Willkommen zu Lektion neun ‚Manipulation Ihrer Daten‘ des SQL Tutorials, das ein Teil des SQL Trainingskurses ist. In dieser Lektion werden wir über die INSERT-, UPDATE- und DELETE-Anweisungen von SQL sprechen.
Ziele
Am Ende dieser Lektion werden Sie in der Lage sein,:
-
Erläutern Sie die INSERT-Anweisung und wie sie verwendet werden kann
-
Beschreiben Sie die UPDATE-Abfrage anhand von Beispielen
-
Erläutern Sie die DELETE-Anweisung anhand von Beispielen
Die INSERT-Anweisung
Die INSERT-Anweisung ist eine der drei Anweisungen, die zu dem so-sogenannten „Datenmanipulationssprache“-Teil des SQL – das sind INSERT, UPDATE, und DELETE.
Alle drei Anweisungen erlauben es, Daten in der Datenbank zu ändern, wobei nicht die Struktur, sondern der Inhalt geändert wird. Sie unterscheiden sich von der SELECT-Anweisung, mit der Sie nur Daten aus der Datenbank lesen können.
Mit der INSERT-Anweisung können Sie also neue Datensätze zu Ihrer Datenbanktabelle hinzufügen. Im Allgemeinen wird sie verwendet, um Datensätze am Ende der Tabelle hinzuzufügen. Wichtig bei INSERT ist, dass die Daten alle Regeln in der Datenbank erfüllen müssen.
Betrachten Sie die folgende Abbildung:
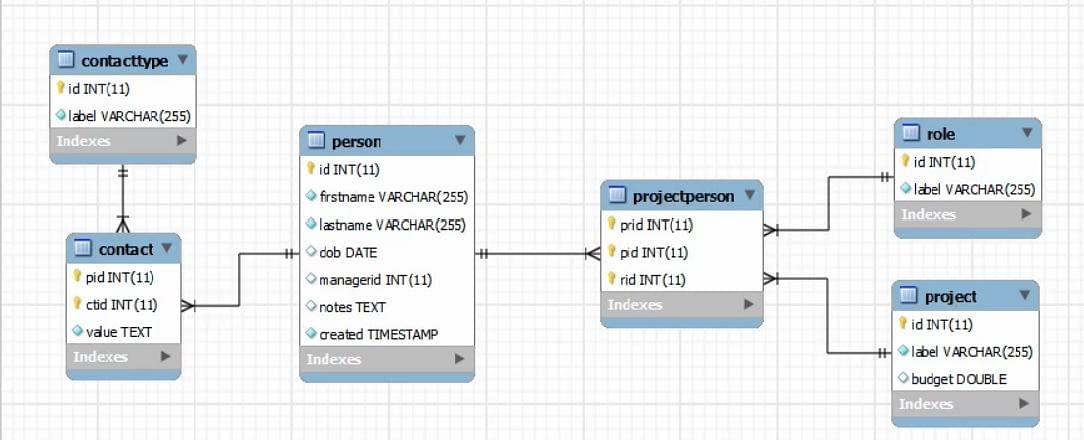
Betrachten wir zunächst die Tabelle Person als Beispiel. Hier haben wir den Primärschlüssel. Die Primärschlüssel in dieser Datenbank sind zuvor in unserem SQL auf automatische Inkrementierung eingestellt.
Wir fügen den Primärschlüssel nie selbst ein, das überlassen wir der Datenbank. Dann haben wir einen Vornamen und einen Nachnamen, die das NOT NULL-Flag haben. Die durchgezogene Raute zeigt an, dass diese Felder obligatorisch sind und nicht übersprungen werden können.
Der letzte ist der Zeitstempel, der NOT NULL ist, aber gleichzeitig ist der Standardwert der aktuelle Zeitstempel. Auch hier wird also automatisch ein aktueller Zeitstempel gesetzt, wenn wir kein Datum eingeben.
Wenn wir Datensätze in eine andere Tabelle einfügen müssen, müssen wir sicherstellen, dass die Daten tatsächlich existieren. In solchen End-to-End-Tabellen oder in jeder Art von Fremdschlüsselsituation müssen Sie also immer sicherstellen, dass die Daten, die Sie dort einfügen, tatsächlich gültige Werte in den Bezugstabellen darstellen.
Lassen Sie uns unsere Personentabelle wieder als Ausgangspunkt verwenden.
Die Personentabelle sieht zu Beginn wie folgt aus.
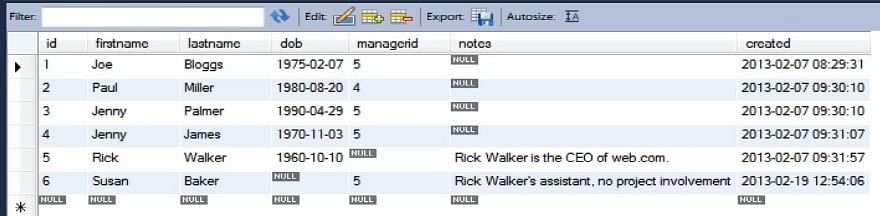
Betrachten wir folgendes Beispiel:
select * from person
insert into person
values (7, ‚Martin‘, ‚Holzke‘, ‚1980-05-05‘, ‚xxx‘, now());
Wir können immer nur in eine Tabelle einfügen. Sie können Daten mit Hilfe der SELECT-Funktion zusammenführen, aber traditionell können Sie Datenmanipulationen immer nur in einer Tabelle vornehmen.
Was wir im obigen Beispiel betrachtet haben, ist das „implizite Einfügen“. Das bedeutet, dass wir die Spalten, die wir auffüllen wollen, nicht erwähnen, sondern sie alle in genau der Reihenfolge einfügen müssen, in der die Tabelle existiert.
Das Einfügen wird die neuen Werte automatisch den Tabellenspalten zuordnen.
Hinweis: Bei der Einfüge-, Aktualisierungs- und Löschanweisung müssen wir bedenken, dass die Datenbanken keine Rückgängig-Taste haben. Sobald Sie also einen Wert gesendet haben, wird er in der Datenbank gespeichert.
Da wir das implizite Einfügen lernen, müssen wir die Werte für jede Spalte angeben. Daher ist es sehr hilfreich, die Datenbanktabelle auf demselben Bildschirm zu sehen.
Wenn wir nun den obigen Code ausführen, können Sie sehen, dass die Tabelle aktualisiert wurde und der eingefügte Datensatz an Position 7 zu sehen ist.
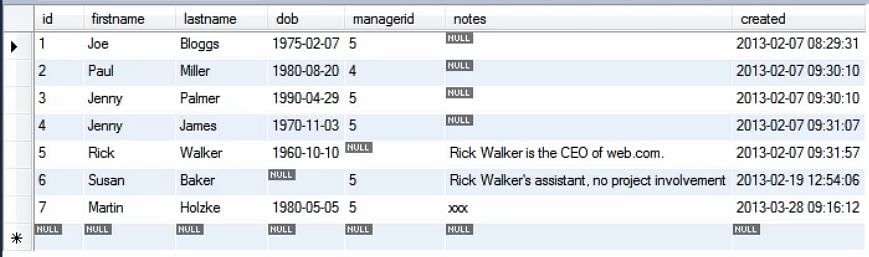
Außerdem gibt die Insert-Anweisung im Gegensatz zur SELECT-Anweisung nichts zurück. Deshalb ist der Bildschirm nachher leer.
Nun sehen wir uns die explizite Version an, deren Verwendung sehr zu empfehlen ist.
select * from person
insert into person (firstname, lastname, managerid, dob)
values (‚Martin‘, ‚Holzke‘, 5, ‚1980-05-05‘);
Im obigen Beispiel haben wir nur 4 Werte der Tabelle erwähnt. Der Rest wird standardmäßig ausgefüllt. Wenn wir die Abfrage ausführen, sehen wir, dass die neuen Werte der Tabelle hinzugefügt wurden.
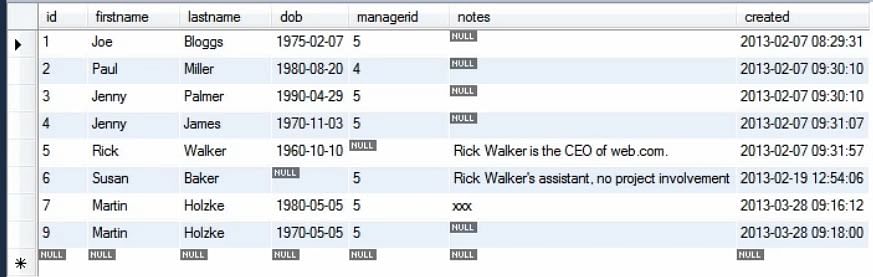
Der Primärschlüsselwert ist 9 und nicht 8, weil dieser Wert schon einmal in der Datenbank verwendet wurde.
Dies ist aus Sicherheitsgründen vorteilhaft, da der Primärschlüssel nicht wiederverwendet werden kann und Fehler erkannt werden können.
Wir sehen auch, dass der Wert der Spalte „created“ mit dem aktuellen Zeitstempel gesetzt wird, auch wenn wir ihn nicht explizit erwähnen.
Um mehrere Einfügungen vorzunehmen, können wir die obige Abfrage immer wieder mit unterschiedlichen Werten ausführen.
Die mehreren Einfügungen können mit nur einer Einfügeanweisung durchgeführt werden. Wir fügen den neuen Satz von Werten hinzu, die durch Kommas getrennt sind.
select * from person
insert into person (firstname, lastname, managerid, dob)
values (‚Martin‘, ‚Holzke‘, 5, ‚1980-05-05‘),
(‚Fred‘, ‚Flintstone‘, 5, ‚1987-06-02‘);
Das folgende Bild zeigt die aktualisierte Tabelle, wenn mehrere Einfügungen vorgenommen werden.
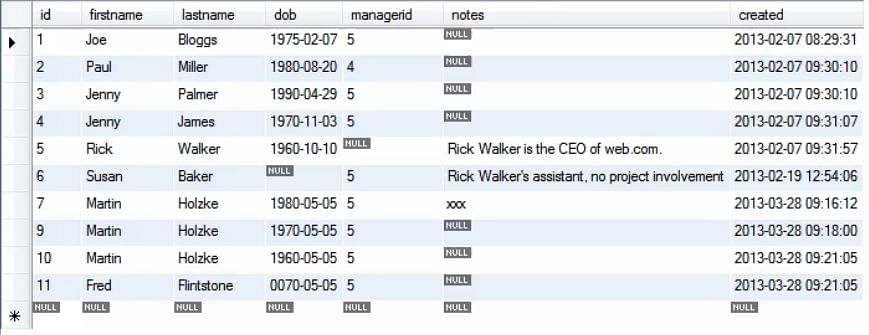
Als Nächstes wollen wir eine Einfügung vornehmen, indem wir Daten aus derselben Tabelle auswählen, so dass Sie Daten kopieren können, was sich beim Auffüllen einer Datenbank als sehr praktisch erweist. Zum Beispiel bei der Datenmigration möchte man Daten innerhalb einer Datenbank oder zwischen verschiedenen Datenbanken/Tabellen kopieren.
Der folgende Code zeigt, wie man Daten kopiert.
select * from person
insert into person (vorname, nachname, managerid, dob)
select concat(‚Kopie von‘, vorname), nachname, managerid, dob
from person
where id>=10
Das folgende Bild zeigt die Werte der Tabelle, wenn wir nur die select-Anweisung ausführen.
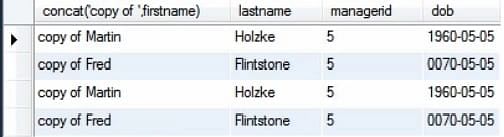
Nun führen wir die Abfrage zusammen mit der Insert-Anweisung aus. Dazu wählen wir einfach die Anweisungen aus, die wir ausführen möchten, und führen die Abfrage aus.
Das folgende Bild zeigt, wie die Tabelle nach Ausführung der obigen Abfrage geändert wurde.
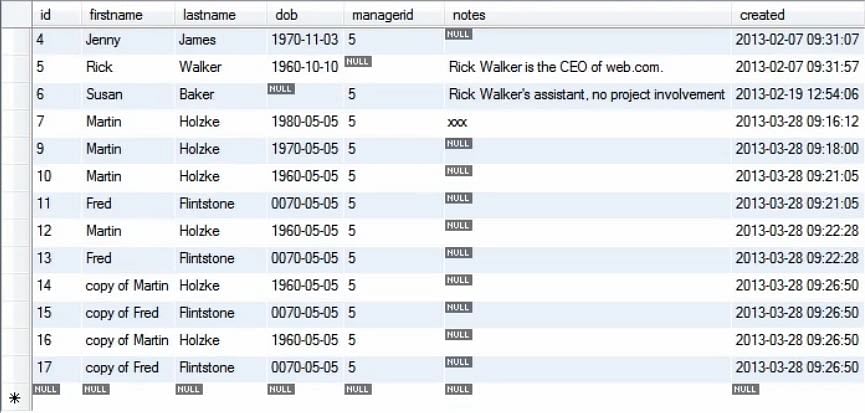 Wir haben also gesehen, wie das Kopieren von Werten mit der Insert-Anweisung die Datenbank auffüllen kann. Wir füllen die Datenbank im Allgemeinen auf, wenn wir die Abfragen in einer Testumgebung ausführen.
Wir haben also gesehen, wie das Kopieren von Werten mit der Insert-Anweisung die Datenbank auffüllen kann. Wir füllen die Datenbank im Allgemeinen auf, wenn wir die Abfragen in einer Testumgebung ausführen.
SQL – Aktualisierungsabfrage
Die Aktualisierungsabfrage oder -anweisung ist die zweite der drei Anweisungen der Datenmanipulationssprache, die INSERT, UPDATE und DELETE sind. Mit der UPDATE-Abfrage können Sie also bestehende Datensätze in einer Tabelle ändern.
Da SQL eine mengenbasierte Sprache ist, wirkt die UPDATE-Abfrage auf eine Menge von Datensätzen und nicht auf einen einzelnen Datensatz (je nachdem, wie Sie Ihre UPDATE-Anweisung ausführen).
Wie führen wir nun alle unsere Aktualisierungen durch?
Betrachten Sie die folgende Abfrage:
select * from person
where id = 10
update person
set dob = ‚1990-01-01‘
where id = 10
In der obigen Abfrage wählen wir zunächst die Datensätze aus der Tabelle Person aus, deren id gleich 10 ist. Das folgende Bild zeigt den Wert, der ausgewählt wird.

Dann verwenden wir die Update-Abfrage, um das Geburtsdatum für den Datensatz mit der ID 10 festzulegen. Wenn wir die where-Anweisung nicht verwenden, wird jeder einzelne Datensatz in unserer Tabelle auf den eingestellten Wert aktualisiert.
Bei der Ausführung der obigen Abfrage sehen wir, dass der dob-Wert für den 10. Eintrag in der Tabelle aktualisiert wurde.
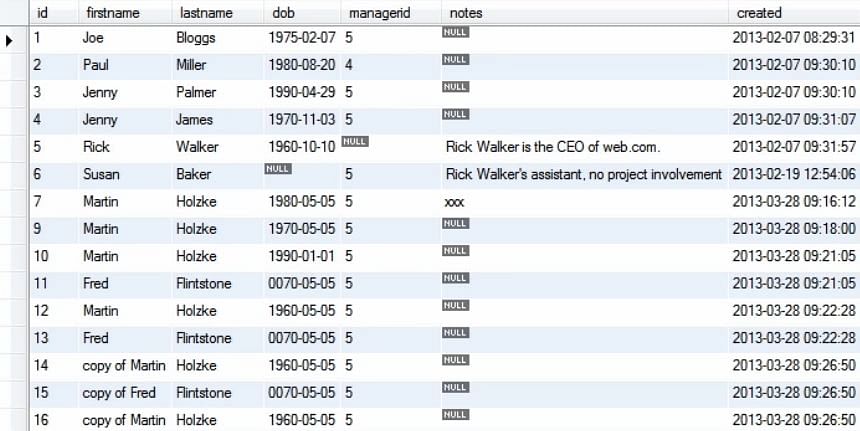 Nun können wir, um mehrere Dinge in einem Datensatz zu aktualisieren, die kommagetrennte Liste verwenden.
Nun können wir, um mehrere Dinge in einem Datensatz zu aktualisieren, die kommagetrennte Liste verwenden.
Betrachten Sie die untenstehende Abfrage:
select * from person
where id = 10
update person
set dob = ‚1990-01-01‘, firstname = ‚Mike‘
where id = 10
Wenn wir die obige Abfrage ausführen, erhalten wir die aktualisierte Tabelle wie gezeigt:
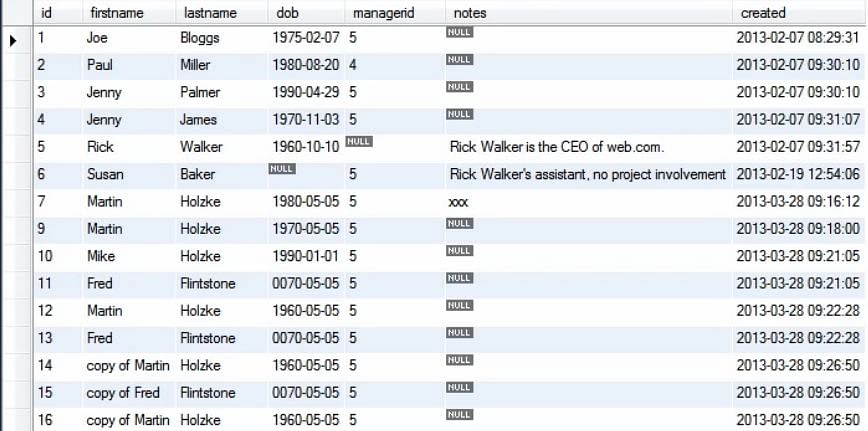
Wenn wir mehr als einen Datensatz ändern wollen, können wir wie folgt vorgehen:
select * from person
where firstname = ‚Martin‘
update person
set firstname = ‚Mike‘
where firstname = ‚Martin‘
In der obigen Abfrage haben wir den Wert für den Vornamen von Martin in Mike geändert, wo auch immer er zuvor in der Tabelle Person vorhanden war.
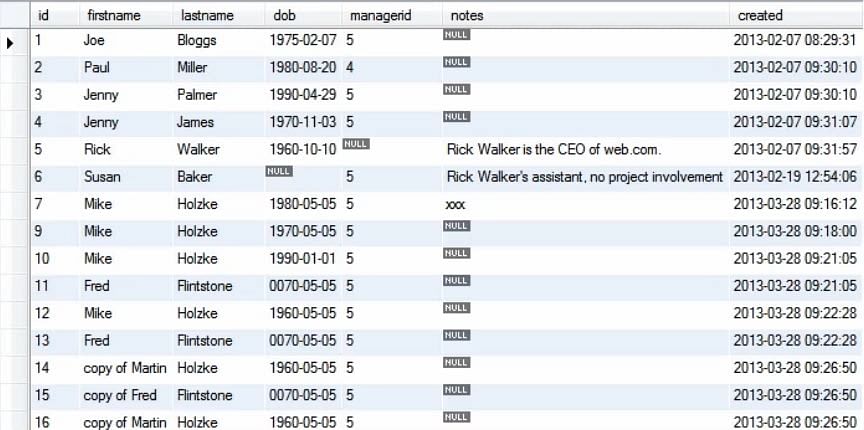
Lassen Sie uns ein anderes Beispiel betrachten:
Die Personentabelle bot keinen Spielraum für etwas mehr numerisches Zeug, also lassen Sie uns die Projekttabelle betrachten.
Hier nehmen wir ein Szenario, bei dem eine Bearbeitung der gesamten Tabelle wünschenswert sein könnte.
Die Projekttabelle hat im Moment drei Datensätze, wie gezeigt.
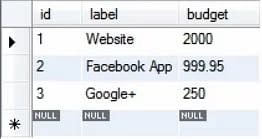
Jeder Datensatz hat einen Budgetwert. Nehmen wir an, dass wir sie alle um etwa 20 % erhöhen wollen. Dies können wir mit der folgenden Abfrage erreichen:
select * from project
update project
set budget = budget*1.2
Die obige Abfrage würde also alle Datensätze in der Projekttabelle um 20 % erhöhen.
Die aktualisierten Datensätze sehen wie folgt aus:
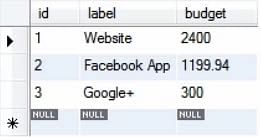
Daher können viele mathematische Operationen mit den Werten durchgeführt werden, wie in dem oben gezeigten Beispiel.
Eine Sache, die Sie bei der Verwendung der UPDATE-Anweisung beachten müssen, ist die Verwendung der ‚where‘-Klausel, wo immer sie anwendbar ist. Andernfalls werden die Werte aller Einträge in der Tabelle aktualisiert.
SQL DELETE-Anweisung
Schauen wir uns nun die DELETE-Anweisung an, die die letzte der drei Anweisungen der Datenmanipulationssprache ist. Die DELETE-Anweisung hat die Fähigkeit, einen oder mehrere Datensätze vollständig zu löschen. Es geht nicht darum, den Inhalt einzelner Spalten zu löschen, denn das ist nicht möglich.
Wenn Sie das tun wollen, müssen Sie die UPDATE-Anweisung verwenden, um den Inhalt der einzelnen Spalten zu ändern. DELETE ist also das Löschen eines ganzen Datensatzes oder mehrerer ganzer Datensätze.
Wie bei der INSERT- und UPDATE-Anweisung gilt auch hier, dass, sobald Sie eine Reihe von Datensätzen gelöscht haben, diese verschwunden sind und es keine Möglichkeit gibt, sie wiederherzustellen.
Wir müssen auch sicherstellen, dass, wenn wir einen Datensatz aus der Tabelle löschen, dieser Eintrag (oder sein Wert) nicht von einer anderen Tabelle verwendet wird.
Die Personentabelle hat die folgenden ursprünglichen Einträge.
Die DELETE-Anweisung kann wie in der folgenden Abfrage verwendet werden:
select * from person
where id = 10
delete from person
where id = 10
In der oben gezeigten Abfrage haben wir den Datensatz gelöscht, dessen id-Wert 10 war.
Hinweis: Denken Sie daran, die ‚where‘-Klausel mit der DELETE-Anweisung zu verwenden. Andernfalls wird die Anweisung Ihre Personentabelle ohne die ‚where‘-Klausel schnell leeren.
Wenn wir die obige Abfrage ausführen, stellen wir fest, dass der Eintrag mit dem ID-Wert 10 gelöscht wurde und die aktualisierte Tabelle wie abgebildet ist. Alles andere bleibt erhalten, außer dem Eintrag mit dem Primärschlüssel 10.
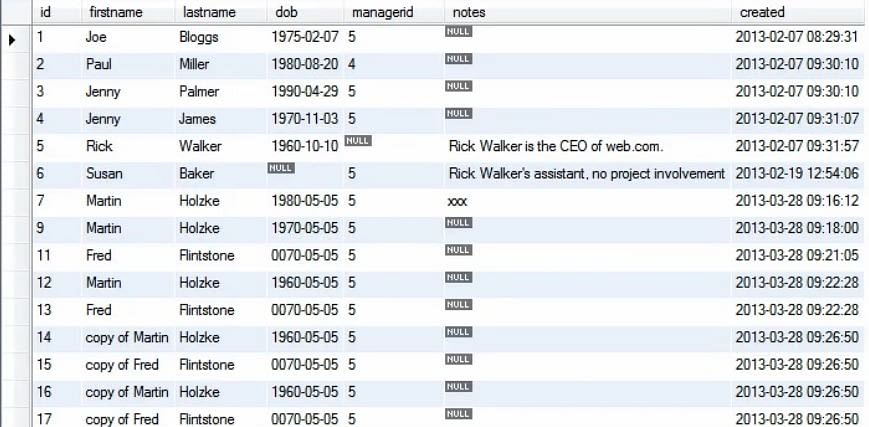
Es gibt Situationen, in denen wir einen ganzen Block loswerden wollen. Zum Beispiel möchten wir alle Kopieneinträge aus der Personentabelle löschen, wie gezeigt.
Die Abfrage zum Löschen aller Kopiereinträge aus der Tabelle „Person“ ist unten dargestellt:
select * from person
where firstname like ‚copy%‘
delete from person
where firstname like ‚copy%‘
In der obigen Abfrage bezeichnet ‚copy%‘ die Anweisungen, die mit copy beginnen und mit einem beliebigen Wort weitergehen.
Bei der Ausführung der obigen Abfrage können wir sehen, dass alle Datensätze, die mit ‚Kopie‘ beginnen, aus der Personentabelle gelöscht wurden.
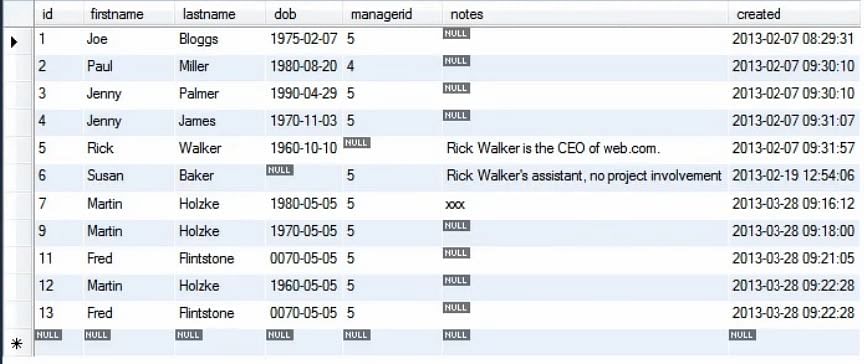
Hinweis: Es wird immer empfohlen, die DELETE-Anweisung für jeweils eine Tabelle zu verwenden. Es wird nicht empfohlen, die Anweisung bei gemeinsamen Tabellen zu verwenden.
Abschluss
Damit sind wir am Ende dieser Lektion über „Datenmanipulation in SQL“ angelangt. Die nächste Lektion befasst sich mit der Transaktionssteuerung.
{{lectureCoursePreviewTitle}} View Transcript Watch Video
Um mehr zu erfahren, besuchen Sie den Kurs
SQL Training Certification Training
Go to Course
Um mehr zu erfahren, besuchen Sie den Kurs
SQL-Schulung Zertifizierungsschulung Gehe zu Kurs