Um eine angemessene Einführung in die Gauß-Kernel zu geben, wird der Beitrag dieser Woche etwas abstrakter als üblich beginnen. Diese Abstraktionsebene ist nicht unbedingt notwendig, um zu verstehen, wie Gaußsche Kerne funktionieren, aber die abstrakte Perspektive kann als Quelle der Intuition äußerst nützlich sein, wenn man versucht, Wahrscheinlichkeitsverteilungen im Allgemeinen zu verstehen. Ich werde also versuchen, die Abstraktion langsam aufzubauen, aber wenn Sie sich einmal hoffnungslos verirrt haben oder es einfach nicht mehr aushalten, können Sie zu der fettgedruckten Überschrift „Der praktische Teil“ springen – dort werde ich zu einer konkreteren Beschreibung des Gauß-Kern-Algorithmus übergehen. Wenn Sie immer noch Probleme haben, machen Sie sich keine Sorgen – die meisten späteren Beiträge in diesem Blog setzen nicht voraus, dass Sie den Gaußschen Kernel verstehen, Sie können also einfach auf den Beitrag von nächster Woche warten (oder ihn überspringen, wenn Sie diesen Beitrag später lesen).
Erinnern Sie sich daran, dass ein Kernel eine Möglichkeit ist, einen Datenraum in einen höherdimensionalen Vektorraum zu bringen, so dass die Schnittpunkte des Datenraums mit Hyperebenen im höherdimensionalen Raum kompliziertere, gekrümmte Entscheidungsgrenzen im Datenraum bestimmen. Das wichtigste Beispiel, das wir uns angesehen haben, war der Kernel, der einen zweidimensionalen Datenraum in einen fünfdimensionalen Raum überträgt, indem er jeden Punkt mit den Koordinaten 


In dieser Woche gehen wir über höherdimensionale Vektorräume hinaus zu unendlich-dimensionalen Vektorräumen. Sie können sehen, dass der neundimensionale Kernel oben eine Erweiterung des fünfdimensionalen Kernels ist – wir haben im Grunde nur vier weitere Dimensionen am Ende angehängt. Wenn wir auf diese Weise immer mehr Dimensionen anhängen, erhalten wir immer höherdimensionale Kerne. Wenn wir dies „ewig“ tun würden, hätten wir am Ende unendlich viele Dimensionen. Beachten Sie, dass wir dies nur abstrakt tun können. Computer können nur mit endlichen Dingen umgehen, also können sie keine Berechnungen in unendlich dimensionalen Vektorräumen speichern und verarbeiten. Aber wir tun eine Minute lang so, als ob wir das könnten, um zu sehen, was passiert. Dann übertragen wir die Dinge zurück in die endliche Welt.
In diesem hypothetischen unendlichdimensionalen Vektorraum können wir Vektoren auf die gleiche Weise addieren, wie wir es mit normalen Vektoren tun, indem wir einfach die entsprechenden Koordinaten hinzufügen. In diesem Fall müssen wir jedoch unendlich viele Koordinaten addieren. Auf ähnliche Weise können wir mit Skalaren multiplizieren, indem wir jede der (unendlich vielen) Koordinaten mit einer bestimmten Zahl multiplizieren. Wir definieren den unendlichen Polynomkern, indem wir jeden Punkt 

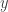


Um in die rechnerische Welt zurückzukehren, können wir unseren ursprünglichen fünfdimensionalen Kern wiederherstellen, indem wir einfach alle Einträge außer den ersten fünf vergessen. In der Tat ist der ursprüngliche fünfdimensionale Raum in diesem unendlichen Raum enthalten. (Der ursprüngliche fünfdimensionale Kern ist das, was wir erhalten, wenn wir den unendlichen Polynomkern in diesen fünfdimensionalen Raum projizieren.)
Nun atmen Sie tief durch, denn wir werden einen Schritt weiter gehen. Überlegen Sie einen Moment lang, was ein Vektor ist. Wenn Sie jemals einen Kurs in linearer Algebra besucht haben, erinnern Sie sich vielleicht daran, dass Vektoren offiziell durch ihre Additions- und Multiplikationseigenschaften definiert sind. Aber ich werde das jetzt mal ignorieren (mit einer Entschuldigung an alle Mathematiker, die das hier lesen.) In der Welt der Informatik stellen wir uns einen Vektor normalerweise als eine Liste von Zahlen vor. Wenn Sie bis hierher gelesen haben, sind Sie vielleicht bereit, diese Liste als unendlich zu betrachten. Ich möchte jedoch, dass Sie sich einen Vektor als eine Sammlung von Zahlen vorstellen, in der jede Zahl einer bestimmten Sache zugewiesen ist. Zum Beispiel ist jede Zahl in unserem üblichen Vektor einer der Koordinaten/Merkmale zugeordnet. In einem unserer unendlichen Vektoren ist jede Zahl einem Punkt in unserer unendlich langen Liste zugeordnet.
Aber wie wäre es damit: Was würde passieren, wenn wir einen Vektor definieren, indem wir jedem Punkt in unserem (endlich dimensionalen) Datenraum eine Zahl zuordnen? Ein solcher Vektor wählt nicht einen einzigen Punkt im Datenraum aus; vielmehr gibt der Vektor eine Zahl an, wenn man auf einen beliebigen Punkt im Datenraum zeigt. Nun, eigentlich haben wir bereits einen Namen dafür: Etwas, das jedem Punkt im Datenraum eine Zahl zuweist, ist eine Funktion. Wir haben uns in diesem Blog schon oft mit Funktionen befasst, und zwar in Form von Dichtefunktionen, die Wahrscheinlichkeitsverteilungen definieren. Aber der Punkt ist, dass wir uns diese Dichtefunktionen als Vektoren in einem unendlich-dimensionalen Vektorraum vorstellen können.
Wie kann eine Funktion ein Vektor sein? Nun, wir können zwei Funktionen addieren, indem wir einfach ihre Werte an jedem Punkt addieren. Dies war das erste Schema, das wir in der letzten Woche im Beitrag über Mischungsmodelle für die Kombination von Verteilungen besprochen haben. Die Dichtefunktionen für zwei Vektoren (Gaußsche Flecken) und das Ergebnis ihrer Addition sind in der folgenden Abbildung dargestellt. In ähnlicher Weise können wir eine Funktion mit einer Zahl multiplizieren, was dazu führt, dass die Gesamtdichte heller oder dunkler wird. Beides sind Operationen, mit denen Sie im Algebraunterricht und in der Infinitesimalrechnung wahrscheinlich schon viel Übung hatten. Wir machen also noch nichts Neues, wir denken nur auf eine andere Art und Weise über die Dinge nach.

Der nächste Schritt besteht darin, einen Kernel von unserem ursprünglichen Datenraum in diesen unendlich dimensionalen Raum zu definieren, und hier haben wir eine Menge Auswahlmöglichkeiten. Eine der gebräuchlichsten Möglichkeiten ist die Gaußsche Blob-Funktion, die wir in früheren Beiträgen schon einige Male gesehen haben. Für diesen Kernel wählen wir eine Standardgröße für die Gaußschen Kleckse, d. h. einen festen Wert für die Abweichung 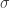
Jetzt kommt das Problem: Um die Dinge in die rechnerische Welt zurückzubringen, müssen wir einen endlichdimensionalen Vektorraum in diesem unendlichdimensionalen Vektorraum auswählen und den unendlichdimensionalen Raum in den endlichdimensionalen Unterraum „projizieren“. Wir wählen einen endlichdimensionalen Raum, indem wir eine (endliche) Anzahl von Punkten im Datenraum auswählen und dann den Vektorraum nehmen, der von den Gaußschen Flecken aufgespannt wird, die in diesen Punkten zentriert sind. Dies ist das Äquivalent zu den Vektoren, die durch die ersten fünf Koordinaten des unendlichen Polynomkerns definiert sind, wie oben beschrieben. Die Wahl dieser Punkte ist wichtig, aber wir werden später darauf zurückkommen. Für den Moment stellt sich die Frage, wie wir projizieren?
Für endlich dimensionale Vektoren ist die gebräuchlichste Art, eine Projektion zu definieren, die Verwendung des Punktprodukts: Das ist die Zahl, die man erhält, wenn man die entsprechenden Koordinaten von zwei Vektoren multipliziert und dann addiert. So lautet beispielsweise das Punktprodukt der dreidimensionalen Vektoren 


Wir können etwas Ähnliches mit Funktionen machen, indem wir die Werte multiplizieren, die sie an entsprechenden Punkten im Datensatz annehmen. (Mit anderen Worten, wir multiplizieren die beiden Funktionen miteinander.) Aber wir können dann nicht alle diese Zahlen addieren, weil es unendlich viele von ihnen gibt. Stattdessen werden wir ein Integral bilden! (Beachten Sie, dass ich hier eine Menge Details ausblende, und ich entschuldige mich nochmals bei allen Mathematikern, die dies lesen). Das Schöne daran ist, dass die Multiplikation zweier Gauß-Funktionen und die Integration eine Gauß-Funktion des Abstands zwischen den Mittelpunkten ergibt. (Allerdings wird die neue Gauß-Funktion einen anderen Abweichungswert haben.)
Mit anderen Worten, der Gauß-Kernel verwandelt das Punktprodukt im unendlich dimensionalen Raum in die Gauß-Funktion des Abstands zwischen Punkten im Datenraum: Wenn zwei Punkte im Datenraum nahe beieinander liegen, ist der Winkel zwischen den Vektoren, die sie im Kernelraum repräsentieren, klein. Wenn die Punkte weit voneinander entfernt sind, dann sind die entsprechenden Vektoren nahezu „senkrecht“.
Der praktische Teil
So, lassen Sie uns überprüfen, was wir bis jetzt haben: Um einen 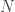
Um besser zu verstehen, wie dieser Kernel funktioniert, wollen wir herausfinden, wie der Schnittpunkt einer Hyperebene mit dem Datenraum aussieht. (Das ist es, was man bei Kerneln sowieso meistens macht.) Eine Ebene wird durch eine Gleichung der Form 


Das ist immer noch ziemlich schwer zu entschlüsseln, also betrachten wir ein Beispiel, bei dem jeder der Werte 

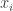





Wenn wir die Parameter
Das gibt uns also mehr Flexibilität bei der Wahl der Entscheidungsgrenze (oder zumindest eine andere Art von Flexibilität), aber das Endergebnis wird sehr stark von den
Eine solche Sammlung von Punkten zu finden, ist ein ganz anderes Problem als das, auf das wir uns in den bisherigen Beiträgen in diesem Blog konzentriert haben, und fällt unter die Kategorie des unüberwachten Lernens/der beschreibenden Analyse. (Im Zusammenhang mit Kernels kann man es auch als Feature-Auswahl/Engineering bezeichnen.) In den nächsten Beiträgen werden wir einen anderen Gang einlegen und beginnen, Ideen in dieser Richtung zu untersuchen.