Con el fin de dar una introducción adecuada a los núcleos de Gauss, el post de esta semana va a empezar un poco más abstracto de lo habitual. Este nivel de abstracción no es estrictamente necesario para entender cómo funcionan los núcleos gaussianos, pero la perspectiva abstracta puede ser extremadamente útil como fuente de intuición cuando se trata de entender las distribuciones de probabilidad en general. Así que este es el trato: trataré de construir la abstracción poco a poco, pero si alguna vez te pierdes irremediablemente, o simplemente no puedes soportarlo más, puedes saltar hasta el título que dice «La parte práctica» en negrita – Ahí es donde voy a cambiar a una descripción más concreta del algoritmo del núcleo de Gauss. Además, si usted todavía está teniendo problemas, no se preocupe demasiado – La mayoría de las entradas posteriores en este blog no requieren que usted entienda los núcleos de Gauss, por lo que sólo puede esperar a la próxima semana (o saltar a ella si usted está leyendo esto más tarde).
Recuerde que un núcleo es una manera de colocar un espacio de datos en un espacio vectorial de mayor dimensión para que las intersecciones del espacio de datos con hiperplanos en el espacio de mayor dimensión determinar más complicado, los límites de decisión curvas en el espacio de datos. El ejemplo principal que vimos fue el núcleo que envía un espacio de datos de dos dimensiones a un espacio de cinco dimensiones enviando cada punto con coordenadas 


Esta semana, vamos a ir más allá de los espacios vectoriales de dimensión superior a los espacios vectoriales de dimensión infinita. Puedes ver cómo el núcleo de nueve dimensiones de arriba es una extensión del núcleo de cinco dimensiones – esencialmente hemos añadido cuatro dimensiones más al final. Si seguimos añadiendo más dimensiones de esta manera, obtendremos núcleos cada vez más dimensionales. Si siguiéramos haciendo esto «para siempre», acabaríamos teniendo infinitas dimensiones. Nótese que sólo podemos hacer esto en abstracto. Los ordenadores sólo pueden tratar con cosas finitas, así que no pueden almacenar y procesar cálculos en espacios vectoriales de dimensiones infinitas. Pero vamos a fingir por un momento que podemos, sólo para ver qué pasa. Luego volveremos a trasladar las cosas al mundo finito.
En este hipotético espacio vectorial de dimensiones infinitas, podemos sumar vectores de la misma manera que lo hacemos con los vectores regulares, simplemente sumando las coordenadas correspondientes. Sin embargo, en este caso, tenemos que sumar infinitas coordenadas. Del mismo modo, podemos multiplicar por escalares, multiplicando cada una de las (infinitas) coordenadas por un número determinado. Definiremos el núcleo polinómico infinito enviando cada punto 

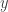


Para volver al mundo computacional, podemos recuperar nuestro núcleo original de cinco dimensiones simplemente olvidando todas las entradas menos las cinco primeras. De hecho, el espacio original de cinco dimensiones está contenido en este espacio dimensional infinito. (El núcleo original de cinco dimensiones es lo que obtenemos al proyectar el núcleo polinómico infinito en este espacio de cinco dimensiones.)
Ahora respira hondo, porque vamos a llevar esto un paso más allá. Considera, por un momento, lo que es un vector. Si alguna vez tomaste una clase de álgebra lineal matemática, tal vez recuerdes que los vectores se definen oficialmente en términos de sus propiedades de adición y multiplicación. Pero voy a ignorar temporalmente eso (con perdón de los matemáticos que estén leyendo esto). En el mundo de la informática, solemos pensar que un vector es una lista de números. Si has leído hasta aquí, puede que estés dispuesto a dejar que esa lista sea infinita. Pero quiero que pienses en un vector como una colección de números en la que cada número está asignado a una cosa concreta. Por ejemplo, cada número en nuestro tipo habitual de vector se asigna a una de las coordenadas/características. En uno de nuestros vectores infinitos, cada número se asigna a un punto de nuestra lista infinitamente larga.
Pero qué tal esto: ¿Qué pasaría si definimos un vector asignando un número a cada punto de nuestro espacio de datos (de dimensión finita)? Un vector así no escoge un solo punto del espacio de datos, sino que, una vez escogido este vector, si se apunta a cualquier punto del espacio de datos, el vector nos dice un número. Bueno, en realidad, ya tenemos un nombre para eso: Algo que asigna un número a cada punto del espacio de datos es una función. De hecho, en este blog hemos hablado mucho de funciones, en forma de funciones de densidad que definen distribuciones de probabilidad. Pero la cuestión es que podemos pensar en estas funciones de densidad como vectores en un espacio vectorial de dimensión infinita.
¿Cómo puede una función ser un vector? Bueno, podemos sumar dos funciones simplemente sumando sus valores en cada punto. Este fue el primer esquema que discutimos para combinar distribuciones en el post de la semana pasada sobre modelos de mezcla. Las funciones de densidad de dos vectores (manchas gaussianas) y el resultado de sumarlas se muestran en la siguiente figura. Podemos multiplicar una función por un número de forma similar, lo que resultaría en hacer la densidad global más clara o más oscura. De hecho, ambas son operaciones con las que probablemente has tenido mucha práctica en las clases de álgebra y cálculo. Así que no estamos haciendo nada nuevo todavía, sólo estamos pensando en las cosas de una manera diferente.

El siguiente paso es definir un núcleo de nuestro espacio de datos original en este espacio infinito dimensional, y aquí tenemos un montón de opciones. Una de las opciones más comunes es la función blob gaussiana, que hemos visto varias veces en entradas anteriores. Para este kernel, elegiremos un tamaño estándar para las manchas gaussianas, es decir, un valor fijo para la desviación 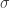
Ahora, aquí está el problema: Con el fin de traer las cosas de vuelta al mundo computacional, tenemos que elegir un espacio vectorial de dimensión finita sentado en este espacio vectorial de dimensión infinita y «proyectar» el espacio de dimensión infinita en el subespacio de dimensión finita. Elegiremos un espacio de dimensión finita escogiendo un número (finito) de puntos en el espacio de datos, y luego tomando el espacio vectorial abarcado por las manchas gaussianas centradas en esos puntos. Esto es el equivalente al paso de vectores definido por las cinco primeras coordenadas del núcleo polinómico infinito, como se ha dicho anteriormente. La elección de estos puntos es importante, pero volveremos a ello más adelante. Por ahora, la pregunta es ¿cómo proyectamos?
Para vectores de dimensión finita, la forma más común de definir una proyección es utilizando el producto punto: Este es el número que obtenemos al multiplicar las coordenadas correspondientes de dos vectores, y luego sumarlas. Así, por ejemplo, el producto punto de los vectores tridimensionales 


Podemos hacer algo parecido con las funciones, multiplicando los valores que toman en los puntos correspondientes del conjunto de datos. (En otras palabras, multiplicamos las dos funciones juntas.) Pero no podemos entonces sumar todos estos números porque hay infinitos. En su lugar, ¡tomaremos una integral! (Ten en cuenta que estoy pasando por alto un montón de detalles aquí, y vuelvo a pedir disculpas a cualquier matemático que esté leyendo esto). Lo bueno aquí es que si multiplicamos dos funciones gaussianas e integramos, el número es igual a una función gaussiana de la distancia entre los puntos centrales. (Aunque la nueva función gaussiana tendrá un valor de desviación diferente.)
En otras palabras, el núcleo gaussiano transforma el producto punto en el espacio dimensional infinito en la función gaussiana de la distancia entre puntos en el espacio de datos: Si dos puntos del espacio de datos están cerca, el ángulo entre los vectores que los representan en el espacio del kernel será pequeño. Si los puntos están muy alejados, entonces los vectores correspondientes serán casi «perpendiculares».
La parte práctica
Así que repasemos lo que tenemos hasta ahora: Para definir un kernel gaussiano de 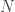
Para entender mejor cómo funciona este kernel, vamos a averiguar cómo es la intersección de un hiperplano con el espacio de datos. (Esto es lo que se hace con los núcleos la mayor parte del tiempo, de todos modos.) Recordemos que un plano está definido por una ecuación de la forma 


Eso es todavía bastante difícil de descifrar, así que vamos a ver un ejemplo en el que cada uno de los valores 

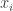





Si ajustamos los parámetros
Así que esto nos da más flexibilidad para elegir el límite de decisión (o, al menos, un tipo diferente de flexibilidad) pero el resultado final será muy dependiente de los vectores
Encontrar tal colección de puntos es un problema muy diferente de lo que hemos estado enfocando en las entradas hasta ahora en este blog, y cae bajo la categoría de aprendizaje no supervisado / análisis descriptivo. (En el contexto de los kernels, también puede considerarse como selección/ingeniería de características). En los próximos posts, cambiaremos de marcha y empezaremos a explorar ideas en esta línea.