Rozptyl je číslo, které udává, jak daleko od sebe leží soubor čísel.Rozptyl je totožný se čtvercem směrodatné odchylky, a vyjadřuje tedy „totéž“ (ale silněji).
Variance – příklad
Studie nechala 100 lidí provést jednoduchý rychlostní úkol během 80 pokusů. U každého účastníka je tedy zaznamenáno 80 reakčních časů (v sekundách). Část těchto údajů je uvedena níže.

V podobných studiích obvykle vidíme, že lidé se zrychlují s tím, jak častěji provádějí rychlostní úlohu. To znamená, že průměrná reakční doba má tendenci se v průběhu pokusů snižovat.
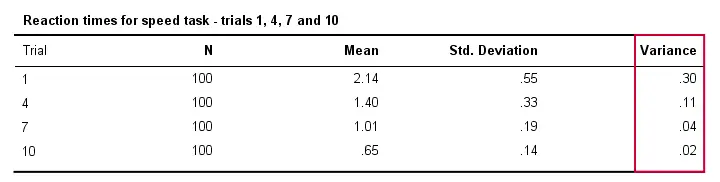
Také reakční doba se bude mezi různými lidmi obvykle méně lišit, pokud budou úkol provádět častěji. Technicky vzato říkáme, že rozptyl se v průběhu pokusů snižuje. Následující tabulka to ilustruje pro pokusy 1,4,7 a 10.
Rozptyl a histogram
Skvělým způsobem vizualizace dat z naší předchozí tabulky je histogram pro každý pokus. Takto obrázek níže ilustruje, že účastníci se v průběhu pokusů zrychlovali; od pokusu 1 k pokusu 10 se sloupce histogramu posouvají doleva, směrem k 0 sekundám.
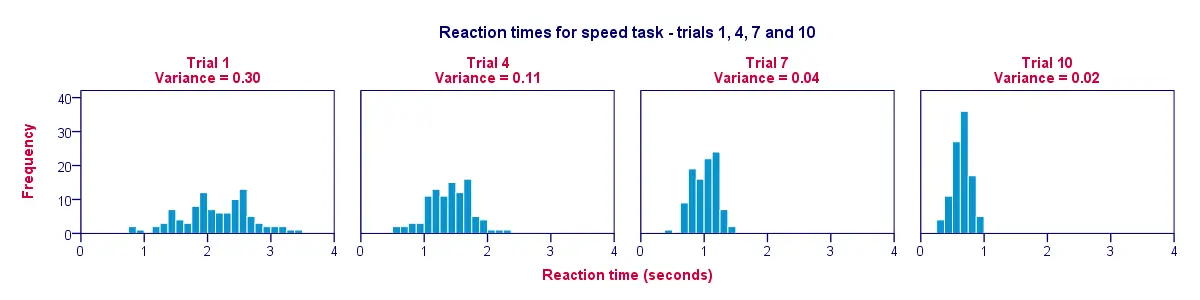
Druhým zjištěním je, že histogramy se zužují (a tedy zvyšují), jak postupujeme od pokusu 1 k pokusu 10; to ilustruje, že reakční doba se mezi našimi účastníky v průběhu experimentu stále méně liší. Rozptyl se v průběhu pokusů snižuje.
Rozptyl – vzorec pro populaci
Základní vzorec pro výpočet rozptylu je
$$S^2 = \frac{\sum(X – \overline{X})^2}{n}$$
Doporučujeme vám, abyste se pokusili pochopit, co tento vzorec dělá, protože to velmi pomáhá při pochopení ANOVA (= analýzy rozptylu). Proto si jej ukážeme na pouhé hrstce dat.
Variance – GoogleSheets
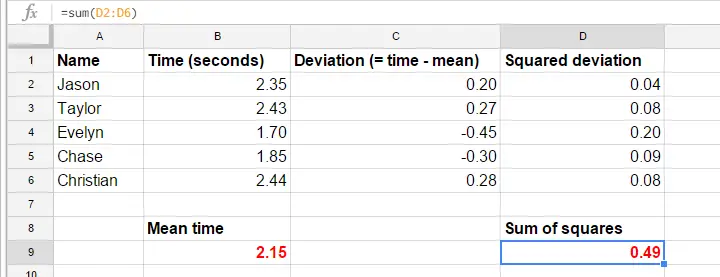
Pro zjednodušení zkrátíme naše data na první pokus pro prvních 5 účastníků. Těchto 5 reakčních časů -a ruční výpočet jejich rozptylu- je v tomto listu Google.
Rozptyl – kroky výpočtu
Vzorce v listu Google přesně ukazují, jak vypočítat rozptyl. Základní kroky jsou
- vypočítejte průměrnou reakční dobu (2,15);
- vypočítejte skóre odchylky (reakční doba minus průměrná reakční doba);
- vypočítejte skóre kvadratické odchylky;
- přičtěte skóre kvadratické odchylky. Výsledek (0,49) je součet čtverců, hlavní stavební prvek ANOVY;
- vydělte součet čtverců počtem pozorování (5 reakčních časů).
Případně vypočítejte rozptyl zadáním =VARP(B2:B6) do některé buňky (B2:B6 jsou buňky, které obsahují našich 5 reakčních časů). VARP je zkratka pro „populaci rozptylů“. OpenOffice a MS Excel obsahují podobné vzorce.
Variance – vzorec pro vzorek
Podobně jako u směrodatné odchylky, pokud jsou naše data prostým náhodným vzorkem z mnohem větší populace, bude výše uvedený vzorec systematicky podhodnocovat populační rozptyl. V tomto případě použijeme trochu jiný vzorec:
$$S^2 = \frac{\sum(X_i – \overline{X})^2}{n – 1}$
Který vzorec použijeme, tedy závisí na našich datech: obsahují celou populaci, kterou chceme zkoumat, nebo jsou pouhým vzorkem z této populace?
Protože našich 100 účastníků je jednoznačně vzorkem, použijeme vzorec pro vzorek. V tabulkách GoogleSheets se po zadání =VAR(B2:B6) do některé buňky vrátí výběrový rozptyl.
Rozptyl v SPSS
Pokud víme, vzorec pro populační rozptyl v SPSS zcela chybí a považujeme to za závažný nedostatek. Místo toho SPSS vždy používá vzorec pro vzorek, což platí jak pro rozptyl mezi subjekty (o kterém pojednává tento tutoriál), tak pro rozptyl v rámci subjektů. Příslušný výstup je uveden níže.

Vzhledem k této výstupní tabulce si také všimněte, že rozptyl je skutečně kvadratická směrodatná odchylka (kromě zaokrouhlování).
Vzhledem k rozptylu je to asi tak vše. Doufáme, že vám tento návod pomohl pochopit, co je to rozptyl.