Vítejte v deváté lekci „Manipulace s daty“ výukového kurzu SQL, který je součástí školení SQL. V této lekci si povíme o příkazech INSERT, UPDATE a DELETE jazyka SQL.
Cíle
Na konci této lekce budete umět:
-
Vysvětlit příkaz INSERT a jeho použití
-
Popsat dotaz UPDATE na příkladech
-
Vysvětlit příkaz DELETE na příkladu
Příkaz INSERT
Příkaz INSERT je jedním ze tří příkazů patřících do tzv.takzvanému „jazyku pro manipulaci s daty“, který je součástí jazyka SQL – tedy příkaz INSERT, UPDATE a DELETE.
Všechny tři příkazy umožňují měnit data v databázi, přičemž se nemění struktura, ale obsah. Liší se od příkazu SELECT, který umožňuje pouze číst data z databáze.
Příkaz INSERT tedy umožňuje přidávat nové záznamy do tabulky databáze. Obecně se používá k přidávání záznamů na konec tabulky. Jedna věc, která je důležitá vždy, když provádíte příkaz INSERT, je, že vaše data musí splňovat všechna pravidla v databázi.
Podívejte se na obrázek uvedený níže:
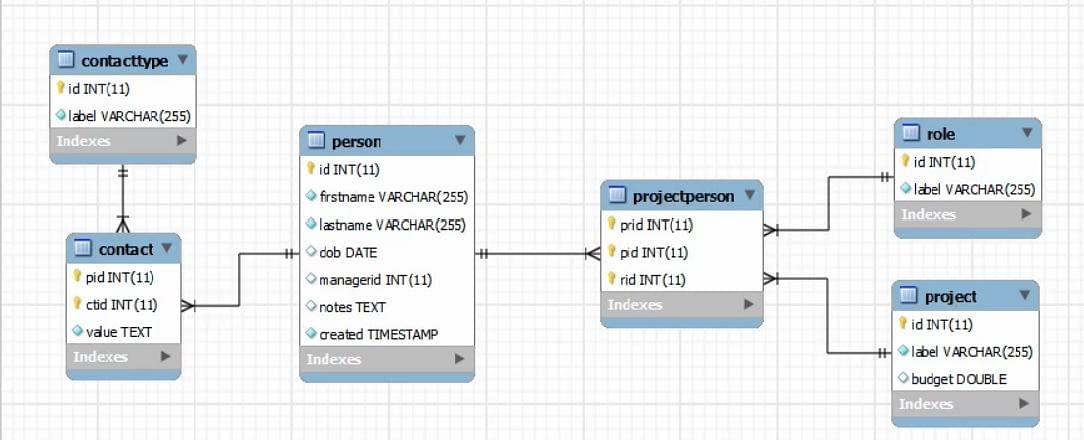
Nejprve se podíváme na tabulku Person jako na příklad. Zde máme primární klíč. Primární klíče v této databázi jsou v našem SQL předem nastaveny na automatický přírůstek.
Primární klíč nikdy nevkládáme sami, to necháváme na databázi. Dále máme jméno a příjmení, které mají příznak NOT NULL. Plný kosočtverec značí, že tato pole jsou povinná, nemůžeme je vynechat.
Poslední je časové razítko, které je NOT NULL, ale zároveň je výchozí hodnotou aktuální časové razítko. Takže opět by to automaticky nastavilo aktuální časové razítko, pokud tam žádné datum neuvedeme.
Pokud potřebujeme vložit záznamy do jiné tabulky, musíme se ujistit, že data skutečně existují. Takže v těchto druzích tabulek typu end to end nebo v jakékoliv situaci s cizím klíčem se vždy musíte ujistit, že data, která tam vkládáte, skutečně představují platné hodnoty v odkazovaných tabulkách.
Použijeme opět naši tabulku Person jako výchozí bod.
Tabulka Person na začátku vypadá tak, jak je uvedeno.
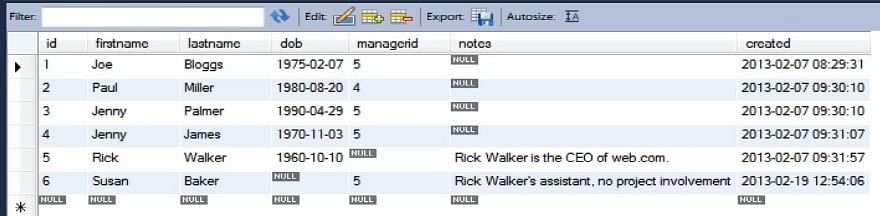
Uvažujme příklad uvedený níže:
select * from person
insert into person
values (7, ‚Martin‘, ‚Holzke‘, ‚1980-05-05‘, ‚xxx‘, now());
Najednou můžeme vkládat pouze do jedné tabulky. Data můžete spojovat pomocí funkce SELECT, ale tradičně lze provádět manipulaci s daty vždy jen v jedné tabulce.
To, co jsme uvažovali ve výše uvedeném příkladu, je „implicitní vkládání“. To znamená, že neuvádíme sloupce, které chceme naplnit, musíme je všechny vložit přesně v pořadí, v jakém tabulka existuje.
Vložení automaticky přiřadí nové hodnoty ke sloupcům tabulky.
Poznámka: U příkazů insert, update a delete musíme mít na paměti, že databáze nemají tlačítko undo. Jakmile tedy odešlete nějaké hodnoty, uloží se do databáze.
Protože se učíme o implicitním vkládání, musíme zadat hodnoty pro jednotlivé sloupce. Vidět databázovou tabulku na stejné obrazovce tedy nesmírně pomáhá.
Pokud nyní spustíme výše uvedený kód, můžete vidět, že tabulka byla aktualizována a vložený záznam je vidět na pozici 7.
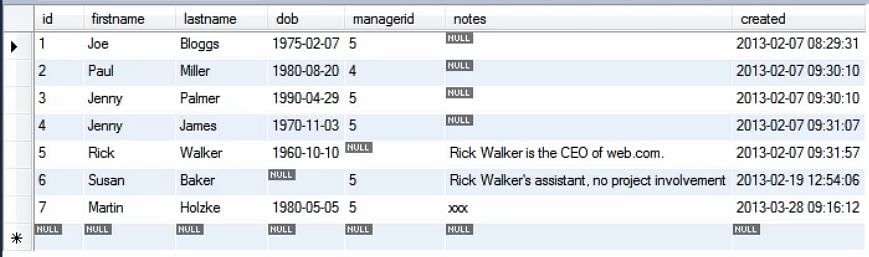
Příkaz insert také nic nevrací, na rozdíl od příkazu SELECT. Proto je poté obrazovka prázdná.
Dále se podívejme na explicitní verzi, kterou vřele doporučujeme používat.
select * from person
insert into person (jméno, příjmení, managerid, dob)
values (‚Martin‘, ‚Holzke‘, 5, ‚1980-05-05‘);
V uvedeném příkladu jsme právě uvedli 4 hodnoty tabulky. Zbytek se vyplní jako výchozí. Když spustíme dotaz, vidíme, že do tabulky byly přidány nové hodnoty.
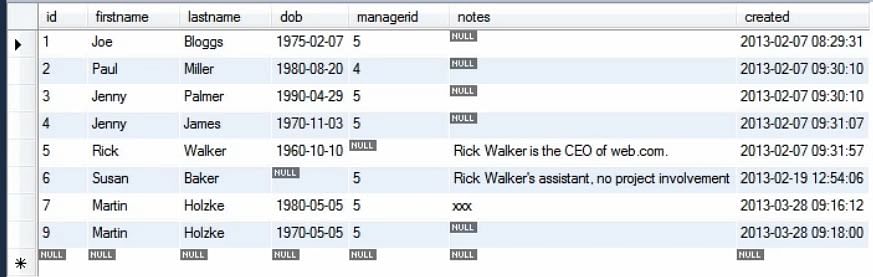
Hodnota primárního klíče je 9 a ne 8, protože tato hodnota, protože již byla někdy v databázi použita.
To je výhodné z bezpečnostních důvodů, protože primární klíč nelze použít znovu a lze identifikovat chyby.
Vidíme také, že hodnota sloupce ‚created‘ je nastavena pomocí aktuálního časového razítka, i když ji výslovně neuvádíme.
Pokud chceme provést vícenásobné vložení, můžeme výše uvedený dotaz spustit znovu a znovu s použitím různých hodnot.
Vícenásobné vložení lze provést pouze pomocí jednoho příkazu insert. Přidáme novou sadu hodnot, které jsou odděleny čárkou.
select * from person
insert into person (firstname, lastname, managerid, dob)
values (‚Martin‘, ‚Holzke‘, 5, ‚1980-05-05‘),
(‚Fred‘, ‚Flintstone‘, 5, ‚1987-06-02‘);
Následující obrázek ukazuje aktualizovanou tabulku při vícenásobném vložení.
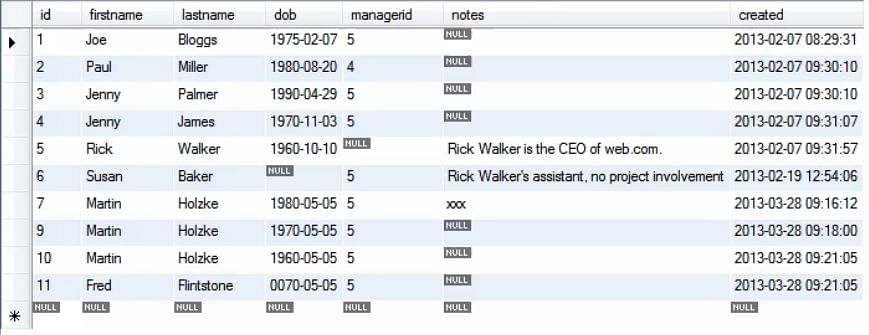
Další vložení chceme provést výběrem dat ze stejné tabulky, takže můžete kopírovat data, což se ukazuje jako docela užitečné pro naplnění databáze. Například při migraci dat vlastně chcete kopírovat data v rámci databáze nebo mezi různými databázemi/tabulkami.
Následující kód ukazuje, jak kopírovat data.
select * from person
insert into person (jméno, příjmení, managerid, dob)
select concat(‚kopie‘, jméno), příjmení, managerid, dob
from person
where id>=10
Následující obrázek ukazuje hodnoty tabulky, když spustíme pouze příkaz select.
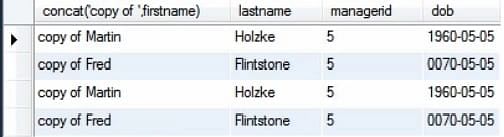
Nyní spustíme dotaz spolu s příkazem insert. To lze provést pouhým výběrem příkazů, které chceme spustit, a spuštěním tohoto dotazu.
Následující obrázek ukazuje, jak se tabulka změnila po spuštění výše uvedeného dotazu.
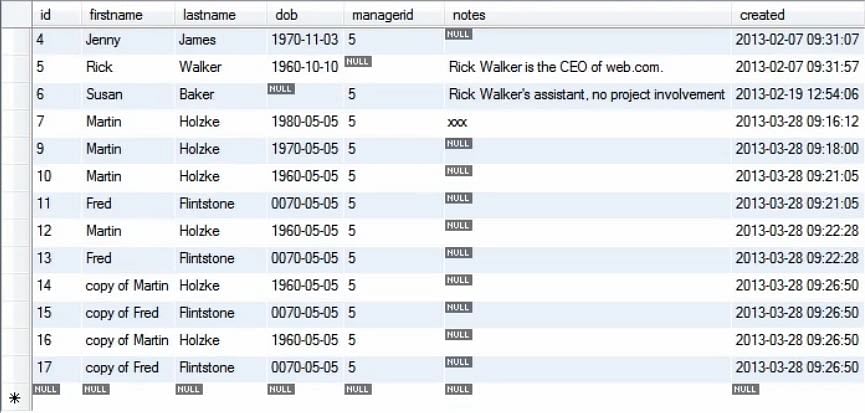 Odtud jsme viděli, jak může kopírování hodnot pomocí příkazu insert naplnit databázi. Databázi zpravidla naplníme, když spustíme dotazy v testovacím prostředí.
Odtud jsme viděli, jak může kopírování hodnot pomocí příkazu insert naplnit databázi. Databázi zpravidla naplníme, když spustíme dotazy v testovacím prostředí.
SQL – aktualizační dotaz
Aktualizační dotaz neboli příkaz je druhý ze tří příkazů jazyka pro manipulaci s daty, kterými jsou INSERT, UPDATE a DELETE. Dotaz UPDATE tedy umožňuje měnit existující záznamy v tabulce.
Protože hovoříme o jazyku SQL jako o jazyku založeném na množině, bude dotaz UPDATE pracovat na množině záznamů a ne na jednom záznamu (v závislosti na tom, jakým způsobem spustíte UPDATE).
Jak tedy provedeme všechny naše aktualizace?
Přemýšlejte o níže uvedeném dotazu:
select * from person
where id = 10
update person
set dob = ‚1990-01-01‘
where id = 10
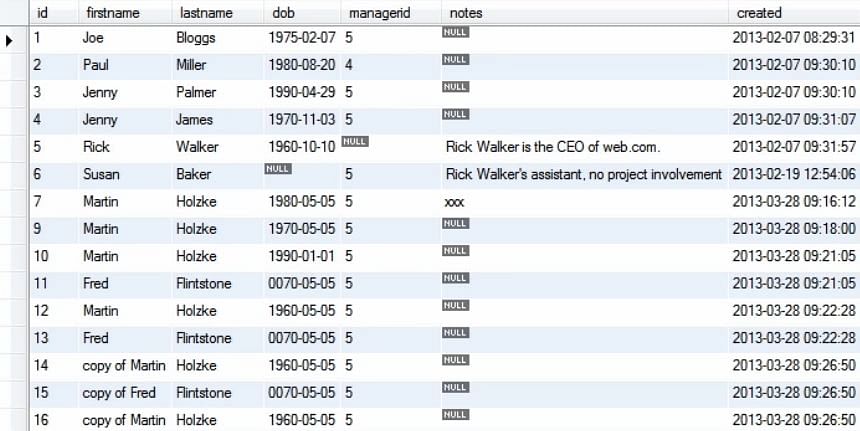
V uvedeném dotazu nejprve vybereme záznamy z tabulky Person, jejichž id se rovná 10. Následující obrázek ukazuje hodnotu, která se vybere.

Poté pomocí aktualizačního dotazu nastavíme DOB u záznamu, jehož id je 10. Pokud nepoužijeme příkaz where, aktualizuje se každý jednotlivý záznam v naší tabulce na nastavenou hodnotu.
Po provedení výše uvedeného dotazu vidíme, že hodnota dob pro 10. záznam v tabulce byla aktualizována.
 Chceme-li nyní aktualizovat více věcí v záznamu, můžeme použít seznam oddělený čárkou.
Chceme-li nyní aktualizovat více věcí v záznamu, můžeme použít seznam oddělený čárkou.
Podívejte se na níže uvedený dotaz:
select * from person
where id = 10
update person
set dob = ‚1990-01-01‘, firstname = ‚Mike‘
where id = 10
Po provedení výše uvedeného dotazu získáme aktualizovanou tabulku podle obrázku:
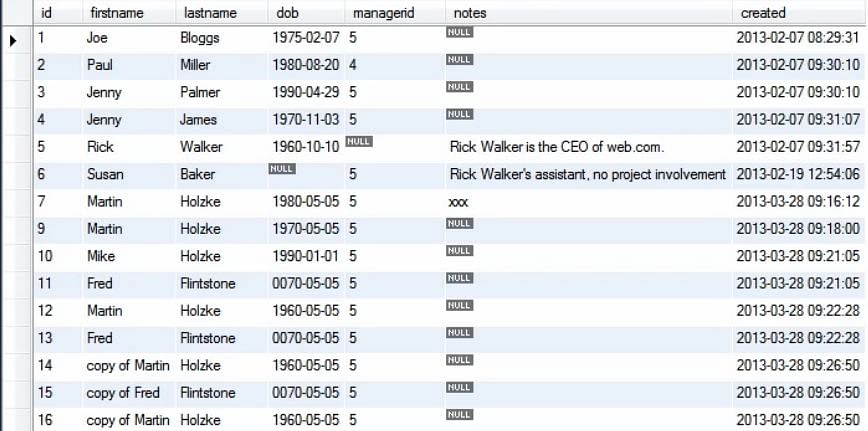
Pokud chceme změnit více než jeden záznam, můžeme postupovat následovně:
select * from person
where firstname = ‚Martin‘
update person
set firstname = ‚Mike‘
where firstname = ‚Martin‘
Ve výše uvedeném dotazu jsme změnili hodnotu křestního jména z Martin na Mike, ať už dříve existovala v tabulce Person.
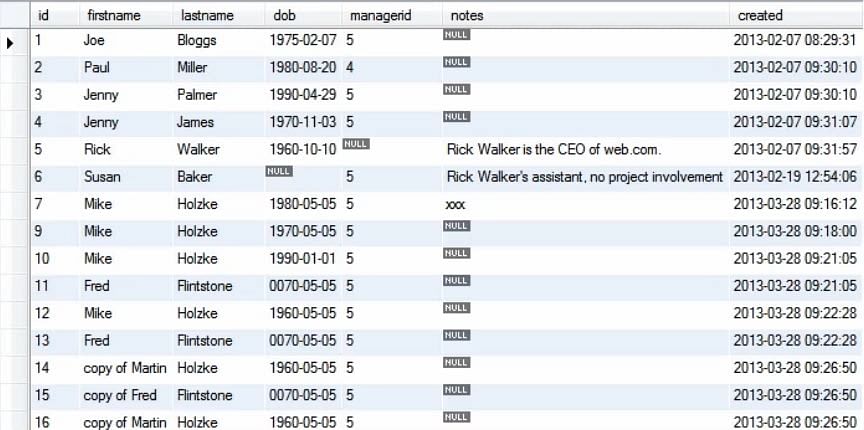
Uvažujme jiný příklad:
Tabulka osob neměla žádný prostor pro provádění trochu více číselných věcí, proto uvažujme tabulku projektů.
Zkusíme si zde vzít scénář, kdy by manipulace s celou tabulkou mohla být žádoucí.
Tabulka projektu má v tuto chvíli tři záznamy, jak ukazuje obrázek.
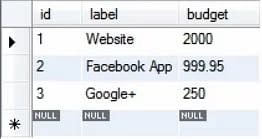
Každý záznam má hodnotu rozpočtu. Řekněme, že je chceme všechny vylepšit přibližně o 20 %. To můžeme provést pomocí níže uvedeného dotazu:
select * from project
update project
set budget = budget*1.2
Výše uvedený dotaz by tedy nyní zvýšil všechny záznamy v tabulce projektů o dvacet procent.
Aktualizované záznamy vypadají následovně:
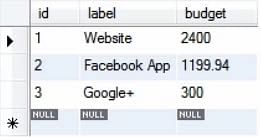
Na hodnotách lze tedy provádět mnoho matematických operací jako ve výše uvedeném příkladu.
Jednou z věcí, kterou je třeba mít na paměti při použití příkazu UPDATE, je použití klauzule „where“ všude tam, kde je to možné. Jinak dojde k aktualizaci hodnot všech záznamů v tabulce.
SQL příkaz DELETE
Prostudujme nyní příkaz DELETE, který je posledním ze tří příkazů jazyka pro manipulaci s daty. Příkaz DELETE má schopnost vymazat jeden nebo více záznamů v plném rozsahu. Nebudeme mluvit o mazání obsahu jednotlivých sloupců, protože to nemůžeme udělat.
Pokud to chcete udělat, musíte použít příkaz UPDATE, který změní obsah jednotlivých sloupců. DELETE je tedy smazání celého záznamu nebo více celých záznamů.
Stejně jako u příkazů INSERT a UPDATE platí, že jakmile smažete sérii záznamů, jsou pryč a není možné je získat zpět.
Také se musíme ujistit, že když smažeme nějaký záznam z tabulky, tento záznam (nebo jeho hodnotu) nepoužívá žádná jiná tabulka.
Tabulka osob má následující počáteční záznamy.
Příkaz DELETE můžeme použít tak, jak je uvedeno v následujícím dotazu:
select * from person
where id = 10
delete from person
where id = 10
Ve výše uvedeném dotazu jsme smazali záznam, jehož hodnota id byla 10. Záznam, jehož hodnota id byla 10, jsme smazali.
Poznámka: Nezapomeňte u příkazu DELETE použít klauzuli ‚where‘. V opačném případě příkaz bez klauzule ‚kde’rychle vyprázdní tabulku osob.
Při provedení výše uvedeného dotazu zjistíme, že záznam s hodnotou id 10 byl odstraněn a aktualizovaná tabulka vypadá podle obrázku. Vše ostatní zůstává, kromě toho s primárním klíčem 10.
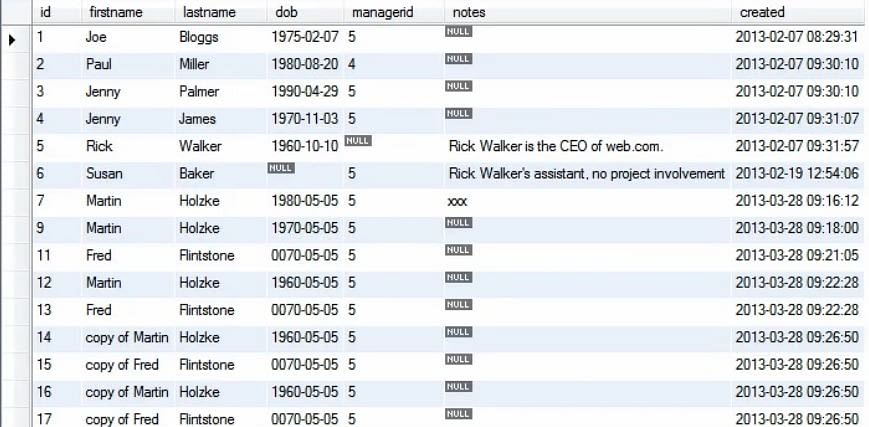
Jsou situace, kdy se chceme zbavit celého bloku. Například chceme odstranit všechny záznamy kopií z tabulky osob, jak je znázorněno na obrázku.
Dotaz pro odstranění všech kopírovacích záznamů z tabulky osob je uveden níže:
select * from person
where firstname like ‚copy%‘
delete from person
where firstname like ‚copy%‘
V uvedeném dotazu ‚copy%‘ označuje příkazy, které začínají slovem copy a pokračují libovolným slovem dále.
Po provedení výše uvedeného dotazu vidíme, že z tabulky osob byly odstraněny všechny záznamy, které začínaly slovem ‚copy‘.
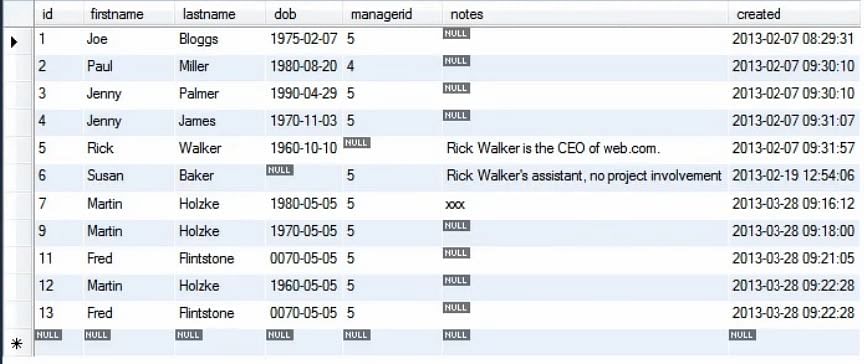
Poznámka: Příkaz DELETE se doporučuje používat vždy jen pro jednu tabulku. Příkaz se nedoporučuje používat v případě společných tabulek.
Závěr
Tímto jsme ukončili tuto lekci „Manipulace s daty v jazyce SQL.“ Příští lekce je zaměřena na řízení transakcí.
{{lectureCoursePreviewTitle}}. View Transcript Watch Video
Chcete-li se dozvědět více, absolvujte kurz
SQL Training Certification Training
Go to Course
To learn more, absolvovat kurz
SQL Training Certification Training Přejít na kurz
.