InterPro indeholder tre hovedenheder: proteiner, signaturer (også omtalt som “metoder” eller “modeller”) og poster. Proteinerne i UniProtKB er også de centrale proteinentiteter i InterPro. Oplysninger om, hvilke signaturer der i væsentlig grad matcher disse proteiner, beregnes, efterhånden som sekvenserne frigives af UniProtKB, og disse resultater gøres tilgængelige for offentligheden (se nedenfor). Det er signaturernes match med proteinerne, der afgør, hvordan signaturerne integreres sammen i InterPro-posterne: sammenlignende overlapning af matchede proteinsæt og placeringen af signaturernes match på sekvenserne anvendes som indikatorer for beslægtethed. Kun signaturer, der anses for at være af tilstrækkelig kvalitet, integreres i InterPro. I version 81.0 (frigivet den 21. august 2020) annoterede InterPro-posterne 73,9 % af de rester, der findes i UniProtKB, med yderligere 9,2 % annoteret af signaturer, der er under integration.

InterPro indeholder også data for splejsningsvarianter og de proteiner, der er indeholdt i UniParc- og UniMES-databaserne.
InterPro-konsortiets medlemsdatabaserRediger
Signaturerne fra InterPro kommer fra 13 “medlemsdatabaser”, som er opført nedenfor.
CATH-Gene3D Beskriver proteinfamilier og domænearkitekturer i komplette genomer. Proteinfamilier dannes ved hjælp af en Markov-klyngealgoritme efterfulgt af multi-linkage-klumpning i henhold til sekvensidentitet. Kortlægning af forudsagte struktur- og sekvensdomæner foretages ved hjælp af skjulte Markov-modelbiblioteker, der repræsenterer CATH- og Pfam-domæner. Proteinerne forsynes med funktionelle annotationer fra flere ressourcer. Funktionel forudsigelse og analyse af domænearkitekturer er tilgængelig fra Gene3D-webstedet. CDD Conserved Domain Database er en ressource til annotering af proteiner, som består af en samling af annoterede modeller for flere sekvenstilpasningsmodeller for gamle domæner og proteiner i fuld længde. Disse er tilgængelige som positionsspecifikke scorematricer (PSSM’er) til hurtig identifikation af konserverede domæner i proteinsekvenser via RPS-BLAST. HAMAP står for High-quality Automated and Manual Annotation of microbial Proteomes (automatiseret og manuel annotation af mikrobielle proteomer af høj kvalitet). HAMAP-profiler oprettes manuelt af ekspertkuratorer, som identificerer proteiner, der indgår i velkonserverede bakterielle, arkæale og plastidkodede (dvs. kloroplaster, cyaneller, apikoplaster, ikke-fotosyntetiske plastider) proteinfamilier eller -underfamilier. MobiDB MobiDB er en database til annotering af intrinsisk uorden i proteiner. PANTHER PANTHER er en stor samling af proteinfamilier, der er blevet opdelt i funktionelt beslægtede underfamilier ved hjælp af menneskelig ekspertise. Disse underfamilier modellerer divergensen af specifikke funktioner inden for proteinfamilier, hvilket giver mulighed for en mere nøjagtig tilknytning til funktionen (menneskeligt kuraterede molekylære funktions- og biologiske procesklassifikationer og vejdiagrammer) og for at udlede aminosyrer, der er vigtige for den funktionelle specificitet. Der opbygges skjulte Markov-modeller (HMM’er) for hver familie og underfamilie med henblik på klassificering af yderligere proteinsekvenser. Pfam Er en stor samling af multiple sekvenstilpasninger og skjulte Markov-modeller, der dækker mange almindelige proteindomæner og -familier.
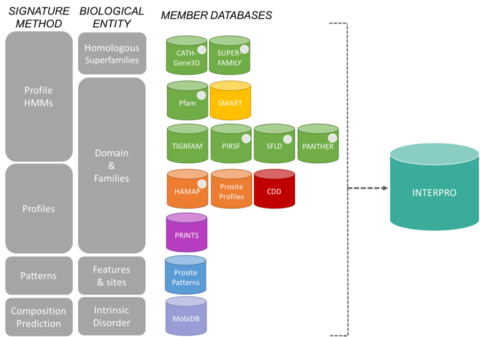
PIRSF Proteinklassifikationssystemet er et netværk med flere niveauer af sekvensdiversitet fra superfamilier til underfamilier, der afspejler det evolutionære forhold mellem fuldlængdeproteiner og domæner. Den primære PIRSF-klassifikationsenhed er den homeomorfe familie, hvis medlemmer både er homologe (udviklet fra en fælles forfader) og homeomorfe (deler lighed i sekvensen i fuld længde og har en fælles domænearkitektur). PRINTS PRINTS er et kompendium af proteinfingeraftryk. Et fingeraftryk er en gruppe af bevarede motiver, der anvendes til at karakterisere en proteinfamilie; dets diagnostiske effekt forfines ved iterativ scanning af UniProt. Normalt overlapper motiverne ikke hinanden, men er adskilt langs en sekvens, selv om de kan være sammenhængende i 3D-rummet. Fingeraftryk kan kode for proteinfolder og funktionaliteter på en mere fleksibel og effektiv måde end enkeltmotiver, idet deres fulde diagnostiske styrke stammer fra den gensidige kontekst, som motivnaboerne giver dem. PROSITE PROSITE er en database over proteinfamilier og -domæner. Den består af biologisk betydningsfulde steder, mønstre og profiler, som hjælper med at identificere pålideligt, hvilken kendt proteinfamilie (hvis nogen) en ny sekvens tilhører. SMART Simple Modular Architecture Research Tool Gør det muligt at identificere og annotere genetisk mobile domæner og analysere domænearkitekturer. Mere end 800 domænefamilier, der findes i signalering, ekstracellulære og kromatin-associerede proteiner, kan påvises. Disse domæner er udførligt annoteret med hensyn til fyletisk fordeling, funktionel klasse, tertiærstrukturer og funktionelt vigtige rester. SUPERFAMILIE SUPERFAMILIE er et bibliotek med profiler af skjulte Markov-modeller, der repræsenterer alle proteiner med kendt struktur. Biblioteket er baseret på SCOP-klassifikationen af proteiner: hver model svarer til et SCOP-domæne og har til formål at repræsentere hele den SCOP-superfamilie, som domænet tilhører. SUPERFAMILY er blevet brugt til at foretage strukturelle tilknytninger til alle fuldstændigt sekventerede genomer. SFLD En hierarkisk klassifikation af enzymer, der knytter specifikke sekvensstrukturtræk til specifikke kemiske egenskaber. TIGRFAMs TIGRFAMs er en samling af proteinfamilier med kuraterede multiple sekvenstilpasninger, skjulte Markov-modeller (HMM’er) og annotationer, som giver et værktøj til identifikation af funktionelt beslægtede proteiner baseret på sekvenshomologi. De poster, der er “ækvivalenter”, grupperer homologe proteiner, som er konserveret med hensyn til funktion.
DatatyperRediger
InterPro består af syv datatyper, der leveres af forskellige medlemmer af konsortiet:
| Datatatype | Beskrivelse | Bidragydende databaser | |
|---|---|---|---|
| InterPro Entries | Strukturelle og/eller funktionelle domæner af proteiner, der er forudsagt ved hjælp af en eller flere signaturer | Alle 13 medlemsdatabaser | |
| Medlemsdatabasers signaturer | Signaturer fra medlemsdatabaser. Disse omfatter signaturer, der er integreret i InterPro, og dem, der ikke er | Alle 13 medlemsdatabaser | |
| Protein | Proteinsekvenser | UniProtKB (Swiss-Prot og TrEMBL) | |
| Proteom | Samling af proteiner, der tilhører en enkelt organisme | UniProtKB | |
| Struktur | 3-dimensionelle strukturer af proteiner | PDBe | |
| Taxonomi | Taxonomiske oplysninger om proteiner | UniProtKB | |
| Sæt | Grupper af evolutionært beslægtede familier | Pfam, CDD |

InterPro-posttyperRediger
InterPro-posterne kan yderligere opdeles i fem typer:
- Homologous Superfamily (homolog superfamilie): En gruppe af proteiner, der har en fælles evolutionær oprindelse, som det fremgår af deres strukturelle ligheder, selv om deres sekvenser ikke er meget ens. Disse poster leveres specifikt kun af to medlemsdatabaser: CATH-Gene3D og SUPERFAMILY.
- Familie: En gruppe af proteiner, der har en fælles evolutionær oprindelse, som er fastlagt gennem strukturelle ligheder, beslægtede funktioner eller sekvenshomologi.
- Domæne: En særskilt enhed i et protein med en særlig funktion, struktur eller sekvens.
- Repeat: En sekvens af aminosyrer, normalt ikke længere end 50 aminosyrer, der har tendens til at gentage sig mange gange i et protein.
- Site: En kort sekvens af aminosyrer, hvor mindst én aminosyre er bevaret. Disse omfatter posttranslationsmodifikationssteder, konserverede steder, bindingssteder og aktive steder.