Abychom vám Gaussova jádra řádně představili, začneme tento týden trochu abstraktněji než obvykle. Tato úroveň abstrakce není nezbytně nutná k pochopení toho, jak Gaussova jádra fungují, ale abstraktní pohled může být nesmírně užitečný jako zdroj intuice při snaze pochopit rozdělení pravděpodobnosti obecně. Takže tady je dohoda: pokusím se pomalu budovat abstrakci, ale pokud se někdy beznadějně ztratíte nebo to prostě už nebudete moci vydržet, můžete přeskočit dolů na nadpis, kde je tučně napsáno „Praktická část“ – Tam přejdu na konkrétnější popis algoritmu Gaussova jádra. Také pokud se vám to stále nedaří, nedělejte si příliš velké starosti – většina pozdějších příspěvků na tomto blogu nebude vyžadovat, abyste Gaussovým jádrům rozuměli, takže můžete prostě počkat na příspěvek příští týden (nebo na něj přeskočit, pokud to čtete později).
Připomeňte si, že jádro je způsob, jak umístit datový prostor do vektorového prostoru vyšší dimenze tak, aby průsečíky datového prostoru s hyperplochami v prostoru vyšší dimenze určovaly složitější, zakřivené rozhodovací hranice v datovém prostoru. Hlavním příkladem, na který jsme se podívali, bylo jádro, které posílá dvourozměrný datový prostor do pětirozměrného prostoru tak, že každý bod se souřadnicemi 


Tento týden přejdeme od vyšších rozměrů k nekonečně rozměrným vektorovým prostorům. Můžete si všimnout, že výše uvedené devítirozměrné jádro je rozšířením pětirozměrného jádra – v podstatě jsme jen na konec přidali další čtyři rozměry. Pokud budeme tímto způsobem přidávat další dimenze, dostaneme stále větší a větší dimenzionální jádra. Kdybychom to dělali „donekonečna“, měli bychom nakonec nekonečně mnoho rozměrů. Všimněte si, že to můžeme dělat pouze abstraktně. Počítače si poradí pouze s konečnými věcmi, takže nemohou ukládat a zpracovávat výpočty v nekonečně rozměrných vektorových prostorech. Ale budeme na chvíli předstírat, že můžeme, jen abychom viděli, co se stane. Pak převedeme věci zpět do konečného světa.
V tomto hypotetickém nekonečně rozměrném vektorovém prostoru můžeme sčítat vektory stejným způsobem jako u běžných vektorů, prostě sečteme odpovídající souřadnice. V tomto případě však musíme sčítat nekonečně mnoho souřadnic. Podobně můžeme násobit skaláry tak, že každou z (nekonečně mnoha) souřadnic vynásobíme daným číslem. Jádro nekonečného polynomu definujeme tak, že každý bod 

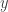


Abychom se dostali zpět do světa výpočtů, můžeme naše původní pětirozměrné jádro obnovit tak, že prostě zapomeneme všechny zápisy kromě prvních pěti. Ve skutečnosti je původní pětirozměrný prostor obsažen v tomto nekonečně rozměrném prostoru. (Původní pětirozměrné jádro je to, co získáme promítnutím nekonečného polynomického jádra do tohoto pětirozměrného prostoru.)
Teď se zhluboka nadechněte, protože se posuneme o krok dál. Uvažujme na chvíli, co je to vektor. Pokud jste někdy chodili na hodiny matematické lineární algebry, možná si vzpomenete, že vektory jsou oficiálně definovány z hlediska jejich sčítacích a násobicích vlastností. Ale já to budu dočasně ignorovat (s omluvou všem matematikům, kteří toto čtou). Ve světě počítačů si obvykle představujeme vektor jako seznam čísel. Pokud jste dočetli až sem, možná jste ochotni připustit, že tento seznam je nekonečný. Já však chci, abyste o vektoru přemýšleli jako o souboru čísel, v němž je každé číslo přiřazeno určité věci. Například každé číslo v našem obvyklém typu vektoru je přiřazeno jedné ze souřadnic/prvků. V jednom z našich nekonečných vektorů je každé číslo přiřazeno určitému místu v našem nekonečně dlouhém seznamu.
Ale co třeba tohle: Co by se stalo, kdybychom definovali vektor přiřazením čísla každému bodu v našem (konečně rozměrném) datovém prostoru? Takový vektor nevybírá jediný bod v datovém prostoru; naopak, jakmile vybereme tento vektor, ukážeme-li na libovolný bod v datovém prostoru, vektor nám sdělí číslo. No, vlastně už pro to máme název: Něco, co každému bodu v datovém prostoru přiřadí číslo, je funkce. Ve skutečnosti jsme se na tomto blogu funkcemi zabývali často, a to v podobě funkcí hustoty, které definují rozdělení pravděpodobnosti. Jde však o to, že tyto funkce hustoty můžeme považovat za vektory v nekonečně rozměrném vektorovém prostoru.
Jak může být funkce vektorem? No, dvě funkce můžeme sčítat tak, že prostě sečteme jejich hodnoty v jednotlivých bodech. To bylo první schéma, o kterém jsme hovořili při kombinování distribucí v příspěvku o směsných modelech z minulého týdne. Funkce hustoty pro dva vektory (Gaussovy kapky) a výsledek jejich sčítání jsou znázorněny na obrázku níže. Podobným způsobem můžeme funkci vynásobit číslem, což by mělo za následek zesvětlení nebo ztmavení celkové hustoty. Ve skutečnosti se jedná o obě operace, které jste si pravděpodobně hodně procvičili v hodinách algebry a matematiky. Zatím tedy neděláme nic nového, jen o věcech přemýšlíme jiným způsobem.

Dalším krokem je definovat jádro z našeho původního datového prostoru do tohoto nekonečně rozměrného prostoru, a zde máme spoustu možností. Jednou z nejčastějších voleb je Gaussova kapkovitá funkce, se kterou jsme se již několikrát setkali v minulých příspěvcích. Pro toto jádro zvolíme standardní velikost Gaussových kapek, tj. pevnou hodnotu odchylky 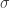
Nyní nastane problém: Abychom mohli věci vrátit do výpočetního světa, musíme vybrat konečný rozměrový vektorový prostor sedící v tomto nekonečném rozměrovém vektorovém prostoru a „promítnout“ nekonečný rozměrový prostor do konečného rozměrového podprostoru. Konečně rozměrný prostor vybereme tak, že zvolíme (konečný) počet bodů v datovém prostoru a pak vektorový prostor obsáhneme Gaussovými skvrnami se středem v tomto bodě. To je ekvivalent vektorového tempa definovaného prvními pěti souřadnicemi nekonečného polynomického jádra, jak je uvedeno výše. Výběr těchto bodů je důležitý, ale k tomu se vrátíme později. Prozatím je otázkou, jak budeme promítat?
Pro konečný rozměr vektorů je nejběžnějším způsobem, jak definovat promítání, použití tečkového součinu: To je číslo, které získáme vynásobením odpovídajících souřadnic dvou vektorů a jejich sečtením. Tak například tečkový součin třírozměrných vektorů 


Něco podobného bychom mohli udělat s funkcemi tak, že vynásobíme hodnoty, které nabývají v odpovídajících bodech datového souboru. (Jinými slovy, vynásobíme obě funkce dohromady.) Pak ale nemůžeme všechna tato čísla sečíst, protože jich je nekonečně mnoho. Místo toho provedeme integrál! (Všimněte si, že zde zamlčuji spoustu podrobností, a ještě jednou se omlouvám všem matematikům, kteří to čtou). Hezké na tom je, že když vynásobíme dvě Gaussovy funkce a integrujeme, číslo se rovná Gaussově funkci vzdálenosti mezi středovými body. (I když nová Gaussova funkce bude mít jinou hodnotu odchylky.)
Jinými slovy, Gaussovo jádro transformuje bodový součin v nekonečně rozměrném prostoru na Gaussovu funkci vzdálenosti mezi body v datovém prostoru: Pokud jsou dva body v datovém prostoru blízko sebe, pak úhel mezi vektory, které je reprezentují v prostoru jádra, bude malý. Pokud jsou body daleko od sebe, pak budou odpovídající vektory blízké „kolmici“.
Praktická část
Zopakujme si tedy, co jsme si dosud řekli: Pro definici 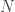
Abychom lépe pochopili, jak toto jádro funguje, zjistíme, jak vypadá průsečík hyperplochy s datovým prostorem. (To je to, co se s jádry stejně většinou dělá.) Připomeňme si, že rovina je definována rovnicí tvaru 


To je stále dost těžké rozklíčovat, takže se podívejme na příklad, kde každá z hodnot 

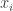





Pokud upravíme parametry
To nám tedy dává větší flexibilitu při volbě rozhodovací hranice (nebo alespoň jiný druh flexibility), ale konečný výsledek bude velmi záviset na
Nalezení takové množiny bodů je zcela jiný problém, než na který jsme se zaměřovali v dosavadních příspěvcích na tomto blogu, a spadá do kategorie neřízeného učení/deskriptivní analýzy. (V kontextu jader si ji můžeme představit také jako výběr příznaků/inženýrství). V několika příštích příspěvcích změníme směr a začneme se zabývat myšlenkami v tomto směru.
.