Afin de donner une introduction appropriée aux noyaux gaussiens, le post de cette semaine va commencer un peu plus abstrait que d’habitude. Ce niveau d’abstraction n’est pas strictement nécessaire pour comprendre le fonctionnement des noyaux gaussiens, mais la perspective abstraite peut être extrêmement utile comme source d’intuition lorsqu’on essaie de comprendre les distributions de probabilité en général. Voici donc ce que je propose : j’essaierai de développer lentement l’abstraction, mais si jamais vous êtes désespérément perdu, ou si vous n’en pouvez plus, vous pouvez passer directement au titre « La partie pratique » en gras – c’est là que je passerai à une description plus concrète de l’algorithme du noyau gaussien. En outre, si vous avez toujours des difficultés, ne vous inquiétez pas trop – La plupart des articles ultérieurs sur ce blog ne nécessiteront pas que vous compreniez les noyaux gaussiens, donc vous pouvez simplement attendre l’article de la semaine prochaine (ou passer à celui-ci si vous lisez ceci plus tard).
Rappellez-vous qu’un noyau est un moyen de placer un espace de données dans un espace vectoriel de dimension supérieure de sorte que les intersections de l’espace de données avec les hyperplans dans l’espace de dimension supérieure déterminent des frontières de décision plus compliquées et courbes dans l’espace de données. Le principal exemple que nous avons examiné est le noyau qui envoie un espace de données bidimensionnel vers un espace à cinq dimensions en envoyant chaque point de coordonnées 


Cette semaine, nous allons dépasser les espaces vectoriels de dimension supérieure pour aller vers des espaces vectoriels de dimension infinie. Vous pouvez voir comment le noyau à neuf dimensions ci-dessus est une extension du noyau à cinq dimensions – nous avons essentiellement juste plaqué quatre dimensions supplémentaires à la fin. Si nous continuons à ajouter des dimensions de cette manière, nous obtiendrons des noyaux de dimension de plus en plus élevée. Si nous devions continuer à faire cela « pour toujours », nous finirions par avoir une infinité de dimensions. Notez que nous ne pouvons faire cela que dans l’abstrait. Les ordinateurs ne peuvent traiter que des choses finies, ils ne peuvent donc pas stocker et traiter des calculs dans des espaces vectoriels de dimension infinie. Mais nous allons faire comme si c’était le cas pendant une minute, juste pour voir ce qui se passe. Ensuite, nous traduirons les choses dans le monde fini.
Dans cet hypothétique espace vectoriel à dimension infinie, nous pouvons ajouter des vecteurs de la même manière que nous le faisons avec des vecteurs réguliers, en ajoutant simplement les coordonnées correspondantes. Cependant, dans ce cas, nous devons ajouter une infinité de coordonnées. De même, nous pouvons multiplier par des scalaires, en multipliant chacune des coordonnées (infiniment nombreuses) par un nombre donné. Nous allons définir le noyau polynomial infini en envoyant chaque point 

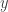


Pour revenir au monde computationnel, nous pouvons récupérer notre noyau original à cinq dimensions en oubliant simplement toutes les entrées sauf les cinq premières. En fait, l’espace original à cinq dimensions est contenu dans cet espace à dimension infinie. (Le noyau original à cinq dimensions est ce que nous obtenons en projetant le noyau polynomial infini dans cet espace à cinq dimensions.)
Maintenant, respirez profondément, car nous allons aller plus loin. Considérez, pour un moment, ce qu’est un vecteur. Si vous avez déjà suivi un cours d’algèbre linéaire mathématique, vous vous souvenez peut-être que les vecteurs sont officiellement définis en fonction de leurs propriétés d’addition et de multiplication. Mais je vais temporairement ignorer cela (avec mes excuses aux mathématiciens qui lisent ces lignes). Dans le monde de l’informatique, nous considérons généralement qu’un vecteur est une liste de nombres. Si vous avez lu jusqu’ici, vous êtes peut-être prêt à laisser cette liste être infinie. Mais je veux que vous considériez un vecteur comme une collection de nombres dans laquelle chaque nombre est affecté à une chose particulière. Par exemple, dans notre type habituel de vecteur, chaque nombre est affecté à l’une des coordonnées/caractéristiques. Dans l’un de nos vecteurs infinis, chaque nombre est affecté à une place dans notre liste infiniment longue.
Mais que dire de ceci : Que se passerait-il si nous définissions un vecteur en attribuant un numéro à chaque point de notre espace de données (de dimension finie) ? Un tel vecteur ne choisit pas un seul point dans l’espace de données ; plutôt, une fois que vous choisissez ce vecteur, si vous pointez vers n’importe quel point dans l’espace de données, le vecteur vous indique un nombre. En fait, nous avons déjà un nom pour cela : Quelque chose qui attribue un nombre à chaque point de l’espace de données est une fonction. En fait, nous avons beaucoup étudié les fonctions sur ce blog, sous la forme de fonctions de densité qui définissent les distributions de probabilité. Mais le fait est que nous pouvons considérer ces fonctions de densité comme des vecteurs dans un espace vectoriel de dimension infinie.
Comment une fonction peut-elle être un vecteur ? Eh bien, nous pouvons additionner deux fonctions en ajoutant simplement leurs valeurs à chaque point. C’est le premier schéma que nous avons abordé pour combiner des distributions dans le post de la semaine dernière sur les modèles de mélange. Les fonctions de densité de deux vecteurs (gouttes gaussiennes) et le résultat de leur addition sont illustrés dans la figure ci-dessous. De la même manière, nous pouvons multiplier une fonction par un nombre, ce qui a pour effet d’éclaircir ou d’assombrir la densité globale. En fait, ce sont deux opérations que vous avez probablement beaucoup pratiquées en cours d’algèbre et de calcul. Donc, nous ne faisons encore rien de nouveau, nous pensons simplement aux choses d’une manière différente.

L’étape suivante consiste à définir un noyau à partir de notre espace de données original dans cet espace infiniment dimensionnel, et ici nous avons beaucoup de choix. L’un des choix les plus courants est la fonction blob gaussienne que nous avons vue à plusieurs reprises dans des posts précédents. Pour ce noyau, nous allons choisir une taille standard pour les blobs gaussiens, c’est-à-dire une valeur fixe pour la déviation 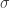
Maintenant, voici le problème : afin de ramener les choses dans le monde computationnel, nous devons choisir un espace vectoriel de dimension finie assis dans cet espace vectoriel de dimension infinie et « projeter » l’espace de dimension infinie dans le sous-espace de dimension finie. Nous choisirons un espace de dimension finie en choisissant un nombre (fini) de points dans l’espace des données, puis en prenant l’espace vectoriel couvert par les gouttes gaussiennes centrées sur ces points. C’est l’équivalent de l’espace vectoriel défini par les cinq premières coordonnées du noyau polynomial infini, comme ci-dessus. Le choix de ces points est important, mais nous y reviendrons plus tard. Pour l’instant, la question est de savoir comment on projette ?
Pour les vecteurs de dimension finie, la façon la plus courante de définir une projection est d’utiliser le produit scalaire : C’est le nombre que l’on obtient en multipliant les coordonnées correspondantes de deux vecteurs, puis en les additionnant. Ainsi, par exemple, le produit scalaire des vecteurs tridimensionnels 


Nous pourrions faire quelque chose de similaire avec les fonctions, en multipliant les valeurs qu’elles prennent sur les points correspondants dans l’ensemble de données. (En d’autres termes, nous multiplions les deux fonctions ensemble.) Mais nous ne pouvons pas ensuite additionner tous ces nombres car ils sont infiniment nombreux. Au lieu de cela, nous allons prendre une intégrale ! (Notez que je passe sur une tonne de détails ici, et je m’excuse encore auprès des mathématiciens qui lisent ceci). Ce qui est bien ici, c’est que si nous multiplions deux fonctions gaussiennes et que nous intégrons, le nombre est égal à une fonction gaussienne de la distance entre les points centraux. (Bien que la nouvelle fonction gaussienne aura une valeur de déviation différente.)
En d’autres termes, le noyau gaussien transforme le produit scalaire dans l’espace de dimension infinie en fonction gaussienne de la distance entre les points dans l’espace des données : Si deux points de l’espace de données sont proches, l’angle entre les vecteurs qui les représentent dans l’espace du noyau sera faible. Si les points sont éloignés alors les vecteurs correspondants seront proches de la « perpendiculaire ».
La partie pratique
Alors, passons en revue ce que nous avons jusqu’à présent : Pour définir un noyau gaussien 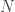
Pour mieux comprendre comment ce noyau fonctionne, voyons à quoi ressemble l’intersection d’un hyperplan avec l’espace des données. (C’est ce qui est fait avec les noyaux la plupart du temps, de toute façon.) Rappelons qu’un plan est défini par une équation de la forme 


C’est encore assez difficile à décortiquer, alors regardons un exemple où chacune des valeurs 

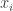





Si nous ajustons les paramètres
Donc, cela nous donne plus de flexibilité pour choisir la frontière de décision (ou, au moins, un autre type de flexibilité) mais le résultat final sera très dépendant des
Trouver une telle collection de points est un problème très différent de celui sur lequel nous nous sommes concentrés dans les articles jusqu’à présent sur ce blog, et tombe dans la catégorie de l’apprentissage non supervisé/analyse descriptive. (Dans le contexte des noyaux, on peut également penser à la sélection/ingénierie des caractéristiques). Dans les prochains billets, nous allons changer de vitesse et commencer à explorer des idées dans ce sens.