この機械に学習データセット全体を自力で生成させたり、元データからの手がかりを元に学習データセット全体を生成させたりしたいのです。 例えば、「SCI」を含むキューのビットマップ画像があれば、学習した重みから「ENCE」を自力で生成する。
頭の中でシステムのイメージをつかむために、図5を考える。
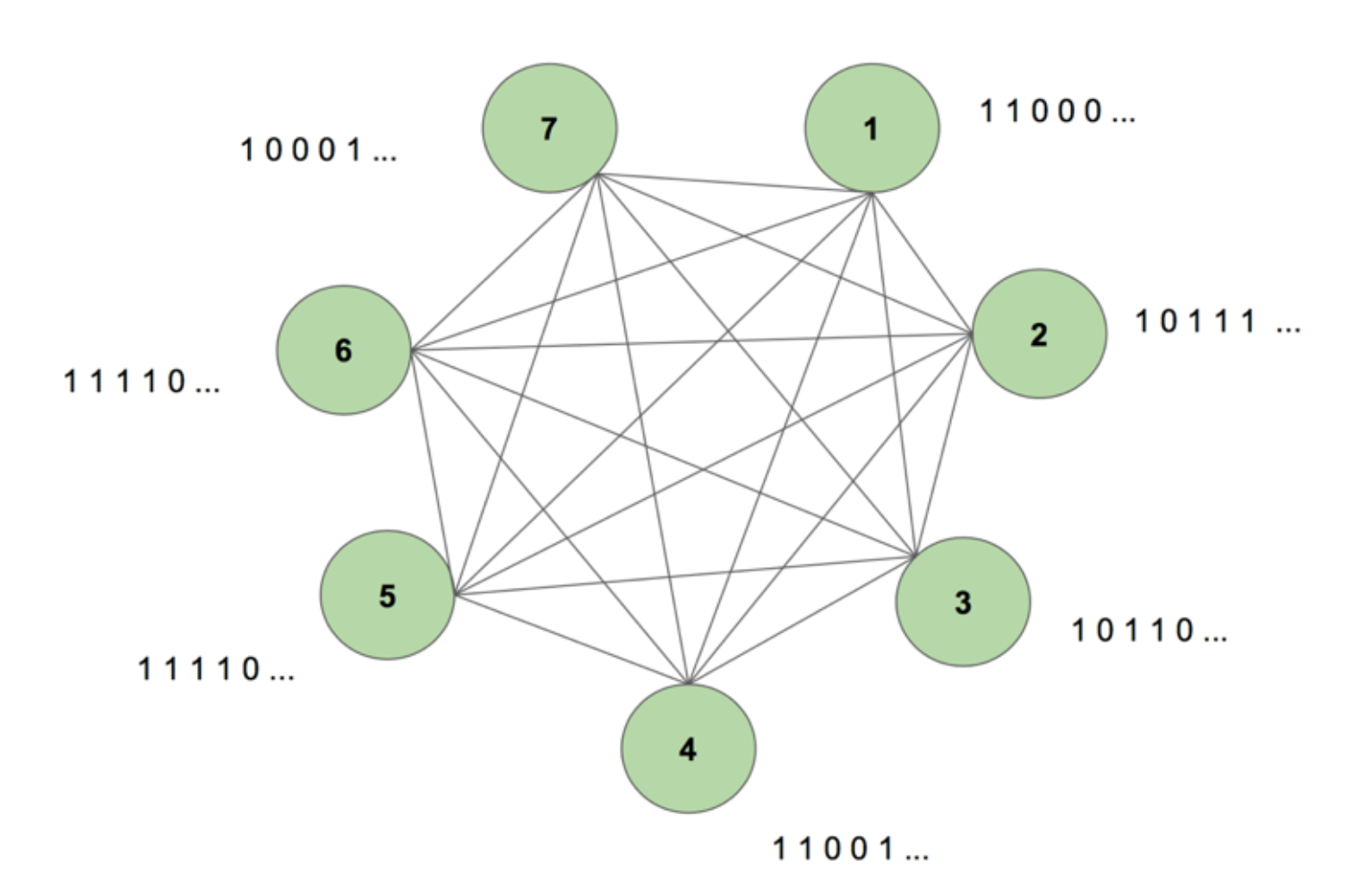
機械には7ノードがある。 SCIENCEという単語を表す7×35のビットマップ画像がターゲットシーケンスである。 1回の学習期間は、この目標列を機械に1回見せるだけである。 ターゲットは7つの値からなる35の短冊に分解され、ターゲットに現れるのと同じ順序で機械に送り込まれる。 図5はそのような5つの入力短冊がどのように見えるかを示している。 すべての1からなるビットマップの最初の短冊が、ノードの入力の最初の値に反映されていることがわかる。
最初に任意の重みで機械を初期化し、シーケンスを生成するよう依頼すると、完全にランダムなものが生成される。 しかし、13万回の学習期間を経て、機械は全シーケンスを自力で生成できるようになった。 つまり、学習中に重みを最適化し、1つのタイムステップにおけるビットの共起関係だけでなく、シーケンス全体にわたって学習しているのです。 しかし、このマジックの裏にはしっかりとしたロジックがあるのです。

これは Dynamic Boltzmann Machine (DyBM) の構造である。 ボルツマンマシンでは、ノードはある時点でどのノードが自分を活性化させるかという情報を持っている。 このため、同時に発生している事象を認識することはできますが、異なる時間ステップを振り返って関連性を構築する能力は持っていません。 しかし、DyBMでは、ノード間の接続は、特定のタイムステップだけでなく、時間の経過とともにノードがどのように相互作用するかを表す。 8092>
この新しいアーキテクチャにより、ノードは過去のタイムステップT = t – 1、T = t – 2などにおける自身の活動を通して、あるタイムステップT = tにおいてどの他のノードが自身の活性化を触媒したかという情報を持つことになる。 この「記憶」はメモリユニットという形でノードに付加される。 このユニットは、他のノードの以前の値とそれ自身の関連する重みに応じて、ノードが任意の時点で活性化する確率を変更する。
2つのノードAとBがあるとしよう。 例えば、Aの活性化が2タイムステップ後に一貫してBの活性化につながると想像してください。 非動的ボルツマンマシンではこのパターンを捉えることができないが、DyBMではAの値がある程度遅れてBに伝わるので、A = 1の後しばらくしてB = 1となるパターンを捉えることができる。 ここでタイムステップT = tでB = 1となる確率はT = tでのAの値だけでなく、T = t – 1、T = t – 2などでのAの値に基づいて、AとBの間の伝導遅延の量によって変化することになる。 DyBMはこの情報を適格性トレースに格納する。 Bのシナプス候補トレースには、AからBに伝導遅延を経て到達した値の加重和が格納される。 BのNeural Eligibility Traceには、その過去の値の加重和が含まれる。
標準的なリカレントニューラルネットワークと同様に、DyBMを時間的に展開することが可能である。 8092>
つまり、これが動的ボルツマンマシンであり、ある時点だけでなく、そのデータの連続にわたって学習データを再作成する力を持つアーキテクチャである。
DyBMは魅力的であり、この後のパートではその点を強調しています。
パート4:RNN-ガウス型DyBMとLSTMの対決
これまで見てきたすべての例は、2値データ(ベルヌーイ分布)を扱っていました。 IBMの研究者はさらに一歩進んで、ガウス分布をモデル化できるDyBMを作り、私たちのようなユーザーがDyBMとそのバリエーションを使って時系列データをモデル化できるようにしました。
DyBMの効率を確認するために、私はRNN-ガウス型DyBM(RNN層を持つDyBM)と現在の最新鋭であるLSMTの比較テストをいくつか実行しました。 その結果は、とてもエキサイティングなものでした。 8092>
時系列のユースケースで、DyBMとLSTMの比較を見てみましょう。
1749年から1983年までチューリッヒの研究所で計算されたMonthly Sunspot Numberを含むデータを使用することにします。 データはオープンソースで、Datamarket – Monthly sunspot number, Zurich, 1749-1983から入手できます。
まず、LSTMのパフォーマンスを見てみましょう。
LSTM
- Architecture.LSTM
- Architecture: LSTM Dimension = 10.
- Performance over 10 epochs: Mean Test Score LSTM = 0.08877 RMSE
- Per epoch time to learn.LSTM = 0.08877 RMSE
- Per epoch time to learn: 8.689403 sec.

Figure 7: LSTMモデルから得られる予測 次に同じデータでRNN-ガウスDyBMはどうだったかというと、これはLSTMモデルから得られる予測です。
Brace yourself, this is going to be a very interesting journey of discovery… Ready?
RNN-Gaussian-DyBM
- Architecture: RNN Dimension = 10 and Input Dimension = 1
- 10エポックのパフォーマンス:Mean Test Score LSTM = 0.07848 RMSE
- 1エポックあたりの学習時間です。 0.90547 sec.

図8 RNN-ガウス型DyBMから得られる予測 このケースではRNN-ガウス型DyBMは10倍速く動作するだけではなく、性能も良くなっていることがわかる。
2つのモデルのエポック数をスケールすると、この2つのモデルのトレーニングの時間差は急激に大きくなる。 DyBMの応答時間ははるかに速いので、トレーニング – テスト – デプロイのサイクルは縮小し、より速くモデルを改善できます。
しかし、DyBMの最も良い部分についてまだ説明していません。 それは、GPU アクセラレーションによって高速化できることです。 IBM Watson Studio Local with Power AI IBM Cloud Service 上の GPU で実行される DyBM は、2000 以上の時系列(それぞれの長さは 500 以上)について、エポックあたり 10 秒未満で予測を行うことができます。 これに対し、CPU上で動作するDyBMは、同じ作業を行うのに30分強かかる。 この結果を、先ほどのCPU上のLSTMの性能と比較してみてください。 これがもたらす計算能力を想像してみてください。 GPUによるDyBMの高速化については、こちらを参照してください。 また、加速された DyBM と加速された LSTM の性能比較は異なります。
次回、時系列の問題を解決したいときは、Dynamic Boltzmann Machines を試してみてください。 IBM Research TokyoのGitHubにあるDynamic Boltzmann Machinesのリポジトリから始めることを検討してみてください。
エネルギーベースモデル、ボルツマンマシン、ダイナミックボルツマンマシンに関する詳細な調査については、以下を参照してください。
- A Tutorial on Energy-Based Learning – Yann LeCun, Sumit Chopra, Raia Hadsell, Marc’Aurelio Ranzato.著「エネルギーベースの学習に関するチュートリアル」。 and Fu Jie Huang
- Boltzmann Machines – Geoffrey Hinton
- Boltzmann Machines and Energy-Based Models – Takayuki Osogami (IBM Research – Tokyo)
- The seven neurons memorizing sequences of alphabetical images via spike-> Seven neurons continues of alphabetical images via akebono-measurement of akebono… (日本電信電話株式会社)タイミング依存の可塑性 – 長上貴之、大塚誠
- 時系列予測のための非線形ダイナミック・ボルツマンマシン – Sakyasingha Dasgupta、長上貴之 (IBM Research – Tokyo)