For at give en ordentlig introduktion til Gaussiske kerner, vil denne uges indlæg starte lidt mere abstrakt end normalt. Dette abstraktionsniveau er ikke strengt nødvendigt for at forstå, hvordan Gaussian kernels fungerer, men det abstrakte perspektiv kan være yderst nyttigt som en kilde til intuition, når man forsøger at forstå sandsynlighedsfordelinger i almindelighed. Så sådan her er det: Jeg vil forsøge at opbygge abstraktionen langsomt, men hvis du nogensinde bliver håbløst fortabt eller bare ikke kan holde det ud længere, kan du springe ned til overskriften, hvor der står “Den praktiske del” med fed skrift – Det er der, jeg skifter til en mere konkret beskrivelse af Gaussian kernel-algoritmen. Hvis du stadig har problemer, skal du heller ikke bekymre dig for meget – De fleste af de senere indlæg på denne blog vil ikke kræve, at du forstår Gaussian kernels, så du kan bare vente til næste uges indlæg (eller springe til det, hvis du læser dette senere).
Husk, at en kerne er en måde at placere et datarum i et højere dimensionelt vektorrum på, så skæringspunkterne mellem datarummet og hyperplaner i det højere dimensionelle rum bestemmer mere komplicerede, krumme beslutningsgrænser i datarummet. Det vigtigste eksempel, som vi så på, var den kerne, der sender et todimensionelt datarum til et femdimensionelt rum ved at sende hvert punkt med koordinaterne 


I denne uge vil vi gå videre fra højere dimensionelle vektorrum til uendeligt dimensionelle vektorrum. Du kan se, hvordan den ni-dimensionelle kerne ovenfor er en udvidelse af den fem-dimensionelle kerne – vi har i det væsentlige bare hæftet fire dimensioner mere på i slutningen. Hvis vi bliver ved med at tilføje flere dimensioner på denne måde, vil vi få højere og højere dimensionelle kerner. Hvis vi skulle blive ved med at gøre dette “for evigt”, ville vi ende med uendeligt mange dimensioner. Bemærk, at vi kun kan gøre dette i abstrakt form. Computere kan kun håndtere begrænsede ting, så de kan ikke lagre og behandle beregninger i uendeligt dimensionelle vektorrum. Men vi lader et øjeblik som om, at vi kan, bare for at se, hvad der sker. Derefter oversætter vi tingene tilbage til den finitte verden.
I dette hypotetiske uendeligt-dimensionelle vektorrum kan vi tilføje vektorer på samme måde, som vi gør med almindelige vektorer, ved blot at tilføje tilsvarende koordinater. I dette tilfælde er vi imidlertid nødt til at tilføje uendeligt mange koordinater. På samme måde kan vi multiplicere med skalarer ved at multiplicere hver af de (uendeligt mange) koordinater med et givet tal. Vi definerer den uendelige polynomiekern ved at sende hvert punkt 

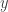


For at komme tilbage til den beregningsmæssige verden kan vi genfinde vores oprindelige femdimensionelle kerne ved blot at glemme alle posterne undtagen de første fem af dem. Faktisk er det oprindelige femdimensionelle rum indeholdt i dette uendeligt dimensionelle rum. (Den oprindelige femdimensionelle kerne er det, vi får ved at projicere den uendelige polynomiske kerne ind i dette femdimensionelle rum.)
Tag nu en dyb indånding, for vi vil tage dette et skridt videre. Overvej for et øjeblik, hvad en vektor er. Hvis du nogensinde har fulgt et kursus i matematisk lineær algebra, kan du måske huske, at vektorer officielt er defineret ud fra deres additions- og multiplikationsegenskaber. Men det vil jeg midlertidigt ignorere (med undskyldning til alle matematikere, der læser dette.) I computerverdenen tænker vi normalt på en vektor som en liste af tal. Hvis du har læst så langt, er du måske villig til at lade denne liste være uendelig. Men jeg vil have dig til at tænke på en vektor som værende en samling tal, hvor hvert tal er tildelt en bestemt ting. F.eks. er hvert tal i vores sædvanlige vektortype tildelt en af koordinaterne/featurerne. I en af vores uendelige vektorer er hvert tal tildelt et sted i vores uendeligt lange liste.
Men hvad med dette: Hvad ville der ske, hvis vi definerede en vektor ved at tildele et tal til hvert punkt i vores (endeligt dimensionelle) datarum? En sådan vektor udvælger ikke et enkelt punkt i datarummet; når du først har valgt denne vektor, fortæller vektoren dig snarere et tal, hvis du peger på et hvilket som helst punkt i datarummet. Vi har faktisk allerede et navn for det: Noget, der tildeler et tal til hvert punkt i datarummet, er en funktion. Faktisk har vi kigget meget på funktioner på denne blog, i form af tæthedsfunktioner, der definerer sandsynlighedsfordelinger. Men pointen er, at vi kan tænke på disse tæthedsfunktioner som vektorer i et uendeligt-dimensionelt vektorrum.
Hvordan kan en funktion være en vektor? Jo, vi kan addere to funktioner ved blot at lægge deres værdier i hvert punkt sammen. Dette var den første ordning, vi diskuterede for at kombinere fordelinger i sidste uges indlæg om blandingsmodeller. Tæthedsfunktionerne for to vektorer (Gaussian blobs) og resultatet af at lægge dem sammen er vist i figuren nedenfor. Vi kan multiplicere en funktion med et tal på lignende måde, hvilket vil resultere i at gøre den samlede tæthed lysere eller mørkere. Faktisk er det begge operationer, som du sikkert har haft masser af øvelse i i algebraundervisningen og regneøvelserne. Så vi gør ikke noget nyt endnu, vi tænker bare på tingene på en anden måde.

Det næste skridt er at definere en kerne fra vores oprindelige datarum til dette uendeligt dimensionelle rum, og her har vi en masse valgmuligheder. Et af de mest almindelige valg er den Gaussiske blob-funktion, som vi har set et par gange i tidligere indlæg. For denne kerne vælger vi en standardstørrelse for de gaussiske blobs, dvs. en fast værdi for afvigelsen 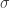
Nu er problemet her: For at bringe tingene tilbage til den beregningsmæssige verden skal vi udvælge et finite dimensionelt vektorrum, der sidder i dette uendelige dimensionelle vektorrum, og “projicere” det uendelige dimensionelle rum ind i det finite dimensionelle underrum. Vi vælger et finit-dimensionelt rum ved at vælge et (endeligt) antal punkter i datarummet og derefter tage det vektorrum, der er opspændt af de gaussiske klatter, der er centreret på dette punkt. Dette svarer til vektortempoet defineret af de første fem koordinater i den uendelige polynomiekernel, som ovenfor. Valget af disse punkter er vigtigt, men det vender vi tilbage til senere. For nu er spørgsmålet, hvordan vi projicerer?
For endeligt dimensionelle vektorer er den mest almindelige måde at definere en projektion på ved hjælp af prikproduktet: Dette er det tal, som vi får ved at gange de tilsvarende koordinater for to vektorer og derefter lægge dem sammen. Så for eksempel er prikproduktet af de tredimensionelle vektorer 


Vi kan gøre noget lignende med funktioner ved at gange de værdier, som de antager på tilsvarende punkter i datasættet. (Med andre ord multiplicerer vi de to funktioner sammen.) Men vi kan så ikke lægge alle disse tal sammen, fordi der er uendeligt mange af dem. I stedet tager vi et integral! (Bemærk, at jeg overdriver et væld af detaljer her, og jeg undskylder igen over for eventuelle matematikere, der læser dette). Det fine her er, at hvis vi multiplicerer to gaussiske funktioner og integrerer, så er tallet lig med en gaussisk funktion af afstanden mellem midtpunkterne. (Selv om den nye gaussiske funktion vil have en anden afvigelsesværdi.)
Med andre ord transformerer den gaussiske kerne prikproduktet i det uendeligt dimensionelle rum til en gaussisk funktion af afstanden mellem punkterne i datarummet: Hvis to punkter i datarummet er nærliggende, vil vinklen mellem de vektorer, der repræsenterer dem i kernelrummet, være lille. Hvis punkterne er langt fra hinanden, vil de tilsvarende vektorer være tæt på “vinkelret”.
Den praktiske del
Så lad os gennemgå, hvad vi har indtil nu: For at definere en 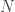
For bedre at forstå, hvordan denne kerne fungerer, skal vi finde ud af, hvordan skæringspunktet mellem en hyperplan og datarummet ser ud. (Det er i hvert fald det, man gør med kerner det meste af tiden.) Husk, at et plan er defineret ved en ligning af formen 


Det er stadig ret svært at pakke ud, så lad os se på et eksempel, hvor hver af værdierne 

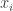





Hvis vi justerer parametrene
Det giver os altså mere fleksibilitet i valget af beslutningsgrænsen (eller i det mindste en anden form for fleksibilitet), men det endelige resultat vil være meget afhængigt af de
Findelse af en sådan samling af punkter er et meget anderledes problem end det, vi har fokuseret på i de hidtidige indlæg på denne blog, og falder ind under kategorien uovervåget indlæring/beskrivende analyse. (I forbindelse med kerner kan det også tænkes som feature selection/engineering). I de næste par indlæg vil vi skifte gear og begynde at udforske idéer i denne retning.