Die Fehlerbehandlung ist ein wesentlicher Bestandteil von RxJs, da wir sie in so gut wie jedem reaktiven Programm, das wir schreiben, benötigen werden.
Die Fehlerbehandlung in RxJS ist wahrscheinlich nicht so gut verstanden wie andere Teile der Bibliothek, aber sie ist eigentlich recht einfach zu verstehen, wenn wir uns zunächst auf das Verständnis des Observable-Vertrags im Allgemeinen konzentrieren.
In diesem Beitrag werden wir einen vollständigen Leitfaden mit den häufigsten Fehlerbehandlungsstrategien bereitstellen, die Sie benötigen, um die meisten praktischen Szenarien abzudecken, beginnend mit den Grundlagen (dem Observable-Vertrag).
- Inhaltsverzeichnis
- Der Observable-Vertrag und die Fehlerbehandlung
- RxJs subscribe and error callbacks
- Completion Behavior Example
- Einschränkungen des subscribe error handlers
- Der catchError-Operator
- Wie funktioniert catchError?
- Was passiert, wenn ein Fehler ausgelöst wird?
- Die Catch and Replace Strategie
- Die Catch and Rethrow-Strategie
- Catch and Rethrow breakdown
- Mehrfache Verwendung von catchError in einer Observable-Kette
- Der Finalize-Operator
- Beispiel für den finalize-Operator
- Die Wiederholungsstrategie
- Wann soll man es erneut versuchen?
- RxJs retryWhen Operator Marble Diagram
- Aufschlüsselung der Funktionsweise von retryWhen
- Erstellen einer Notification Observable
- Sofortige Wiederholungsstrategie
- Immediate Retry Console Output
- Delayed Retry Strategy
- Die Timer-Observable-Erstellungsfunktion
- Der delayWhen Operator
- DelayWhen Operator breakdown
- Verzögerte Wiederholungsstrategie-Implementierung
- Retry Strategy Console Output
- Laufendes Github-Repository (mit Codebeispielen)
- Schlussfolgerungen
Inhaltsverzeichnis
In diesem Beitrag werden wir die folgenden Themen behandeln:
- Der Observable-Vertrag und die Fehlerbehandlung
- RxJs-Abonnement und Fehlerrückrufe
- Der catchError-Operator
- Die Catch and Replace Strategie
- ThrowError und die Catch and Rethrow Strategie
- Mehrfache Verwendung von catchError in einer Observable-Kette
- Der finalize Operator
- Die Retry Strategie
- Dann retryWhen Operator
- Erzeugen einer Notification Observable
- Sofortige Wiederholungsstrategie
- Verzögerte Wiederholungsstrategie
- Der delayWhen Operator
- Die Timer Observable Erstellungsfunktion
- Github Repository (mit Codebeispielen)
- Schlussfolgerungen
So ohne weiteres, Lassen Sie uns mit unserer RxJs-Fehlerbehandlung tief eintauchen!
Der Observable-Vertrag und die Fehlerbehandlung
Um die Fehlerbehandlung in RxJs zu verstehen, müssen wir zunächst wissen, dass jeder Stream nur einmal fehlschlagen kann. Dies wird durch den Observable-Vertrag definiert, der besagt, dass ein Stream null oder mehr Werte ausgeben kann.
Der Vertrag funktioniert so, weil alle Streams, die wir in unserer Laufzeit beobachten, in der Praxis genau so funktionieren. Netzwerkanfragen können zum Beispiel fehlschlagen.
Ein Stream kann sich auch vervollständigen, was bedeutet, dass:
- der Stream seinen Lebenszyklus ohne Fehler beendet hat
- nach der Vervollständigung wird der Stream keine weiteren Werte ausgeben
Alternativ zur Vervollständigung kann ein Stream auch einen Fehler machen, was bedeutet, dass:
- der Stream hat seinen Lebenszyklus mit einem Fehler beendet
- nach dem Auslösen des Fehlers wird der Stream keine weiteren Werte ausgeben
Beachten Sie, dass sich Vollendung und Fehler gegenseitig ausschließen:
- wenn der Stream vervollständigt wird, kann er danach keinen Fehler mehr machen
- wenn der Stream einen Fehler macht, kann er danach nicht mehr vervollständigen
Beachte auch, dass es keine Verpflichtung für den Stream gibt, zu vervollständigen oder einen Fehler zu machen, diese beiden Möglichkeiten sind optional. Aber nur eine dieser beiden Möglichkeiten kann auftreten, nicht beide.
Das bedeutet, wenn ein bestimmter Stream ausfällt, können wir ihn gemäß dem Observable-Vertrag nicht mehr verwenden. Sie denken jetzt sicher, wie können wir uns dann von einem Fehler erholen?
RxJs subscribe and error callbacks
Um das Fehlerbehandlungsverhalten von RxJs in Aktion zu sehen, lassen Sie uns einen Stream erstellen und ihn abonnieren. Erinnern wir uns daran, dass der subscribe-Aufruf drei optionale Argumente benötigt:
- eine Success-Handler-Funktion, die jedes Mal aufgerufen wird, wenn der Stream einen Wert ausgibt
- eine Error-Handler-Funktion, die nur aufgerufen wird, wenn ein Fehler auftritt. Dieser Handler empfängt den Fehler selbst
- eine Completion-Handler-Funktion, die nur aufgerufen wird, wenn der Stream abgeschlossen ist
Completion Behavior Example
Wenn der Stream keinen Fehler macht, dann ist es das, was wir in der Konsole sehen würden:
HTTP response {payload: Array(9)}HTTP request completed.Wie wir sehen können, sendet dieser HTTP-Stream nur einen Wert, und dann ist er abgeschlossen, was bedeutet, dass keine Fehler aufgetreten sind.
Aber was passiert, wenn der Stream stattdessen einen Fehler auslöst? In diesem Fall sehen wir in der Konsole stattdessen Folgendes:

Wie wir sehen können, gab der Stream keinen Wert aus und es trat sofort ein Fehler auf. Nach dem Fehler kam es zu keiner Beendigung.
Einschränkungen des subscribe error handlers
Die Fehlerbehandlung mit dem subscribe-Aufruf ist manchmal alles, was wir brauchen, aber dieser Ansatz der Fehlerbehandlung ist begrenzt. Mit diesem Ansatz können wir uns zum Beispiel nicht von dem Fehler erholen oder einen alternativen Fallback-Wert ausgeben, der den Wert ersetzt, den wir vom Backend erwartet haben.
Lernen wir nun einige Operatoren kennen, die es uns ermöglichen, einige fortgeschrittenere Fehlerbehandlungsstrategien zu implementieren.
Der catchError-Operator
In der synchronen Programmierung haben wir die Möglichkeit, einen Code-Block in eine try-Klausel zu verpacken, jeden Fehler, den er auslösen könnte, mit einem catch-Block abzufangen und dann den Fehler zu behandeln.
So sieht die synchrone catch-Syntax aus:
Dieser Mechanismus ist sehr mächtig, weil wir jeden Fehler, der innerhalb des try/catch-Blocks auftritt, an einer Stelle behandeln können.
Das Problem ist, dass in Javascript viele Operationen asynchron sind, und ein HTTP-Aufruf ist ein solches Beispiel, wo Dinge asynchron passieren.
RxJs bietet uns mit dem RxJs catchError Operator etwas, das dieser Funktionalität sehr nahe kommt.
Wie funktioniert catchError?
Wie üblich und wie bei jedem RxJs Operator ist catchError einfach eine Funktion, die ein Input Observable aufnimmt und ein Output Observable ausgibt.
Bei jedem Aufruf von catchError müssen wir ihm eine Funktion übergeben, die wir die Fehlerbehandlungsfunktion nennen werden.
Der catchError-Operator nimmt als Eingabe eine Observable, die fehlerhaft sein könnte, und beginnt, die Werte der Eingabe-Observable in seine Ausgabe-Observable auszugeben.
Wenn kein Fehler auftritt, arbeitet die von catchError erzeugte Ausgabe-Observable genau so wie die Eingabe-Observable.
Was passiert, wenn ein Fehler ausgelöst wird?
Wenn jedoch ein Fehler auftritt, wird die catchError-Logik aktiv. Der catchError-Operator nimmt den Fehler und übergibt ihn an die Fehlerbehandlungsfunktion.
Diese Funktion soll ein Observable zurückgeben, das ein Ersatz-Observable für den Stream ist, bei dem gerade ein Fehler aufgetreten ist.
Erinnern wir uns, dass der Eingabestrom von catchError ausgefallen ist, so dass wir ihn gemäß dem Observable-Vertrag nicht mehr verwenden können.
Dieses Ersatz-Observable wird dann abonniert und seine Werte werden anstelle des ausgefallenen Eingabe-Observable verwendet.
Die Catch and Replace Strategie
Lassen Sie uns ein Beispiel geben, wie catchError verwendet werden kann, um ein Ersatz-Observable bereitzustellen, das Fallback-Werte ausgibt:
Lassen Sie uns die Implementierung der Catch and Replace Strategie aufschlüsseln:
- Wir übergeben dem catchError-Operator eine Funktion, bei der es sich um die Fehlerbehandlungsfunktion handelt
- Die Fehlerbehandlungsfunktion wird nicht sofort aufgerufen, und im Allgemeinen wird sie auch nicht aufgerufen
- Nur wenn ein Fehler im Input Observable von catchError auftritt, wird die Fehlerbehandlungsfunktion aufgerufen
- Wenn ein Fehler im Input Stream auftritt, gibt diese Funktion dann ein Observable zurück, das mit der Funktion
of()erstellt wurde - Die Funktion
of()erstellt ein Observable, das nur einen Wert () ausgibt, und schließt dann ab - Die Fehlerbehandlungsfunktion gibt das Recovery Observable (
of()) zurück, die vom catchError-Operator abonniert wird - die Werte der Recovery Observable werden dann als Ersatzwerte in der von catchError zurückgegebenen Output Observable ausgegeben
Als Endergebnis wird die http$ Observable nicht mehr ausfallen! Hier ist das Ergebnis, das wir in der Konsole erhalten:
HTTP response HTTP request completed.Wie wir sehen können, wird der Fehlerbehandlungs-Callback in subscribe() nicht mehr aufgerufen. Stattdessen geschieht Folgendes:
- der leere Array-Wert
wird ausgegeben - das
http$Observable wird dann abgeschlossen
Wie wir sehen können, wurde das Ersatz-Observable verwendet, um den Abonnenten von http$ einen Standardrückfallwert () zu liefern, obwohl das ursprüngliche Observable einen Fehler hatte.
Beachte, dass wir auch eine lokale Fehlerbehandlung hätten hinzufügen können, bevor wir das Ersatz-Observable zurückgeben!
Und damit ist die Catch and Replace-Strategie abgedeckt, nun wollen wir sehen, wie wir auch catchError verwenden können, um den Fehler erneut auszulösen, anstatt Fallback-Werte bereitzustellen.
Die Catch and Rethrow-Strategie
Beginnen wir mit der Feststellung, dass das Ersatz-Observable, das über catchError bereitgestellt wird, selbst auch einen Fehler machen kann, genau wie jedes andere Observable.
Und wenn das passiert, wird der Fehler an die Abonnenten der Ausgabe-Observable von catchError weitergegeben.
Dieses Verhalten der Fehlerweitergabe gibt uns einen Mechanismus, um den von catchError abgefangenen Fehler nach der lokalen Behandlung des Fehlers erneut auszulösen. Wir können dies auf folgende Weise tun:
Catch and Rethrow breakdown
Lassen Sie uns Schritt für Schritt die Implementierung der Catch and Rethrow Strategie aufschlüsseln:
- Wie zuvor fangen wir den Fehler ab und geben ein Ersatz-Observable zurück
- Aber dieses Mal behandeln wir den Fehler lokal in der Funktion catchError
- Anstatt einen Ersatz-Ausgabewert wie
bereitzustellen, protokollieren wir den Fehler in diesem Fall einfach auf der Konsole, aber wir könnten stattdessen jede beliebige lokale Fehlerbehandlungslogik hinzufügen, wie zum Beispiel eine Fehlermeldung für den Benutzer anzeigen - Wir geben dann ein Ersatz-Observable zurück, das diesmal mit throwError
- throwError erzeugt ein Observable, das niemals einen Wert ausgibt. Stattdessen gibt es sofort den gleichen Fehler aus, der von catchError
- abgefangen wurde, was bedeutet, dass die Ausgabe Observable von catchError auch mit genau dem gleichen Fehler ausfällt, der von der Eingabe von catchError
- geworfen wurde, was bedeutet, dass wir es geschafft haben, den Fehler, der ursprünglich von der Eingabe Observable von catchError geworfen wurde, erfolgreich in die Ausgabe Observable
- zu werfen, der Fehler kann nun vom Rest der Observable-Kette weiter behandelt werden, falls erforderlich
Wenn wir nun den obigen Code ausführen, ist hier das Ergebnis, das wir in der Konsole erhalten:

Wie wir sehen können, wurde derselbe Fehler sowohl im catchError-Block als auch in der Abonnement-Fehlerbehandlungsfunktion protokolliert, wie erwartet.
Mehrfache Verwendung von catchError in einer Observable-Kette
Beachten Sie, dass wir catchError bei Bedarf mehrfach an verschiedenen Punkten in der Observable-Kette verwenden und an jedem Punkt der Kette unterschiedliche Fehlerstrategien anwenden können.
Wir können zum Beispiel einen Fehler oben in der Observable-Kette abfangen, ihn lokal behandeln und erneut auslösen, und dann weiter unten in der Observable-Kette können wir denselben Fehler erneut abfangen und dieses Mal einen Rückfallwert bereitstellen (anstatt erneut auszulösen):
Wenn wir den obigen Code ausführen, ist dies die Ausgabe, die wir in der Konsole erhalten:
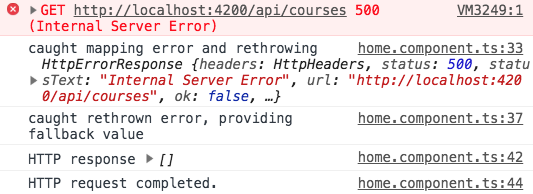
Wie wir sehen können, wurde der Fehler in der Tat anfangs erneut ausgelöst, aber er erreichte nie die Subscribe Error Handler Funktion. Stattdessen wurde wie erwartet der Fallback -Wert ausgegeben.
Der Finalize-Operator
Neben einem Catch-Block zur Fehlerbehandlung bietet die synchrone Javascript-Syntax auch einen Finally-Block, der verwendet werden kann, um Code auszuführen, der immer ausgeführt werden soll.
Der Finally-Block wird typischerweise verwendet, um teure Ressourcen freizugeben, wie zum Beispiel das Schließen von Netzwerkverbindungen oder die Freigabe von Speicher.
Im Gegensatz zum Code im catch-Block wird der Code im finally-Block unabhängig davon ausgeführt, ob ein Fehler auftritt oder nicht:
RxJs stellt uns einen Operator zur Verfügung, der sich ähnlich verhält wie die finally-Funktionalität, den finalize-Operator.
Hinweis: Wir können ihn nicht stattdessen den finally-Operator nennen, da finally ein reserviertes Schlüsselwort in Javascript ist
Beispiel für den finalize-Operator
Genauso wie der catchError-Operator können wir bei Bedarf mehrere finalize-Aufrufe an verschiedenen Stellen in der Observable-Kette hinzufügen, um sicherzustellen, dass die verschiedenen Ressourcen korrekt freigegeben werden:
Lassen Sie uns nun diesen Code ausführen und sehen, wie die mehreren Finalize-Blöcke ausgeführt werden:

Beachten Sie, dass der letzte Finalize-Block nach den Funktionen subscribe value handler und completion handler ausgeführt wird.
Die Wiederholungsstrategie
Als Alternative zum erneuten Auslösen des Fehlers oder zum Bereitstellen von Fallback-Werten können wir auch einfach erneut versuchen, das fehlerhafte Observable zu abonnieren.
Erinnern wir uns: Wenn der Stream einmal fehlerhaft ist, können wir ihn nicht wiederherstellen, aber nichts hindert uns daran, das Observable, von dem der Stream abgeleitet wurde, erneut zu abonnieren und einen anderen Stream zu erstellen.
So funktioniert das:
- Wir nehmen das Input Observable und abonnieren es, was einen neuen Stream erzeugt
- Wenn dieser Stream nicht fehlschlägt, lassen wir seine Werte in der Ausgabe erscheinen
- Wenn der Stream aber fehlschlägt, abonnieren wir wieder das Input Observable und erzeugen einen ganz neuen Stream
Wann soll man es erneut versuchen?
Die große Frage hier ist, wann wir die Input Observable erneut abonnieren und erneut versuchen, den Input Stream auszuführen?
- Werden wir es sofort erneut versuchen?
- Werden wir eine kleine Verzögerung abwarten, in der Hoffnung, dass das Problem gelöst ist und es dann erneut versuchen?
- werden wir es nur eine begrenzte Anzahl von Malen wiederholen und dann den Ausgabestrom mit einem Fehler versehen?
Um diese Fragen zu beantworten, benötigen wir ein zweites Hilfsobservable, das wir Notifier Observable nennen werden. Es ist die Notifier
Observable, die bestimmen wird, wann der Wiederholungsversuch stattfindet.
Die Notifier Observable wird vom retryWhen Operator verwendet, der das Herzstück der Wiederholungsstrategie ist.
RxJs retryWhen Operator Marble Diagram
Um zu verstehen, wie der retryWhen Observable funktioniert, werfen wir einen Blick auf sein Marble Diagram:

Beachten Sie, dass der Observable, der erneut versucht wird, der 1-2 Observable in der zweiten Zeile von oben ist, und nicht der Observable in der ersten Zeile.
Die Observable in der ersten Zeile mit den Werten r-r ist die Notification Observable, die bestimmt, wann ein Wiederholungsversuch stattfinden soll.
Aufschlüsselung der Funktionsweise von retryWhen
Lassen Sie uns aufschlüsseln, was in diesem Diagramm passiert:
- Die Observable 1-2 wird abonniert, und ihre Werte spiegeln sich sofort in der von retry zurückgegebenen Output-Observable wider
- Selbst wenn die Observable 1-2 abgeschlossen ist, kann sie immer noch erneut versucht werden
- Die Notification Observable sendet dann einen Wert
r, weit nachdem die Observable 1-2 abgeschlossen ist - Der von der Notification Observable ausgesendete Wert (in diesem Fall
r) kann alles Mögliche sein - Was zählt, ist der Moment, in dem der Wert
rausgesendet wurde, denn das ist der Auslöser dafür, dass die Observable 1-2 erneut versucht wird - Die Observable 1-2 wird erneut von retryWhen abonniert, und ihre Werte spiegeln sich erneut in der Output-Observable von retryWhen wider
- Die Observable für die Benachrichtigung gibt dann erneut einen Wert
raus, und das Gleiche geschieht: Die Werte eines neu abonnierten 1-2-Streams werden sich in der Ausgabe von retryWhen - widerspiegeln, aber dann wird die Notification Observable schließlich in diesem Moment beendet
- , wird der laufende Wiederholungsversuch des 1-2 Observable ebenfalls vorzeitig beendet, was bedeutet, dass nur der Wert 1 ausgegeben wurde, aber nicht 2
Wie wir sehen können, wiederholt retryWhen einfach das input Observable jedes Mal, wenn das Notification Observable einen Wert ausgibt!
Nachdem wir nun verstanden haben, wie retryWhen funktioniert, wollen wir uns ansehen, wie wir eine Notification Observable erstellen können.
Erstellen einer Notification Observable
Wir müssen die Notification Observable direkt in der Funktion erstellen, die dem retryWhen-Operator übergeben wird. Diese Funktion nimmt als Eingangsargument ein Errors Observable, das als Werte die Fehler des Input Observable ausgibt.
Durch das Abonnieren dieses Errors Observable wissen wir also genau, wann ein Fehler auftritt. Schauen wir uns nun an, wie wir mit Hilfe des Errors Observable eine Strategie zur sofortigen Wiederholung implementieren können.
Sofortige Wiederholungsstrategie
Um das fehlgeschlagene Observable sofort nach Auftreten des Fehlers erneut zu versuchen, müssen wir nur das Errors Observable ohne weitere Änderungen zurückgeben.
In diesem Fall pipen wir nur den Tap-Operator zu Protokollierungszwecken, so dass die Errors Observable unverändert bleibt:
Erinnern wir uns, die Observable, die wir vom Funktionsaufruf retryWhen zurückgeben, ist die Notification Observable!
Der Wert, den sie ausgibt, ist nicht wichtig, es ist nur wichtig, wann der Wert ausgegeben wird, denn das ist es, was einen erneuten Versuch auslösen wird.
Immediate Retry Console Output
Wenn wir nun dieses Programm ausführen, werden wir folgende Ausgabe in der Konsole finden:

Wie wir sehen können, ist die HTTP-Anfrage zunächst fehlgeschlagen, aber dann wurde ein erneuter Versuch unternommen und beim zweiten Mal wurde die Anfrage erfolgreich ausgeführt.
Werfen wir nun einen Blick auf die Verzögerung zwischen den beiden Versuchen, indem wir das Netzwerkprotokoll untersuchen:

Wie wir sehen, wurde der zweite Versuch wie erwartet unmittelbar nach dem Auftreten des Fehlers ausgegeben.
Delayed Retry Strategy
Lassen Sie uns nun eine alternative Fehlerbehebungsstrategie implementieren, bei der wir z.B. 2 Sekunden nach dem Auftreten des Fehlers warten, bevor wir es erneut versuchen.
Diese Strategie ist nützlich, um sich von bestimmten Fehlern zu erholen, wie z.B. von fehlgeschlagenen Netzwerkanfragen, die durch hohen Serververkehr verursacht wurden.
In den Fällen, in denen der Fehler nur sporadisch auftritt, können wir dieselbe Anfrage nach einer kurzen Verzögerung einfach erneut versuchen, und die Anfrage wird vielleicht beim zweiten Mal ohne Probleme durchgehen.
Die Timer-Observable-Erstellungsfunktion
Um die Strategie der verzögerten Wiederholung zu implementieren, müssen wir eine Notification Observable erstellen, deren Werte zwei Sekunden nach jedem Auftreten eines Fehlers ausgegeben werden.
Lassen Sie uns nun versuchen, eine Notification Observable mit Hilfe der Timer-Erstellungsfunktion zu erstellen. Diese Timer-Funktion benötigt einige Argumente:
- eine anfängliche Verzögerung, vor der keine Werte ausgegeben werden
- ein periodisches Intervall, für den Fall, dass wir regelmäßig neue Werte ausgeben wollen
Werfen wir einen Blick auf das Marmordiagramm für die Timer-Funktion:

Wie wir sehen können, wird der erste Wert 0 erst nach 3 Sekunden ausgegeben, und dann haben wir jede Sekunde einen neuen Wert.
Beachte, dass das zweite Argument optional ist, d.h. wenn wir es weglassen, wird unser Observable nur einen Wert (0) nach 3 Sekunden ausgeben und dann fertig.
Dieses Observable scheint ein guter Anfang zu sein, um unsere Wiederholungsversuche zu verzögern, also sehen wir uns an, wie wir es mit den Operatoren retryWhen und delayWhen kombinieren können.
Der delayWhen Operator
Eine wichtige Sache, die man beim retryWhen Operator beachten muss, ist, dass die Funktion, die das Notification Observable definiert, nur einmal aufgerufen wird.
Wir haben also nur eine Chance, unsere Notification Observable zu definieren, die signalisiert, wann die Wiederholungsversuche durchgeführt werden sollen.
Wir werden die Notification Observable definieren, indem wir die Errors Observable nehmen und den delayWhen Operator anwenden.
Stellen Sie sich vor, dass in diesem Marmor-Diagramm die Quell-Observable a-b-c die Errors-Observable ist, die im Laufe der Zeit fehlgeschlagene HTTP-Fehler ausgibt:

DelayWhen Operator breakdown
Lassen Sie uns dem Diagramm folgen und lernen, wie der delayWhen Operator funktioniert:
- Jeder Wert im Input Errors Observable wird verzögert, bevor er im Output Observable auftaucht
- Die Verzögerung für jeden Wert kann unterschiedlich sein und wird auf völlig flexible Weise erstellt
- um die Verzögerung zu bestimmen, rufen wir die Funktion auf, die an delayWhen übergeben wird (die so genannte Dauer-Selektor-Funktion), und zwar für jeden Wert der Eingabefehler Observable
- Diese Funktion gibt ein Observable aus, das bestimmt, wann die Verzögerung jedes Eingabewerts abgelaufen ist
- Jeder der Werte a-b-c hat sein eigenes Dauer-Selektor-Observable, die schließlich einen Wert ausgibt (der alles Mögliche sein kann) und dann abgeschlossen wird
- wenn jeder dieser Dauer-Selektor-Observablen Werte ausgibt, dann wird der entsprechende Eingabewert a-b-c in der Ausgabe von delayWhen
- auftauchen. Beachten Sie, dass der Wert
bin der Ausgabe nach dem Wertcauftaucht, das ist normal - das liegt daran, dass der
bDuration Selector Observable (die dritte horizontale Linie von oben) seinen Wert erst nach dem Duration Selector Observable voncausgibt, und das erklärt, warumcin der Ausgabe vorb
Verzögerte Wiederholungsstrategie-Implementierung
Setzen wir nun all dies zusammen und sehen wir, wie wir eine fehlgeschlagene HTTP-Anfrage 2 Sekunden nach Auftreten jedes Fehlers nacheinander wiederholen können:
Lassen Sie uns aufschlüsseln, was hier vor sich geht:
- Erinnern wir uns daran, dass die Funktion, die an retryWhen übergeben wird, nur einmal aufgerufen wird
- Wir geben in dieser Funktion ein Observable zurück, das Werte ausgibt, wenn ein erneuter Versuch erforderlich ist
- jedes Mal, wenn ein Fehler auftritt, der delayWhen-Operator wird einen Dauer-Selektor Observable erstellen, indem er die Timer-Funktion aufruft
- dieser Dauer-Selektor Observable wird nach 2 Sekunden den Wert 0 ausgeben, und dann beendet
- wenn das passiert, der delayWhen Observable weiß, dass die Verzögerung eines gegebenen Eingabefehlers abgelaufen ist
- nur wenn diese Verzögerung abläuft (2 Sekunden nach Auftreten des Fehlers), erscheint der Fehler in der Ausgabe des notification Observable
- einmal wird ein Wert im notification Observable ausgegeben, wird der retryWhen Operator dann und nur dann einen Wiederholungsversuch durchführen
Retry Strategy Console Output
Lassen Sie uns nun sehen, wie dies in der Konsole aussieht! Hier ist ein Beispiel für eine HTTP-Anfrage, die 5 Mal wiederholt wurde, da die ersten 4 Male fehlerhaft waren:

Und hier ist das Netzwerkprotokoll für die gleiche Wiederholungssequenz:

Wie wir sehen können, erfolgten die Wiederholungen nur 2 Sekunden nach dem Auftreten des Fehlers, wie erwartet!
Und damit haben wir unseren Rundgang durch einige der am häufigsten verwendeten RxJs-Fehlerbehandlungsstrategien abgeschlossen, lassen Sie uns nun die Dinge abschließen und einige laufende Beispielcodes bereitstellen.
Laufendes Github-Repository (mit Codebeispielen)
Um diese verschiedenen Fehlerbehandlungsstrategien auszuprobieren, ist es wichtig, eine funktionierende Spielwiese zu haben, auf der man versuchen kann, fehlgeschlagene HTTP-Anfragen zu behandeln.
Diese Spielwiese enthält eine kleine laufende Anwendung mit einem Backend, das verwendet werden kann, um HTTP-Fehler entweder zufällig oder systematisch zu simulieren. So sieht die Anwendung aus:

Schlussfolgerungen
Wie wir gesehen haben, geht es beim Verständnis der RxJs-Fehlerbehandlung zunächst darum, die Grundlagen des Observable-Vertrags zu verstehen.
Wir müssen uns vor Augen halten, dass jeder gegebene Stream nur einmal einen Fehler machen kann, und zwar ausschließlich in Verbindung mit der Stream-Vervollständigung; nur eines der beiden Dinge kann passieren.
Um sich von einem Fehler zu erholen, besteht die einzige Möglichkeit darin, irgendwie einen Ersatz-Stream als Alternative zum fehlerhaften Stream zu generieren, wie es im Fall der catchError- oder retryWhen-Operatoren geschieht.
Ich hoffe, dass Ihnen dieser Beitrag gefallen hat. Wenn Sie noch viel mehr über RxJs lernen möchten, empfehlen wir Ihnen den Kurs RxJs in der Praxis, in dem viele nützliche Muster und Operatoren viel ausführlicher behandelt werden.