Vrem ca această mașină să genereze de una singură întregul set de date de instruire sau să genereze întregul set de date de instruire pe baza unui indiciu din datele originale. De exemplu, având în vedere o imagine bitmap de indiciu care conține „SCI”, aceasta ar genera „ENCE” pe cont propriu din ponderile pe care le-a învățat.
Pentru a ne face o imagine a sistemului în mintea noastră, considerăm figura 5.
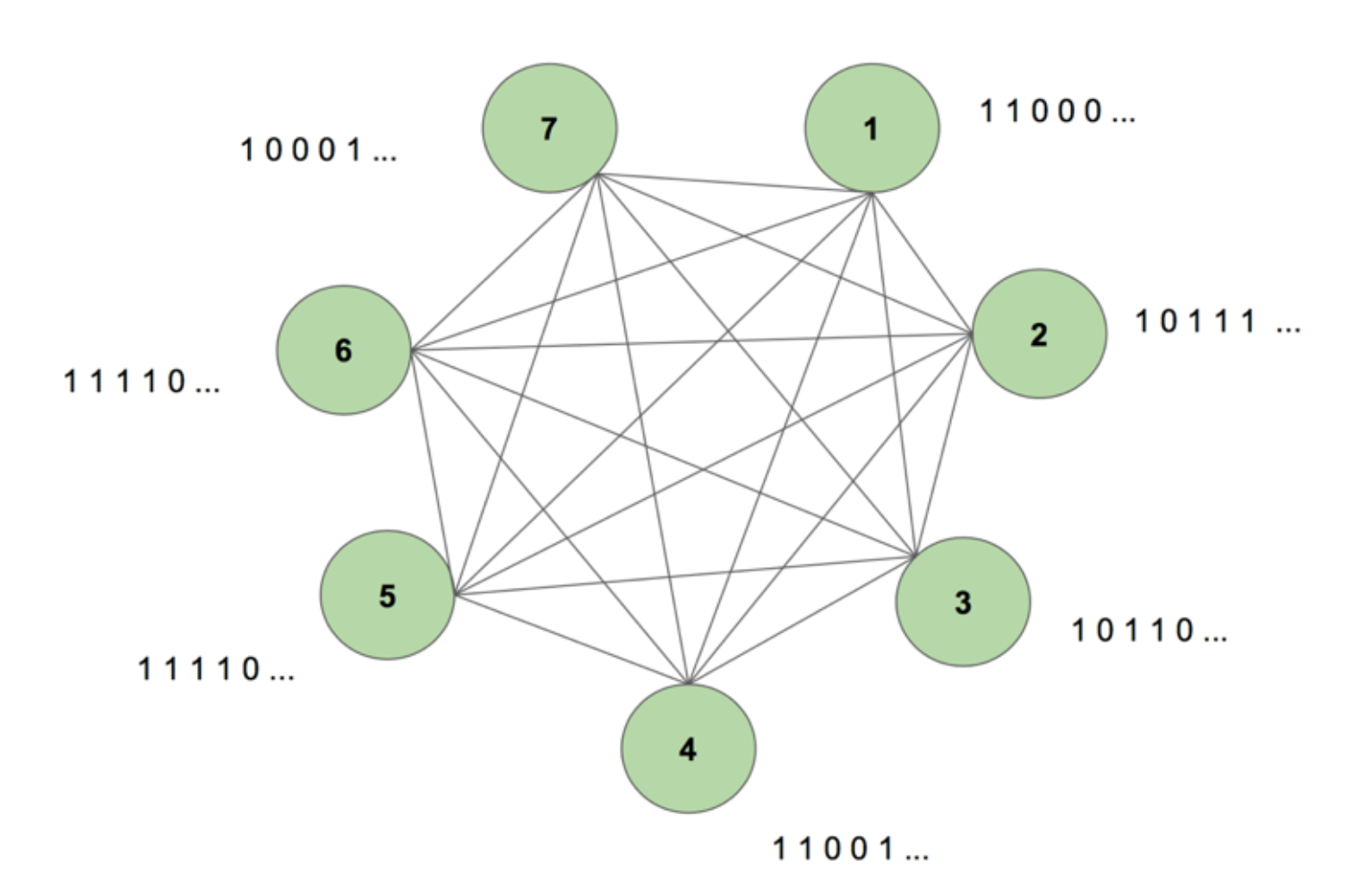
Mașina conține șapte noduri. O imagine bitmap de 7 pe 35 reprezentând cuvântul SCIENCE este secvența țintă. O perioadă de antrenament constă în a arăta mașinii această secvență țintă o singură dată. Ținta este împărțită în 35 de benzi de 7 valori și este introdusă în mașină în aceeași ordine ca și apariția ei în țintă. Figura 5 arată cum ar arăta cinci astfel de benzi de intrare. Vedem că prima bandă a hărții noastre de biți, formată din toți 1, este reflectată în prima valoare a intrărilor nodurilor. Acesta este modul în care introducem valorile în mașină în timpul antrenamentului.
Când inițializăm pentru prima dată mașina cu ponderi arbitrare și îi cerem să genereze o secvență, aceasta creează ceva complet aleatoriu. După ce antrenăm mașina timp de 130.000 de perioade de antrenament, aceasta este capabilă să genereze singură întreaga secvență. Acest lucru înseamnă că, în timpul antrenamentului, își optimizează ponderile pentru a învăța nu doar co-ocurența de biți într-o singură perioadă de timp, ci de-a lungul unei întregi secvențe.
Magiabil, nu-i așa? Dar există o logică solidă în spatele acestui truc magic. Să deslușim misterul și să vedem de ce funcționează această „mașină Boltzmann cu memorie”.

Aceasta este structura unei mașini Boltzmann dinamice (DyBM). Într-o mașină Boltzmann, un nod conține informații cu privire la nodurile care îl activează la un anumit moment în timp. Acest lucru îl face să fie conștient de evenimentele care au loc împreună, dar nu îi oferă capacitatea de a privi înapoi și de a construi asociații în diferite intervale de timp. Însă, în cadrul unui DyBM, conexiunile dintre noduri reprezintă modul în care nodurile interacționează în timp, nu doar la un anumit interval de timp. DyBM facilitează acest lucru prin adăugarea unei întârzieri de conducție între noduri.
Cu această nouă arhitectură, un nod are informații despre care alte noduri au catalizat activarea sa la un anumit interval de timp T = t prin propriile lor activități în intervalele de timp anterioare T = t – 1, T = t – 2 și așa mai departe. Această „memorie” este adăugată unui nod sub forma unei unități de memorie. Această unitate modifică probabilitatea ca un nod să fie activat în orice moment, în funcție de valorile anterioare ale altor noduri și de propriile sale ponderi asociate.
Să considerăm că avem 2 noduri A și B. La un nivel înalt, extindem noțiunea că „neuronii care trag împreună, se conectează împreună” la dimensiunea timpului. De exemplu, să ne imaginăm că activarea lui A conduce în mod constant la activarea lui B după doi timestep-uri. O mașină Boltzmann nedinamică nu poate surprinde acest model, dar cu o DyBM, deoarece valoarea lui A ajunge la B după o anumită întârziere, pot surprinde modelul conform căruia B = 1 la un moment dat după A = 1. Acum, probabilitatea ca B = 1 la pasul de timp T = t va varia nu numai în funcție de valoarea lui A la T = t, ci și în funcție de valorile lui A la T = t – 1, T = t – 2 și așa mai departe, în funcție de valoarea întârzierii de conducție între A și B.
Mașina stochează valorile astfel încât valorilor recente să li se acorde o pondere mai mare, ceea ce are sens deoarece, în general, cele mai recente părți ale unei serii de timp sunt cele mai informative cu privire la cea mai recentă tendință. Un DyBM stochează aceste informații în urmele de eligibilitate. Urma de eligibilitate sinaptică a lui B conține suma ponderată a valorilor care au ajuns la B dinspre A după o anumită întârziere de conducție. Urma de eligibilitate neuronală a lui B conține suma ponderată a valorilor sale trecute.
În mod similar cu rețelele neuronale recurente standard, putem derula DyBM în timp. DyBM desfășurată este o mașină Boltzmann care are un număr infinit de unități, fiecare reprezentând valoarea unui nod la un anumit moment.
Așa, aceasta este mașina Boltzmann dinamică: o arhitectură care are puterea de a recrea datele de instruire nu doar la un moment dat, ci de-a lungul unei secvențe a acestor date.
DyBM-urile sunt fascinante, iar partea care urmează duce punctul de vedere mai departe.
Partea 4: Confruntare între RNN-Gaussian-DyBM și LSTM
Toate exemplele pe care le-am văzut până acum au avut de-a face cu date binare (distribuția Bernoulli). Cercetătorii IBM au făcut un pas mai departe și au creat un DyBM care poate modela distribuții gaussiene și au făcut posibil ca utilizatorii ca noi să modeleze date din serii de timp folosind DyBM și variantele sale.
Pentru a verifica eficiența unui DyBM, am efectuat câteva teste comparând un RNN-Gaussian-DyBM (un DyBM cu strat RNN) și actuala rețea neuronală de ultimă generație, Long Short-Term Memory Neural Network. Rezultatele au fost interesante. Nu ezitați să efectuați aceste teste pe cont propriu, pe baza scriptului disponibil aici.
Să vedem cum se compară o DyBM cu o LSTM pe un caz de utilizare a seriilor de timp.
Caz de utilizare: Predicția valorii următorului număr de pete solare.
Vom folosi date care conțin numărul lunar de pete solare calculat într-un laborator din Zurich din anul 1749 până în 1983. Datele sunt open source și sunt disponibile la Datamarket – Monthly sunspot number, Zurich, 1749-1983.
În primul rând, să vedem cum s-a comportat LSTM.
LSTM
- Arhitectură: LSTM Dimensiunea = 10.
- Performanță pe 10 epoci: Scor mediu de testare LSTM = 0.08877 RMSE
- Pentru fiecare epocă timp de învățare: LSTM = 0.08877 RMSE
- Pentru fiecare epocă timp de învățare: LSTM = 0.08877 RMSE
- : 8.689403 sec.

Acum vom vedea cum s-a comportat un RNN-Gaussian-DyBM pe aceleași date.
Cuprindeți-vă, aceasta va fi o călătorie de descoperire foarte interesantă… Sunteți gata?
RNN-Gaussian-DyBM
- Arhitectură: RNN Dimensiunea = 10 și dimensiunea de intrare = 1
- Performanță pe 10 epoci: Scor mediu de testare LSTM = 0.07848 RMSE
- Pentru fiecare epocă timp de învățare: 0.90547 sec.

Nu numai că RNN-Gaussian-DyBM rulează de 10 ori mai repede în acest caz, dar oferă și performanțe mai bune.
Pe măsură ce mărim numărul de epoci pentru cele două modele, diferența de timp între antrenarea acestor două modele crește drastic. Timpul de răspuns al DyBM este mult mai rapid, astfel încât ciclul instruire – testare – implementare se micșorează și puteți îmbunătăți modelele mult mai rapid.
Dar nu am discutat încă despre cea mai bună parte a DyBM-urilor: Puteți să le accelerați cu accelerarea GPU. Un DyBM care rulează pe un GPU pe IBM Watson Studio Local cu Power AI IBM Cloud Service poate face predicții pentru peste 2000 de serii de timp, fiecare cu o lungime mai mare de 500, în mai puțin de 10 secunde pe epocă. În schimb, un DyBM care rulează pe CPU va avea nevoie de puțin peste 30 de minute pentru a realiza aceeași sarcină. Comparați acest rezultat cu performanța unui LSTM pe CPU din exemplul anterior. Imaginați-vă puterea de calcul pe care o oferă acest lucru. Consultați aici pentru mai multe informații despre accelerarea DyBM-urilor cu ajutorul GPU-urilor. Este demn de remarcat faptul că puteți accelera și LSTM-urile cu GPU-uri, iar comparația performanțelor între un DyBM accelerat și un LSTM accelerat va varia.
Când doriți să rezolvați o problemă de serii temporale, încercați Dynamic Boltzmann Machines. Luați în considerare posibilitatea de a începe cu depozitul IBM Research Tokyo GitHub pentru Dynamic Boltzmann Machines, pe care îl puteți găsi aici.
Vezi mai jos pentru cercetări aprofundate suplimentare despre modelele bazate pe energie, mașinile Boltzmann și mașinile Boltzmann dinamice:
- A Tutorial on Energy-Based Learning – Yann LeCun, Sumit Chopra, Raia Hadsell, Marc’Aurelio Ranzato, and Fu Jie Huang
- Mașini Boltzmann – Geoffrey Hinton
- Mașini Boltzmann și modele bazate pe energie – Takayuki Osogami (IBM Research – Tokyo)
- Șapte neuroni care memorează secvențe de imagini alfabetice prin intermediul spike-ilor.plasticitate dependentă de sincronizare – Takayuki Osogami și Makoto Otsuka
- Nonlinear Dynamic Boltzmann Machines for Time-Series Prediction – Sakyasingha Dasgupta și Takayuki Osogami (IBM Research – Tokyo)
.