chaîne Observable
- L’opérateur finalize
- Exemple de l’opérateur finalize
- La stratégie de réessai
- Quand réessayer ?
- Diagramme en marbre de l’opérateur retryWhen de RxJs
- Décomposer comment retryWhen fonctionne
- Créer un Observable de Notification
- Stratégie de relance immédiate
- Sortie de console de relance immédiate
- Stratégie de réessai retardé
- La fonction de création d’Observable timer
- L’opérateur delayWhen
- décomposition de l’opérateur delayWhen
- Mise en œuvre de la stratégie de relance retardée
- Sortie de console de la stratégie de relance
- Dépôt Github en cours d’exécution (avec des échantillons de code)
- Conclusions
Table des matières
Dans ce post, nous allons couvrir les sujets suivants :
- Le contrat Observable et la gestion des erreurs
- RxJs subscribe et error callbacks
- L’opérateur catchError
- La stratégie Catch and Replace. Stratégie
- throwError et la stratégie Catch and Rethrow
- Utilisation de catchError plusieurs fois dans une chaîne Observable
- L’opérateur finalize
- La stratégie Retry. Strategy
- Then retryWhen Opérateur
- Création d’un Observable de notification
- Stratégie de relance immédiate
- Stratégie de relance retardée
- The delayWhen Operator
- La fonction de création d’Observable timer
- Running Github repository (avec des échantillons de code)
- Conclusions
Donc sans plus attendre, commençons notre plongée profonde dans la gestion des erreurs de RxJs !
Le contrat Observable et la gestion des erreurs
Pour comprendre la gestion des erreurs dans RxJs, nous devons d’abord comprendre que tout flux donné ne peut se tromper qu’une seule fois. Ceci est défini par le contrat Observable, qui dit qu’un flux peut émettre zéro ou plusieurs valeurs.
Le contrat fonctionne ainsi parce que c’est exactement la façon dont tous les flux que nous observons dans notre runtime fonctionnent en pratique. Les requêtes réseau peuvent échouer, par exemple.
Un flux peut également s’achever, ce qui signifie que :
- le flux a terminé son cycle de vie sans aucune erreur
- après l’achèvement, le flux n’émettra plus de valeurs
Au lieu de l’achèvement, un flux peut également se tromper, ce qui signifie que :
- le flux a terminé son cycle de vie avec une erreur
- après la levée de l’erreur, le flux n’émettra pas d’autres valeurs
Notez que l’achèvement ou l’erreur sont mutuellement exclusifs :
- si le flux se complète, il ne peut pas se tromper ensuite
- si le flux se trompe, il ne peut pas se compléter ensuite
Notez également qu’il n’y a aucune obligation pour le flux de se compléter ou de se tromper, ces deux possibilités sont facultatives. Mais seule l’une de ces deux possibilités peut se produire, pas les deux.
Cela signifie que lorsqu’un flux particulier se trompe, nous ne pouvons plus l’utiliser, selon le contrat Observable. Vous devez penser à ce stade, comment pouvons-nous récupérer d’une erreur alors ?
RxJs subscribe et error callbacks
Pour voir le comportement de gestion des erreurs de RxJs en action, créons un flux et abonnons-nous à lui. Rappelons que l’appel subscribe prend trois arguments optionnels :
- une fonction de gestion de succès, qui est appelée chaque fois que le flux émet une valeur
- une fonction de gestion d’erreur, qui est appelée uniquement si une erreur se produit. Ce gestionnaire reçoit lui-même l’erreur
- une fonction de gestionnaire d’achèvement, qui n’est appelée que si le flux se termine
Exemple de comportement d’achèvement
Si le flux n’émet pas d’erreur, alors voici ce que nous verrions dans la console:
HTTP response {payload: Array(9)}HTTP request completed.Comme nous pouvons le voir, ce flux HTTP n’émet qu’une seule valeur, puis il se termine, ce qui signifie qu’aucune erreur ne s’est produite.
Mais que se passe-t-il si le flux lance une erreur à la place ? Dans ce cas, nous verrons ce qui suit dans la console à la place:

Comme nous pouvons le voir, le flux n’a émis aucune valeur et il a immédiatement erré. Après l’erreur, aucun achèvement ne s’est produit.
Limitations du gestionnaire d’erreur subscribe
Gérer les erreurs en utilisant l’appel subscribe est parfois tout ce dont nous avons besoin, mais cette approche de gestion des erreurs est limitée. En utilisant cette approche, nous ne pouvons pas, par exemple, récupérer de l’erreur ou émettre une valeur de repli alternative qui remplace la valeur que nous attendions du backend.
Apprenons ensuite quelques opérateurs qui nous permettront de mettre en œuvre des stratégies de gestion des erreurs plus avancées.
L’opérateur catchError
Dans la programmation synchrone, nous avons la possibilité d’envelopper un bloc de code dans une clause try, d’attraper toute erreur qu’il pourrait lancer avec un bloc catch et ensuite de gérer l’erreur.
Voici à quoi ressemble la syntaxe catch synchrone :
Ce mécanisme est très puissant car nous pouvons gérer en un seul endroit toute erreur qui se produit à l’intérieur du bloc try/catch.
Le problème est qu’en Javascript, de nombreuses opérations sont asynchrones, et un appel HTTP est un de ces exemples où les choses se passent de manière asynchrone.
RxJs nous fournit quelque chose de proche de cette fonctionnalité, via l’opérateur catchError de RxJs.
Comment fonctionne catchError ?
Comme d’habitude et comme avec tout opérateur de RxJs, catchError est simplement une fonction qui prend en entrée un Observable, et sort un Observable de sortie.
A chaque appel à catchError, nous devons lui passer une fonction que nous appellerons la fonction de gestion des erreurs.
L’opérateur catchError prend en entrée un Observable qui pourrait se tromper, et commence à émettre les valeurs de l’Observable d’entrée dans son Observable de sortie.
Si aucune erreur ne se produit, l’Observable de sortie produit par catchError fonctionne exactement de la même manière que l’Observable d’entrée.
Que se passe-t-il lorsqu’une erreur est lancée ?
Cependant, si une erreur se produit, alors la logique de catchError va entrer en jeu. L’opérateur catchError va prendre l’erreur et la passer à la fonction de gestion des erreurs.
Cette fonction est censée retourner un Observable qui va être un Observable de remplacement pour le flux qui vient d’avoir une erreur.
Souvenons-nous que le flux d’entrée de catchError s’est érodé, donc selon le contrat Observable, nous ne pouvons plus l’utiliser.
Cet Observable de remplacement va alors être souscrit et ses valeurs vont être utilisées à la place de l’Observable d’entrée érodé.
La stratégie catch and replace
Donnons un exemple de la façon dont catchError peut être utilisé pour fournir un Observable de remplacement qui émet des valeurs de repli :
Décomposons l’implémentation de la stratégie catch and replace :
- nous passons à l’opérateur catchError une fonction, qui est la fonction de gestion des erreurs
- la fonction de gestion des erreurs n’est pas appelée immédiatement, et en général, elle n’est pas appelée
- uniquement lorsqu’une erreur se produit dans l’Observable d’entrée de catchError, la fonction de gestion des erreurs sera appelée
- si une erreur se produit dans le flux d’entrée, cette fonction renvoie alors un Observable construit à l’aide de la fonction
of() - la fonction
of()construit un Observable qui n’émet qu’une seule valeur () puis elle se termine - la fonction de gestion des erreurs renvoie l’Observable de récupération (
of()), qui est souscrit par l’opérateur catchError - les valeurs de l’Observable de récupération sont alors émises comme valeurs de remplacement dans l’Observable de sortie retourné par catchError
Comme résultat final, l’Observable http$ n’aura plus d’erreur ! Voici le résultat que nous obtenons dans la console:
HTTP response HTTP request completed.Comme nous pouvons le voir, le callback de gestion des erreurs dans subscribe() n’est plus invoqué. Au lieu de cela, voici ce qui se passe:
- la valeur vide du tableau
est émise - l’Observable
http$est ensuite complété
Comme nous pouvons le voir, l’Observable de remplacement a été utilisé pour fournir une valeur de repli par défaut () aux abonnés de http$, malgré le fait que l’Observable original ait fait une erreur.
Notez que nous aurions également pu ajouter une gestion locale des erreurs, avant de retourner l’Observable de remplacement !
Et ceci couvre la stratégie Catch and Replace, voyons maintenant comment nous pouvons aussi utiliser catchError pour relancer l’erreur, au lieu de fournir des valeurs de repli.
La stratégie Catch and Rethrow
Commençons par remarquer que l’Observable de remplacement fourni via catchError peut lui-même aussi se tromper, comme tout autre Observable.
Et si cela se produit, l’erreur sera propagée aux abonnés de l’Observable de sortie de catchError.
Ce comportement de propagation d’erreur nous donne un mécanisme pour relancer l’erreur capturée par catchError, après avoir traité l’erreur localement. Nous pouvons le faire de la manière suivante :
Décomposition de Catch and Rethrow
Décomposons étape par étape la mise en œuvre de la stratégie Catch and Rethrow :
- comme avant, nous attrapons l’erreur, et retournons un Observable
- mais cette fois-ci, au lieu de fournir une valeur de sortie de remplacement comme
, nous traitons maintenant l’erreur localement dans la fonction catchError - dans ce cas, nous enregistrons simplement l’erreur dans la console, mais nous pourrions plutôt ajouter toute logique de gestion d’erreur locale que nous voulons, comme par exemple montrer un message d’erreur à l’utilisateur
- Nous retournons ensuite un Observable de remplacement qui, cette fois, a été créé en utilisant throwError
- throwError crée un Observable qui n’émet jamais aucune valeur. Au lieu de cela, il se trompe immédiatement en utilisant la même erreur capturée par catchError
- cela signifie que l’Observable de sortie de catchError se trompera également avec exactement la même erreur lancée par l’entrée de catchError
- cela signifie que nous avons réussi à relancer l’erreur initialement lancée par l’Observable d’entrée de catchError vers son Observable de sortie
- l’erreur peut maintenant être traitée plus avant par le reste de la chaîne d’Observables, si nécessaire
Si nous exécutons maintenant le code ci-dessus, voici le résultat que nous obtenons dans la console :

Comme nous pouvons le voir, la même erreur a été enregistrée à la fois dans le bloc catchError et dans la fonction de gestion des erreurs d’abonnement, comme prévu.
Utilisation de catchError plusieurs fois dans une chaîne Observable
Notez que nous pouvons utiliser catchError plusieurs fois à différents points de la chaîne Observable si nécessaire, et adopter différentes stratégies d’erreur à chaque point de la chaîne.
Nous pouvons, par exemple, attraper une erreur en haut de la chaîne Observable, la traiter localement et la relancer, puis plus bas dans la chaîne Observable, nous pouvons attraper la même erreur à nouveau et cette fois fournir une valeur de repli (au lieu de la relancer) :
Si nous exécutons le code ci-dessus, voici la sortie que nous obtenons dans la console:
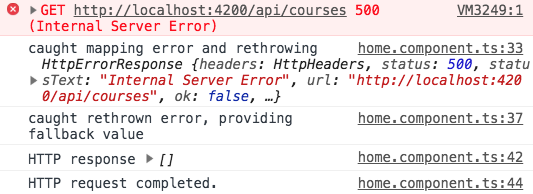
Comme nous pouvons le voir, l’erreur a effectivement été relancée initialement, mais elle n’a jamais atteint la fonction de traitement d’erreur de souscription. Au lieu de cela, la valeur de repli a été émise, comme prévu.
L’opérateur finalize
En plus d’un bloc catch pour gérer les erreurs, la syntaxe Javascript synchrone fournit également un bloc finally qui peut être utilisé pour exécuter du code que nous voulons toujours exécuter.
Le bloc finally est généralement utilisé pour libérer des ressources coûteuses, comme par exemple la fermeture des connexions réseau ou la libération de la mémoire.
À la différence du code dans le bloc catch, le code dans le bloc finally sera exécuté indépendamment si une erreur est lancée ou non :
RxJs nous fournit un opérateur qui a un comportement similaire à la fonctionnalité finally, appelé l’opérateur finalize.
Note : nous ne pouvons pas l’appeler l’opérateur finally à la place, car finally est un mot-clé réservé en Javascript
Exemple de l’opérateur finalize
Comme l’opérateur catchError, nous pouvons ajouter plusieurs appels finalize à différents endroits de la chaîne Observable si nécessaire, afin de nous assurer que les multiples ressources sont correctement libérées :
Exécutons maintenant ce code, et voyons comment les multiples blocs finalize sont exécutés :

Notez que le dernier bloc finalize est exécuté après les fonctions subscribe value handler et completion handler.
La stratégie de réessai
Au lieu de relancer l’erreur ou de fournir des valeurs de repli, nous pouvons aussi simplement réessayer de nous abonner à l’Observable qui a fait l’objet de l’erreur.
Souvenons-nous, une fois que le flux fait l’objet d’une erreur, nous ne pouvons pas le récupérer, mais rien ne nous empêche de nous abonner à nouveau à l’Observable dont le flux a été dérivé, et de créer un autre flux.
Voici comment cela fonctionne :
- nous allons prendre l’Observable d’entrée, et nous y abonner, ce qui crée un nouveau flux
- si ce flux ne se trompe pas, nous allons laisser ses valeurs apparaître dans la sortie
- mais si le flux se trompe, nous allons alors nous abonner à nouveau à l’Observable d’entrée, et créer un tout nouveau flux
Quand réessayer ?
La grande question ici est, quand allons-nous nous abonner à nouveau à l’Observable d’entrée, et réessayer d’exécuter le flux d’entrée ?
- allons-nous réessayer cela immédiatement ?
- allons-nous attendre un petit délai, en espérant que le problème soit résolu, puis réessayer ?
- allons-nous réessayer seulement un nombre limité de fois, et ensuite faire une erreur sur le flux de sortie ?
Pour répondre à ces questions, nous allons avoir besoin d’un deuxième Observable auxiliaire, que nous allons appeler l’Observable Notifier. C’est le Notifier
Observable qui va déterminer quand la tentative de relance se produit.
L’Observable Notifier va être utilisé par l’Opérateur retryWhen, qui est le cœur de la stratégie de relance.
Diagramme en marbre de l’opérateur retryWhen de RxJs
Pour comprendre le fonctionnement de l’Observable retryWhen, regardons son diagramme en marbre :

Notez que l’Observable qui est retenté est l’Observable 1-2 de la deuxième ligne en partant du haut, et non l’Observable de la première ligne.
L’Observable sur la première ligne avec les valeurs r-r est l’Observable de notification, qui va déterminer quand une tentative de réessai doit se produire.
Décomposer comment retryWhen fonctionne
Décomposons ce qui se passe dans ce diagramme :
- L’Observable 1-2 se fait souscrire, et ses valeurs sont reflétées immédiatement dans l’Observable de sortie renvoyé par retryQuand
- même après que l’Observable 1-2 soit terminé, il peut encore être retenté
- l’Observable de notification émet alors une valeur
r, bien après que l’Observable 1-2 se soit terminé - La valeur émise par l’Observable de notification (dans ce cas
r) pourrait être n’importe quoi - ce qui compte c’est le moment où la valeur
ra été émise, parce que c’est ce qui va déclencher l’Observable 1-2 pour être réessayé - l’Observable 1-2 est à nouveau souscrit par retryWhen, et ses valeurs sont à nouveau reflétées dans l’Observable de sortie de retryWhen
- L’Observable de notification va alors émettre à nouveau une autre valeur
r, et la même chose se produit : les valeurs d’un flux 1-2 nouvellement souscrit vont commencer à se refléter dans la sortie de retryWhen - mais ensuite, l’Observable de notification finit par se terminer
- à ce moment, la tentative de réessai en cours de l’Observable 1-2 se termine également de manière anticipée, ce qui signifie que seule la valeur 1 a été émise, mais pas 2
Comme nous pouvons le voir, retryWhen réessaie simplement l’Observable d’entrée chaque fois que l’Observable de notification émet une valeur !
Maintenant que nous comprenons comment retryWhen fonctionne, voyons comment nous pouvons créer un Observable de Notification.
Créer un Observable de Notification
Nous devons créer l’Observable de Notification directement dans la fonction passée à l’opérateur retryWhen. Cette fonction prend comme argument d’entrée un Observable d’erreurs, qui émet comme valeurs les erreurs de l’Observable d’entrée.
Ainsi, en souscrivant à cet Observable d’erreurs, nous savons exactement quand une erreur se produit. Voyons maintenant comment nous pourrions mettre en œuvre une stratégie de relance immédiate en utilisant l’Observable Erreurs.
Stratégie de relance immédiate
Pour relancer l’observable en échec immédiatement après l’apparition de l’erreur, il suffit de renvoyer l’Observable Erreurs sans autre modification.
Dans ce cas, nous ne faisons que pipeter l’opérateur tap à des fins de journalisation, donc l’Observable Erreurs reste inchangé :
N’oublions pas que l’Observable que nous retournons à partir de l’appel de fonction retryWhen est l’Observable Notification !
La valeur qu’il émet n’est pas importante, c’est seulement important quand la valeur est émise car c’est ce qui va déclencher une tentative de réessai.
Sortie de console de relance immédiate
Si nous exécutons maintenant ce programme, nous allons trouver la sortie suivante dans la console :

Comme nous pouvons le voir, la requête HTTP a échoué initialement, mais ensuite une relance a été tentée et la deuxième fois la requête est passée avec succès.
Regardons maintenant le délai entre les deux tentatives, en inspectant le journal du réseau :

Comme nous pouvons le voir, la deuxième tentative a été émise immédiatement après l’erreur, comme prévu.
Stratégie de réessai retardé
Mettons maintenant en œuvre une stratégie alternative de récupération d’erreur, où nous attendons par exemple 2 secondes après que l’erreur se soit produite, avant de réessayer.
Cette stratégie est utile pour essayer de récupérer de certaines erreurs comme par exemple des requêtes réseau échouées causées par un trafic serveur élevé.
Dans les cas où l’erreur est intermittente, on peut simplement réessayer la même demande après un court délai, et la demande pourrait passer la deuxième fois sans problème.
La fonction de création d’Observable timer
Pour mettre en œuvre la stratégie de relance retardée, nous devrons créer un Observable de notification dont les valeurs sont émises deux secondes après chaque occurrence d’erreur.
Tentons alors de créer un Observable de notification en utilisant la fonction de création timer. Cette fonction timer va prendre quelques arguments :
- un délai initial, avant lequel aucune valeur ne sera émise
- un intervalle périodique, au cas où nous voudrions émettre de nouvelles valeurs périodiquement
Passons ensuite en revue le diagramme de marbre de la fonction timer :

Comme nous pouvons le voir, la première valeur 0 ne sera émise qu’après 3 secondes, et ensuite nous avons une nouvelle valeur chaque seconde.
Notez que le deuxième argument est optionnel, ce qui signifie que si nous l’omettons, notre Observable ne va émettre qu’une seule valeur (0) au bout de 3 secondes et ensuite se terminer.
Cet Observable semble être un bon début pour pouvoir retarder nos tentatives de réessai, alors voyons comment nous pouvons le combiner avec les opérateurs retryWhen et delayWhen.
L’opérateur delayWhen
Une chose importante à garder à l’esprit concernant l’opérateur retryWhen, c’est que la fonction qui définit l’Observable de notification n’est appelée qu’une seule fois.
Donc nous n’avons qu’une seule chance de définir notre Observable de Notification, qui signale quand les tentatives de réessai doivent être faites.
Nous allons définir l’Observable de Notification en prenant l’Observable d’Erreurs et en lui appliquant l’Opérateur delayWhen.
Imaginez que dans ce diagramme de marbre, l’Observable source a-b-c est l’Observable Errors, qui émet des erreurs HTTP échouées au fil du temps :

décomposition de l’opérateur delayWhen
Suivons le diagramme, et apprenons comment fonctionne l’opérateur delayWhen :
- chaque valeur de l’Observable des erreurs en entrée va être retardée avant d’apparaître dans l’Observable en sortie
- le retard par chaque valeur peut être différent, et va être créé de manière complètement flexible
- afin de déterminer le retard, nous allons appeler la fonction passée à delayWhen (appelée la fonction de sélection de durée) par chaque valeur de l’entrée Erreurs Observable
- cette fonction va émettre un Observable qui va déterminer quand le délai de chaque valeur d’entrée s’est écoulé
- chacune des valeurs a-b-c a son propre Observable de sélection de durée, qui va éventuellement émettre une valeur (qui peut être n’importe quoi) puis se terminer
- lorsque chacun de ces Observables sélecteurs de durée émet des valeurs, alors la valeur d’entrée correspondante a-b-c va apparaître dans la sortie de delayWhen
- notez que la valeur
bapparaît dans la sortie après la valeurc, c’est normal - c’est parce que l’Observable sélecteur de durée
b(la troisième ligne horizontale en partant du haut) n’a émis sa valeur qu’après l’Observable sélecteur de durée dec, et cela explique pourquoicapparaît dans la sortie avantb
Mise en œuvre de la stratégie de relance retardée
Mettons maintenant tout cela ensemble et voyons comment nous pouvons relancer consécutivement une requête HTTP en échec 2 secondes après que chaque erreur se soit produite :
Décomposons ce qui se passe ici :
- nous rappelons que la fonction passée à retryWhen ne sera appelée qu’une seule fois
- nous retournons dans cette fonction un Observable qui émettra des valeurs chaque fois qu’une réessai sera nécessaire
- à chaque fois qu’il y aura une erreur, l’opérateur delayWhen va créer un Observable sélecteur de durée, en appelant la fonction timer
- cette Observable sélecteur de durée va émettre la valeur 0 au bout de 2 secondes, puis se terminer
- une fois que cela se produit, l’Observable delayWhen sait que le délai d’une erreur d’entrée donnée s’est écoulé
- une fois seulement que ce délai est écoulé (2 secondes après que l’erreur se soit produite), l’erreur apparaît dans la sortie de l’Observable de notification
- une fois qu’une valeur est émise dans l’Observable de notification, l’opérateur retryWhen va alors et seulement alors exécuter une tentative de relance
Sortie de console de la stratégie de relance
Voyons maintenant à quoi cela ressemble dans la console ! Voici un exemple d’une requête HTTP qui a été retentée 5 fois, car les 4 premières fois étaient en erreur:

Et voici le journal du réseau pour la même séquence de tentatives:

Comme nous pouvons le voir, les tentatives ne se sont produites que 2 secondes après l’erreur, comme prévu !
Et avec cela, nous avons terminé notre visite guidée de certaines des stratégies de gestion des erreurs RxJs les plus couramment utilisées disponibles, terminons maintenant les choses et fournissons quelques exemples de code en cours d’exécution.
Dépôt Github en cours d’exécution (avec des échantillons de code)
Afin d’essayer ces multiples stratégies de gestion des erreurs, il est important d’avoir un terrain de jeu fonctionnel où vous pouvez essayer de gérer les requêtes HTTP en échec.
Ce terrain de jeu contient une petite application en cours d’exécution avec un backend qui peut être utilisé pour simuler des erreurs HTTP de manière aléatoire ou systématique. Voici à quoi ressemble l’application:

Conclusions
Comme nous l’avons vu, comprendre la gestion des erreurs RxJs consiste à comprendre d’abord les principes fondamentaux du contrat Observable.
Nous devons garder à l’esprit qu’un flux donné ne peut se tromper qu’une seule fois, et c’est exclusif avec l’achèvement du flux ; une seule des deux choses peut se produire.
Pour récupérer d’une erreur, la seule façon est de générer d’une manière ou d’une autre un flux de remplacement comme alternative au flux erroné, comme cela se produit dans le cas des opérateurs catchError ou retryWhen.
J’espère que vous avez apprécié ce post, si vous souhaitez en apprendre beaucoup plus sur RxJs, nous vous recommandons de consulter le cours RxJs In Practice Course, où beaucoup de patterns et d’opérateurs utiles sont couverts de manière beaucoup plus détaillée.