El manejo de errores es una parte esencial de RxJs, ya que lo necesitaremos en casi cualquier programa reactivo que escribamos.
El manejo de errores en RxJS es probable que no se entienda tan bien como otras partes de la librería, pero en realidad es bastante sencillo de entender si nos centramos en comprender primero el contrato Observable en general.
En este post, vamos a proporcionar una guía completa que contiene las estrategias de manejo de errores más comunes que necesitarás para cubrir la mayoría de los escenarios prácticos, empezando por lo básico (el contrato Observable).
- Tabla de contenidos
- El Contrato Observable y el Manejo de Errores
- RxJs subscribe y error callbacks
- Ejemplo de comportamiento de finalización
- Limitaciones del manejador de errores subscribe
- El operador catchError
- ¿Cómo funciona catchError?
- ¿Qué ocurre cuando se lanza un error?
- La estrategia Catch and Replace
- La estrategia Catch and Rethrow
- Desglose de Catch y Rethrow
- Usando catchError múltiples veces en una cadena Observable
- El Operador Finalize
- Ejemplo de Operador Finalize
- La estrategia de reintento
- ¿Cuándo reintentar?
- Diagrama de mármol del Operador retryWhen de RxJs
- Desglosando cómo funciona retryWhen
- Creando un Observable de Notificación
- Estrategia de reintento inmediato
- Salida de la consola del reintento inmediato
- Estrategia de reintento retardado
- La función de creación del Observable del temporizador
- El Operador delayWhen
- desglose del Operador delayWhen
- Implementación de la estrategia de reintento retardado
- Estrategia de reintento Salida de la consola
- Repositorio Github en ejecución (con ejemplos de código)
- Conclusiones
Tabla de contenidos
En este post, cubriremos los siguientes temas:
- El contrato Observable y el manejo de errores
- RxJs subscribe y callbacks de error
- El operador catchError
- La estrategia Catch and Replace Strategy
- throwError y la estrategia Catch and Rethrow
- Usar catchError varias veces en una cadena de Observables
- El operador finalize
- El Retry Strategy
- El Operador retryWhen
- Crear un Observable de notificación
- Estrategia de reintento inmediato
- Estrategia de reintento retardado
- El Operador delayWhen Operador
- La función de creación del Observable del temporizador
- Correr el repositorio de Github (con ejemplos de código)
- Conclusiones
Así que sin más preámbulos, ¡comencemos con nuestra inmersión profunda en el manejo de errores de RxJs!
El Contrato Observable y el Manejo de Errores
Para entender el manejo de errores en RxJs, primero tenemos que entender que cualquier flujo dado sólo puede fallar una vez. Esto está definido por el contrato Observable, que dice que un flujo puede emitir cero o más valores.
El contrato funciona así porque es justo como todos los flujos que observamos en nuestro tiempo de ejecución funcionan en la práctica. Las peticiones de red pueden fallar, por ejemplo.
Un flujo también puede completarse, lo que significa que:
- el flujo ha terminado su ciclo de vida sin ningún error
- tras la finalización, el flujo no emitirá más valores
Como alternativa a la finalización, un flujo también puede fallar, lo que significa que:
- el flujo ha terminado su ciclo de vida con un error
- después de lanzar el error, el flujo no emitirá ningún otro valor
Nótese que la finalización o el error son mutuamente excluyentes:
- Si el flujo se completa, no puede fallar después
- Si el flujo falla, no puede completarse después
Nótese también que no hay obligación de que el flujo se complete o falle, esas dos posibilidades son opcionales. Pero sólo una de esas dos puede ocurrir, no las dos.
Esto significa que cuando un flujo en particular falla, no podemos usarlo más, de acuerdo con el contrato Observable. Debes estar pensando en este punto, ¿cómo podemos recuperarnos de un error entonces?
RxJs subscribe y error callbacks
Para ver el comportamiento de manejo de errores de RxJs en acción, vamos a crear un stream y suscribirnos a él. Recordemos que la llamada a subscribe toma tres argumentos opcionales:
- una función manejadora de éxito, que es llamada cada vez que el flujo emite un valor
- una función manejadora de error, que es llamada sólo si ocurre un error. Este manejador recibe el propio error
- una función manejadora de finalización, que es llamada sólo si el flujo se completa
Ejemplo de comportamiento de finalización
Si el flujo no se equivoca, entonces esto es lo que veríamos en la consola:
HTTP response {payload: Array(9)}HTTP request completed.Como podemos ver, este flujo HTTP emite sólo un valor, y luego se completa, lo que significa que no hubo errores.
¿Pero qué pasa si el flujo lanza un error en su lugar? En ese caso, veremos lo siguiente en la consola:

Como podemos ver, el flujo no emitió ningún valor e inmediatamente dio un error. Después del error, no se produjo ninguna finalización.
Limitaciones del manejador de errores subscribe
Manejar los errores usando la llamada subscribe es a veces todo lo que necesitamos, pero este enfoque de manejo de errores es limitado. Usando este enfoque, no podemos, por ejemplo, recuperarnos del error o emitir un valor alternativo que reemplace el valor que esperábamos del backend.
Aprendamos entonces algunos operadores que nos permitirán implementar algunas estrategias de manejo de errores más avanzadas.
El operador catchError
En la programación sincrónica, tenemos la opción de envolver un bloque de código en una cláusula try, atrapar cualquier error que pueda lanzar con un bloque catch y luego manejar el error.
Así es como se ve la sintaxis de catch síncrono:
Este mecanismo es muy potente porque podemos manejar en un solo lugar cualquier error que ocurra dentro del bloque try/catch.
El problema es que en Javascript muchas operaciones son asíncronas, y una llamada HTTP es uno de esos ejemplos donde las cosas ocurren de forma asíncrona.
RxJs nos proporciona algo parecido a esta funcionalidad, a través del Operador RxJs catchError.
¿Cómo funciona catchError?
Como es habitual y como cualquier Operador RxJs, catchError es simplemente una función que recibe un Observable de entrada, y emite un Observable de salida.
Con cada llamada a catchError, tenemos que pasarle una función a la que llamaremos la función de gestión de errores.
El operador catchError toma como entrada un Observable que puede dar error, y comienza a emitir los valores del Observable de entrada en su Observable de salida.
Si no se produce ningún error, el Observable de salida producido por catchError funciona exactamente igual que el Observable de entrada.
¿Qué ocurre cuando se lanza un error?
Sin embargo, si se produce un error, entonces la lógica de catchError va a entrar en acción. El operador catchError va a tomar el error y pasarlo a la función de manejo de errores.
Se espera que esa función devuelva un Observable que va a ser un Observable de reemplazo para el flujo que acaba de dar error.
Recordemos que el flujo de entrada de catchError ha fallado, por lo que según el contrato de Observable ya no podemos utilizarlo.
Este Observable de reemplazo va a ser suscrito y sus valores van a ser utilizados en lugar del Observable de entrada que ha fallado.
La estrategia Catch and Replace
Demos un ejemplo de cómo catchError se puede utilizar para proporcionar un Observable de reemplazo que emita valores de retorno:
Desglosemos la implementación de la estrategia catch and replace:
- estamos pasando al operador catchError una función, que es la función de manejo de errores
- la función de manejo de errores no se llama inmediatamente, y en general, no se suele llamar
- sólo cuando se produce un error en el Observable de entrada de catchError, se llamará a la función de manejo de errores
- si se produce un error en el flujo de entrada, esta función devuelve entonces un Observable construido con la función
of() - la función
of()construye un Observable que emite un solo valor () y luego completa - la función de manejo de errores devuelve el Observable de recuperación (
of()), que es suscrito por el operador catchError - los valores del Observable de recuperación son entonces emitidos como valores de reemplazo en el Observable de salida devuelto por catchError
¡Como resultado final, el Observable http$ ya no dará error! Este es el resultado que obtenemos en la consola:
HTTP response HTTP request completed.Como podemos ver, el callback de manejo de errores en subscribe() ya no es invocado. En su lugar, esto es lo que ocurre:
- se emite el valor vacío del array
- el Observable
http$se completa
Como podemos ver, el Observable de reemplazo se utilizó para proporcionar un valor de retorno por defecto () a los suscriptores de http$, a pesar de que el Observable original dio error.
¡Nótese que también podríamos haber añadido algún manejo local de errores, antes de devolver el Observable de reemplazo!
Y esto cubre la estrategia Catch and Replace, ahora vamos a ver cómo podemos también utilizar catchError para volver a lanzar el error, en lugar de proporcionar valores fallback.
La estrategia Catch and Rethrow
Empecemos por notar que el Observable de reemplazo proporcionado a través de catchError puede también fallar, al igual que cualquier otro Observable.
Y si eso ocurre, el error se propagará a los suscriptores del Observable de salida de catchError.
Este comportamiento de propagación de errores nos da un mecanismo para volver a lanzar el error capturado por catchError, después de manejar el error localmente. Podemos hacerlo de la siguiente manera:
Desglose de Catch y Rethrow
Desglosemos paso a paso la implementación de la estrategia Catch y Rethrow:
- Al igual que antes, estamos atrapando el error, y devolviendo un Observable de reemplazo
- pero esta vez, en lugar de proporcionar un valor de salida de reemplazo como
, ahora estamos manejando el error localmente en la función catchError - en este caso, simplemente estamos registrando el error en la consola, pero en su lugar podríamos añadir cualquier lógica de manejo de errores local que queramos, como por ejemplo mostrar un mensaje de error al usuario
- Entonces estamos devolviendo un Observable de reemplazo que esta vez fue creado usando throwError
- throwError crea un Observable que nunca emite ningún valor. En su lugar, se produce un error inmediatamente utilizando el mismo error capturado por catchError
- esto significa que el Observable de salida de catchError también se equivocará con el mismo error exacto lanzado por la entrada de catchError
- esto significa que hemos conseguido volver a lanzar con éxito el error lanzado inicialmente por el Observable de entrada de catchError a su Observable de salida
- el error puede ser ahora manejado por el resto de la cadena de Observables, si es necesario
Si ahora ejecutamos el código anterior, este es el resultado que obtenemos en la consola:

Como podemos ver, se ha registrado el mismo error tanto en el bloque catchError como en la función del manejador de errores de la suscripción, como era de esperar.
Usando catchError múltiples veces en una cadena Observable
Nota que podemos usar catchError múltiples veces en diferentes puntos de la cadena Observable si es necesario, y adoptar diferentes estrategias de error en cada punto de la cadena.
Podemos, por ejemplo, atrapar un error arriba en la cadena Observable, manejarlo localmente y volver a lanzarlo, y luego más abajo en la cadena Observable podemos atrapar el mismo error de nuevo y esta vez proporcionar un valor de retorno (en lugar de volver a lanzar):
Si ejecutamos el código anterior, esta es la salida que obtenemos en la consola:
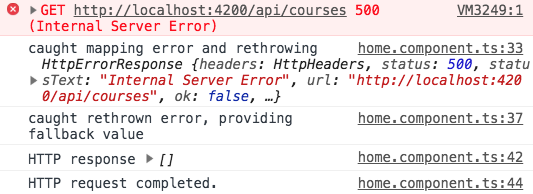
Como podemos ver, el error fue efectivamente re-lanzado inicialmente, pero nunca llegó a la función del manejador de errores de suscripción. En su lugar, se emitió el valor fallback , como era de esperar.
El Operador Finalize
Además de un bloque catch para el manejo de errores, la sintaxis sincrónica de Javascript también proporciona un bloque finally que se puede utilizar para ejecutar el código que siempre queremos que se ejecute.
El bloque finally se suele utilizar para liberar recursos costosos, como por ejemplo cerrar conexiones de red o liberar memoria.
A diferencia del código del bloque catch, el código del bloque finally se ejecutará independientemente de si se lanza un error o no:
RxJs nos proporciona un operador que tiene un comportamiento similar a la funcionalidad finally, llamado Operador finalize.
Nota: no podemos llamarlo operador finally en su lugar, ya que finally es una palabra clave reservada en Javascript
Ejemplo de Operador Finalize
Al igual que el operador catchError, podemos añadir múltiples llamadas a finalize en diferentes lugares de la cadena del Observable si es necesario, para asegurarnos de que los múltiples recursos son liberados correctamente:
Ejecutamos ahora este código, y vemos cómo se ejecutan los múltiples bloques de finalización:

Nota que el último bloque de finalización se ejecuta después de las funciones subscribe value handler y completion handler.
La estrategia de reintento
Como alternativa a volver a lanzar el error o proporcionar valores de retorno, también podemos simplemente volver a intentar suscribirnos al Observable que ha dado error.
Recordemos que una vez que el flujo da error no podemos recuperarlo, pero nada nos impide suscribirnos de nuevo al Observable del que se derivó el flujo, y crear otro flujo.
Así es como funciona esto:
- vamos a tomar el Observable de entrada, y suscribirnos a él, lo que crea un nuevo flujo
- si ese flujo no da error, vamos a dejar que sus valores aparezcan en la salida
- pero si el flujo da error, entonces vamos a suscribirnos de nuevo al Observable de entrada, y crear un flujo completamente nuevo
¿Cuándo reintentar?
La gran pregunta aquí es, ¿cuándo vamos a suscribirnos de nuevo al Observable de entrada, y volver a intentar ejecutar el flujo de entrada?
- ¿Vamos a reintentar eso inmediatamente?
- ¿Vamos a esperar un pequeño retraso, con la esperanza de que el problema se resuelva y luego volver a intentarlo?
- ¿Vamos a reintentar sólo una cantidad limitada de veces, y luego a dar un error en el flujo de salida?
Para responder a estas preguntas, vamos a necesitar un segundo Observable auxiliar, que vamos a llamar Observable Notifier. Es el Notifier
Observable que va a determinar cuándo se produce el intento de reintento.
El Notifier Observable va a ser utilizado por el Operador retryWhen, que es el corazón de la Estrategia de Reintento.
Diagrama de mármol del Operador retryWhen de RxJs
Para entender cómo funciona el Observable retryWhen, vamos a echar un vistazo a su diagrama de mármol:

Nota que el Observable que se está reintentando es el Observable 1-2 de la segunda línea desde arriba, y no el Observable de la primera línea.
El Observable de la primera línea con los valores r-r es el Observable de Notificación, que va a determinar cuándo debe producirse un intento de reintento.
Desglosando cómo funciona retryWhen
Desglosemos lo que ocurre en este diagrama:
- El Observable 1-2 se suscribe, y sus valores se reflejan inmediatamente en el Observable de salida devuelto por retryCuando
- incluso después de que el Observable 1-2 se ha completado, todavía puede ser reintentado
- el Observable de notificación entonces emite un valor
r, el valor emitido por el Observable de notificación (en este casor) podría ser cualquier cosa - lo que importa es el momento en que el valor
rfue emitido, porque eso es lo que va a desencadenar que el Observable 1-2 sea reintentado - el Observable 1-2 es suscrito de nuevo por retryWhen, y sus valores se reflejan de nuevo en el Observable de salida de retryWhen
- El Observable de notificación va a emitir entonces de nuevo otro valor
r, y ocurre lo mismo: los valores de un flujo 1-2 recién suscrito van a empezar a reflejarse en la salida de retryWhen - pero luego, el Observable de notificación termina finalmente
- en ese momento, el intento de reintento en curso del Observable 1-2 se completa antes de tiempo también, lo que significa que sólo el valor 1 se emitió, pero no el 2
¡Como podemos ver, retryWhen simplemente reintenta el Observable de entrada cada vez que el Observable de notificación emite un valor!
Ahora que entendemos cómo funciona retryWhen, vamos a ver cómo podemos crear un Observable de Notificación.
Creando un Observable de Notificación
Necesitamos crear el Observable de Notificación directamente en la función que se pasa al operador retryWhen. Esta función toma como argumento de entrada un Observable de Errores, que emite como valores los errores del Observable de entrada.
Así que suscribiéndonos a este Observable de Errores, sabemos exactamente cuándo se produce un error. Veamos ahora cómo podríamos implementar una estrategia de reintento inmediato utilizando el Observable Errores.
Estrategia de reintento inmediato
Para reintentar el observable fallido inmediatamente después de que se produzca el error, lo único que tenemos que hacer es devolver el Observable Errores sin más cambios.
En este caso, sólo estamos canalizando el operador tap con fines de registro, por lo que el Observable Errors permanece sin cambios:
¡Recordemos que el Observable que estamos devolviendo desde la llamada a la función retryWhen es el Observable Notification!
El valor que emite no es importante, sólo es importante cuando el valor se emite porque eso es lo que va a desencadenar un intento de reintento.
Salida de la consola del reintento inmediato
Si ahora ejecutamos este programa, vamos a encontrar la siguiente salida en la consola:

Como podemos ver, la petición HTTP falló inicialmente, pero luego se intentó un reintento y la segunda vez la petición pasó con éxito.
Veamos ahora el retraso entre los dos intentos, inspeccionando el registro de red:

Como podemos ver, el segundo intento se emitió inmediatamente después de que se produjera el error, como era de esperar.
Estrategia de reintento retardado
Implementemos ahora una estrategia alternativa de recuperación de errores, en la que esperemos, por ejemplo, 2 segundos después de que se produzca el error, antes de reintentarlo.
Esta estrategia es útil para intentar recuperarse de ciertos errores como, por ejemplo, las peticiones de red fallidas causadas por el alto tráfico del servidor.
En aquellos casos en los que el error es intermitente, podemos simplemente reintentar la misma petición después de un breve retraso, y la petición podría pasar la segunda vez sin ningún problema.
La función de creación del Observable del temporizador
Para implementar la estrategia de reintento retardado, necesitaremos crear un Observable de notificación cuyos valores se emitan dos segundos después de cada ocurrencia del error.
Intentemos entonces crear un Observable de notificación utilizando la función de creación del temporizador. Esta función timer va a tomar un par de argumentos:
- un retardo inicial, antes del cual no se emitirán valores
- un intervalo periódico, por si queremos emitir nuevos valores periódicamente
Veamos entonces el diagrama de mármol de la función timer:

Como podemos ver, el primer valor 0 se emitirá sólo después de 3 segundos, y luego tenemos un nuevo valor cada segundo.
Nótese que el segundo argumento es opcional, es decir, que si lo omitimos nuestro Observable va a emitir un solo valor (0) a los 3 segundos y luego se completa.
Este Observable parece un buen comienzo para poder retrasar nuestros intentos de reintento, así que vamos a ver cómo podemos combinarlo con los operadores retryWhen y delayWhen.
El Operador delayWhen
Una cosa importante a tener en cuenta sobre el Operador retryWhen, es que la función que define el Observable de notificación sólo se llama una vez.
Así que sólo tenemos una oportunidad para definir nuestro Observable de Notificación, que señale cuando se deben hacer los intentos de reintento.
Vamos a definir el Observable de Notificación tomando el Observable de Errores y aplicándole el Operador delayWhen.
Imagina que en este diagrama de mármol, el Observable fuente a-b-c es el Observable Errors, que está emitiendo errores HTTP fallidos a lo largo del tiempo:

desglose del Operador delayWhen
Sigamos el diagrama, y aprendamos cómo funciona el Operador delayWhen:
- cada valor en el Observable de Errores de entrada se va a retrasar antes de aparecer en el Observable de salida
- el retraso por cada valor puede ser diferente, y se va a crear de forma totalmente flexible
- para determinar el retraso, vamos a llamar a la función pasada a delayWhen (llamada función selectora de duración) por cada valor de la entrada Errors Observable
- esa función va a emitir un Observable que va a determinar cuándo ha transcurrido el retardo de cada valor de entrada
- cada uno de los valores a-b-c tiene su propio Observable selector de duración, que eventualmente emitirá un valor (que puede ser cualquier cosa) y luego completará
- cuando cada uno de estos Observables selectores de duración emita valores, entonces el valor de entrada correspondiente a-b-c va a aparecer en la salida de delayWhen
- fíjate que el valor
baparece en la salida después del valorc, esto es normal - esto es porque el Observable selector de duración
b(la tercera línea horizontal desde arriba) sólo emitió su valor después del Observable selector de duración dec, y eso explica por quécaparece en la salida antes deb
Implementación de la estrategia de reintento retardado
Ahora pongamos todo esto junto y veamos cómo podemos reintentar consecutivamente una petición HTTP fallida 2 segundos después de que se produzca cada error:
Desglosemos lo que ocurre aquí:
- recordemos que la función pasada a retryWhen sólo va a ser llamada una vez
- estamos devolviendo en esa función un Observable que emitirá valores cada vez que sea necesario un reintento
- cada vez que haya un error, el operador delayWhen va a crear un Observable selector de duración, llamando a la función timer
- este Observable selector de duración va a emitir el valor 0 después de 2 segundos, y luego completará
- una vez que eso ocurra, el Observable delayWhen sabe que el retardo de un determinado error de entrada ha transcurrido
- sólo una vez que ese retardo transcurre (2 segundos después de producirse el error), el error aparece en la salida del Observable de notificación
- una vez que se emite un valor en el Observable de notificación, el operador retryWhen ejecutará entonces y sólo entonces un intento de reintento
Estrategia de reintento Salida de la consola
¡Veamos ahora cómo se ve esto en la consola! Aquí hay un ejemplo de una petición HTTP que fue reintentada 5 veces, ya que las primeras 4 veces dieron error:

Y aquí está el registro de red para la misma secuencia de reintentos:

¡Como podemos ver, los reintentos sólo ocurrieron 2 segundos después de que se produjera el error, como se esperaba!
Y con esto, hemos completado nuestra visita guiada a algunas de las estrategias de manejo de errores de RxJs más comúnmente utilizadas disponibles, ahora vamos a envolver las cosas y proporcionar un poco de código de ejemplo en ejecución.
Repositorio Github en ejecución (con ejemplos de código)
Para probar estas múltiples estrategias de manejo de errores, es importante tener un playground en funcionamiento donde se pueda probar el manejo de peticiones HTTP fallidas.
Este playground contiene una pequeña aplicación en ejecución con un backend que se puede utilizar para simular errores HTTP de forma aleatoria o sistemática. Este es el aspecto de la aplicación:

Conclusiones
Como hemos visto, entender el manejo de errores de RxJs consiste en entender primero los fundamentos del contrato Observable.
Tenemos que tener en cuenta que cualquier flujo dado sólo puede fallar una vez, y eso es excluyente con la finalización del flujo; sólo una de las dos cosas puede suceder.
Para recuperarse de un error, la única forma es generar de alguna manera un stream de reemplazo como alternativa al stream que ha dado error, como ocurre en el caso de los operadores catchError o retryWhen.
Espero que hayáis disfrutado de este post, si queréis aprender mucho más sobre RxJs, os recomendamos que consultéis el curso RxJs In Practice, donde se cubren muchos patrones y operadores útiles con mucho más detalle.