Du kan selv køre TensorFlow-koden på dette link (eller en PyTorch-version på dette link), eller du kan læse videre for at se koden uden at køre den. Da koden er lidt længere end i de foregående dele, vil jeg kun vise de vigtigste dele her. Hele kildekoden er tilgængelig efter linket ovenfor.
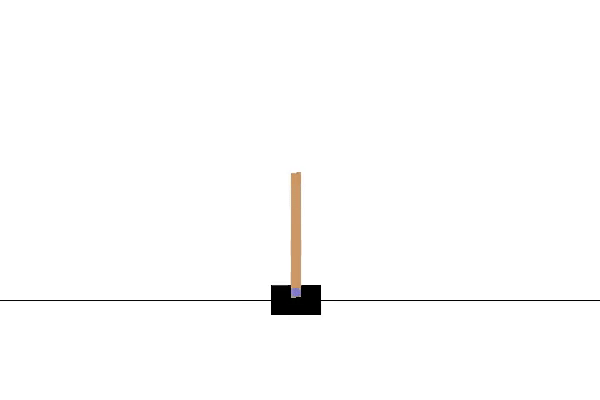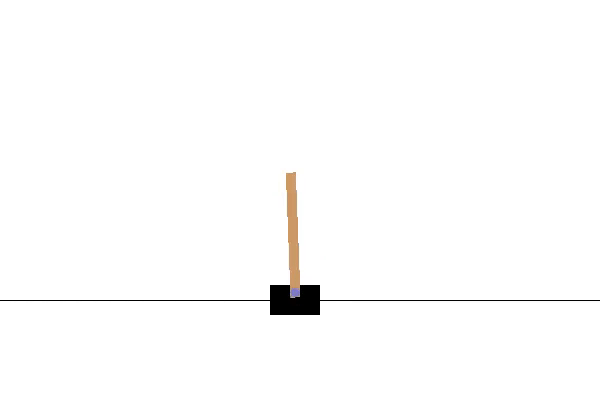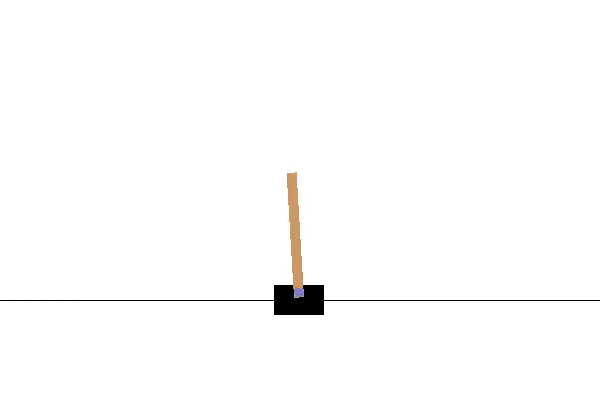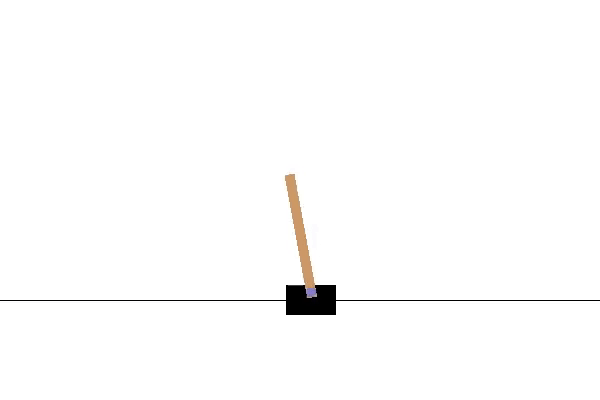
Her er CartPole-miljøet. Jeg bruger OpenAI Gym til at visualisere og køre dette miljø. Målet er at flytte vognen til venstre og højre, for at holde stangen i en lodret position. Hvis stolpens hældning er mere end 15 grader fra den lodrette akse, vil episoden slutte, og vi vil starte forfra. Video 1 viser et eksempel på at køre flere episoder i dette miljø ved at foretage handlinger tilfældigt.
For at implementere DQN-algoritmen starter vi med at oprette DNN’erne main (main_nn) og target (target_nn). Målnetværket vil være en kopi af hovednetværket, men med sin egen kopi af vægtene. Vi får også brug for en optimizer og en tabsfunktion.
Næst vil vi oprette erfaringsgennemspilningsbufferen, for at tilføje erfaringerne til bufferen og prøve dem senere til træning.
Vi vil også skrive en hjælpefunktion til at køre ε-greedy-politikken og til at træne hovednettet ved hjælp af de data, der er gemt i bufferen.
Vi vil også definere de nødvendige hyperparametre, og vi vil træne det neurale netværk. Vi vil afspille en episode ved hjælp af ε-greedy-politikken, gemme dataene i erfaringsgennemspilningsbufferen og træne hovednettet efter hvert trin. Efter hvert 2 000 trin kopierer vi vægtene fra hovednettet til målnettet. Vi vil også mindske værdien af epsilon (ε) for at starte med en høj udforskning og mindske udforskningen over tid. Vi vil se, hvordan algoritmen begynder at lære efter hver episode.
Dette er det resultat, der vil blive vist:
Episode 0/1000. Epsilon: 0.99. Reward in last 100 episodes: 14.0 Episode 50/1000. Epsilon: 0.94. Reward in last 100 episodes: 22.2 Episode 100/1000. Epsilon: 0.89. Reward in last 100 episodes: 23.3 Episode 150/1000. Epsilon: 0.84. Reward in last 100 episodes: 23.4 Episode 200/1000. Epsilon: 0.79. Reward in last 100 episodes: 24.9 Episode 250/1000. Epsilon: 0.74. Reward in last 100 episodes: 30.4 Episode 300/1000. Epsilon: 0.69. Reward in last 100 episodes: 38.4 Episode 350/1000. Epsilon: 0.64. Reward in last 100 episodes: 51.4 Episode 400/1000. Epsilon: 0.59. Reward in last 100 episodes: 68.2 Episode 450/1000. Epsilon: 0.54. Reward in last 100 episodes: 82.4 Episode 500/1000. Epsilon: 0.49. Reward in last 100 episodes: 102.1 Episode 550/1000. Epsilon: 0.44. Reward in last 100 episodes: 129.7 Episode 600/1000. Epsilon: 0.39. Reward in last 100 episodes: 151.7 Episode 650/1000. Epsilon: 0.34. Reward in last 100 episodes: 173.0 Episode 700/1000. Epsilon: 0.29. Reward in last 100 episodes: 187.3 Episode 750/1000. Epsilon: 0.24. Reward in last 100 episodes: 190.9 Episode 800/1000. Epsilon: 0.19. Reward in last 100 episodes: 194.6 Episode 850/1000. Epsilon: 0.14. Reward in last 100 episodes: 195.9 Episode 900/1000. Epsilon: 0.09. Reward in last 100 episodes: 197.9 Episode 950/1000. Epsilon: 0.05. Reward in last 100 episodes: 200.0 Episode 1000/1000. Epsilon: 0.05. Reward in last 100 episodes: 200.0
Nu da agenten har lært at maksimere belønningen for CartPole-miljøet, vil vi få agenten til at interagere med miljøet en gang mere for at visualisere resultatet og se, at den nu er i stand til at holde stangen i balance i 200 frames.

Du kan selv køre TensorFlow-koden i dette link (eller en PyTorch-version i dette link).