InterPro obsahuje tři hlavní entity: proteiny, signatury (označované také jako „metody“ nebo „modely“) a záznamy. Proteiny v databázi UniProtKB jsou zároveň ústředními proteinovými entitami v databázi InterPro. Informace o tom, které signatury se významně shodují s těmito proteiny, se vypočítávají při uvolňování sekvencí v databázi UniProtKB a tyto výsledky jsou zpřístupněny veřejnosti (viz níže). Shody signatur s proteiny rozhodují o tom, jak jsou signatury integrovány společně do záznamů InterPro: jako ukazatele příbuznosti se používají srovnávací překryvy shodných souborů proteinů a umístění shod signatur na sekvencích. Do systému InterPro jsou integrovány pouze signatury, které jsou považovány za dostatečně kvalitní. K verzi 81.0 (vydané 21. srpna 2020) bylo v záznamech InterPro anotováno 73,9 % reziduí nalezených v databázi UniProtKB a dalších 9,2 % bylo anotováno signaturami, které čekají na integraci.

InterPro zahrnuje také údaje o sestřihových variantách a proteinech obsažených v databázích UniParc a UniMES.
Členské databáze konsorcia InterProUpravit
Podpisy z InterPro pocházejí z 13 „členských databází“, které jsou uvedeny níže.
CATH-Gene3D Popisuje proteinové rodiny a architektury domén v kompletních genomech. Proteinové rodiny se vytvářejí pomocí Markovova shlukovacího algoritmu, po němž následuje vícesvazkové shlukování podle sekvenční identity. Mapování předpovězené struktury a sekvenčních domén se provádí pomocí knihoven skrytých Markovových modelů reprezentujících domény CATH a Pfam. K proteinům je poskytována funkční anotace z více zdrojů. Funkční predikce a analýza architektury domén je k dispozici na webových stránkách Gene3D. CDD Conserved Domain Database je zdroj pro anotaci proteinů, který se skládá ze sbírky anotovaných modelů vícenásobného zarovnání sekvencí pro staré domény a proteiny plné délky. Ty jsou k dispozici jako pozičně specifické skórovací matice (PSSM) pro rychlou identifikaci konzervovaných domén v proteinových sekvencích pomocí RPS-BLAST. HAMAP znamená High-quality Automated and Manual Annotation of microbial Proteomes (vysoce kvalitní automatizovaná a manuální anotace mikrobiálních proteomů). Profily HAMAP jsou ručně vytvářeny odbornými kurátory identifikují proteiny, které jsou součástí dobře konzervovaných bakteriálních, archeálních a plastidy kódovaných (tj. chloroplasty, cyanely, apikoplasty, nefotosyntetické plastidy) proteinových rodin nebo podrodin. MobiDB MobiDB je databáze anotující vnitřní poruchy proteinů. PANTHER PANTHER je rozsáhlá kolekce proteinových rodin, které byly rozděleny do funkčně příbuzných podrodin s využitím lidských odborných znalostí. Tyto podrodiny modelují divergenci specifických funkcí v rámci proteinových rodin, což umožňuje přesnější spojení s funkcí (klasifikace molekulárních funkcí a biologických procesů a diagramy drah sestavené lidmi) a také odvození aminokyselin důležitých pro funkční specifičnost. Pro každou rodinu a podrodinu jsou vytvořeny skryté Markovovy modely (HMM) pro klasifikaci dalších proteinových sekvencí. Pfam Je rozsáhlá sbírka mnohonásobných zarovnání sekvencí a skrytých Markovových modelů pokrývající mnoho běžných proteinových domén a rodin.
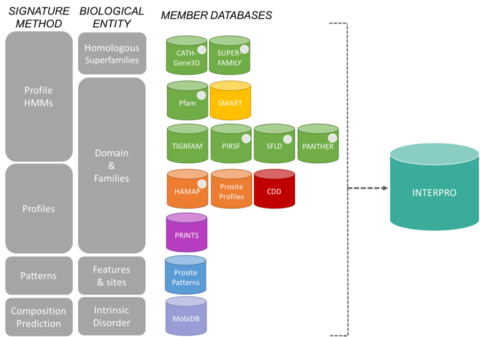
Systém klasifikace proteinů PIRSF je síť s několika úrovněmi sekvenční rozmanitosti od nadrodin po podrodiny, která odráží evoluční vztahy proteinů a domén plné délky. Základní klasifikační jednotkou PIRSF je homeomorfní rodina, jejíž členové jsou homologní (vyvinuli se ze společného předka) a homeomorfní (sdílejí podobnost sekvencí plné délky a společnou architekturu domén). PRINTS PRINTS je sborník otisků proteinů. Otisk prstu je skupina konzervovaných motivů sloužících k charakterizaci proteinové rodiny; jeho diagnostická síla se zpřesňuje iterativním skenováním v systému UniProt. Motivy se obvykle nepřekrývají, ale jsou odděleny podél sekvence, i když mohou být v 3D-prostoru sousední. Otisky prstů mohou kódovat záhyby a funkčnost proteinů pružněji a účinněji než jednotlivé motivy, přičemž jejich plná diagnostická síla vyplývá ze vzájemného kontextu, který poskytují sousedé motivů. PROSITE PROSITE je databáze proteinových rodin a domén. Skládá se z biologicky významných míst, vzorů a profilů, které pomáhají spolehlivě určit, do které známé proteinové rodiny (pokud existuje) nová sekvence patří. SMART Simple Modular Architecture Research Tool Umožňuje identifikaci a anotaci geneticky pohyblivých domén a analýzu doménových architektur. Lze detekovat více než 800 doménových rodin vyskytujících se v signálních, extracelulárních a chromatinově asociovaných proteinech. Tyto domény jsou rozsáhle anotovány s ohledem na fyletické rozložení, funkční třídu, terciární struktury a funkčně důležitá rezidua. SUPERFAMILY SUPERFAMILY je knihovna profilových skrytých Markovových modelů, které reprezentují všechny proteiny známé struktury. Knihovna je založena na klasifikaci proteinů SCOP: každý model odpovídá doméně SCOP a jeho cílem je reprezentovat celou superrodinu SCOP, do které daná doména patří. SUPERFAMILY byla použita k provedení strukturních přiřazení ke všem kompletně sekvenovaným genomům. SFLD Hierarchická klasifikace enzymů, která spojuje specifické rysy sekvenční struktury se specifickými chemickými schopnostmi. TIGRFAMs TIGRFAMs je kolekce proteinových rodin s kurátorovanými vícenásobnými zarovnáními sekvencí, skrytými Markovovými modely (HMM) a anotacemi, která poskytuje nástroj pro identifikaci funkčně příbuzných proteinů na základě sekvenční homologie. Ty položky, které jsou „equivalogs“, sdružují homologické proteiny, které jsou konzervované s ohledem na funkci.
Typy datUpravit
InterPro se skládá ze sedmi typů dat poskytnutých různými členy konsorcia:
| Typ dat | Popis | Přispívající databáze |
|---|---|---|
| Záznamy InterPro | Struktura. a/nebo funkční domény proteinů předpovězené pomocí jedné nebo více signatur | Všech 13 členských databází |
| Signatury členských databází | Signatury z členských databází. Patří sem signatury, které jsou integrovány do InterPro, a ty, které nejsou | Všech 13 členských databází |
| Proteinové | Proteinové sekvence | UniProtKB (Swiss-Prot a TrEMBL) |
| Proteom | Soubor proteinů, které patří jednomu organismu | UniProtKB |
| Struktura | 3-.rozměrové struktury proteinů | PDBe |
| Taxonomie | Taxonomické informace o proteinech | UniProtKB |
| Sada | Skupiny evolučně příbuzných rodin | Pfam, CDD |

Typy záznamů InterProUpravit
Záznamy InterPro lze dále rozdělit do pěti typů:
- Homologní nadrodina: Skupina proteinů, které mají společný evoluční původ, jak je patrné z jejich strukturní podobnosti, i když jejich sekvence nejsou velmi podobné. Tyto záznamy konkrétně poskytují pouze dvě členské databáze: CATH-Gene3D a SUPERFAMILY.
- Rodina:
- Doména: Skupina proteinů, které mají společný evoluční původ určený na základě strukturní podobnosti, příbuzných funkcí nebo sekvenční homologie:
- Opakování: Sekvence aminokyselin, obvykle ne delší než 50 aminokyselin, která má tendenci se v bílkovině mnohokrát opakovat.
- Místo: Sekvence aminokyselin, která má tendenci se v bílkovině mnohokrát opakovat: Krátká sekvence aminokyselin, kde je zachována alespoň jedna aminokyselina. Patří sem místa modifikace po translaci, konzervovaná místa, vazebná místa a aktivní místa.