Du kan köra TensorFlow-koden själv på den här länken (eller en PyTorch-version på den här länken), eller fortsätta läsa för att se koden utan att köra den. Eftersom koden är lite längre än i de tidigare delarna kommer jag bara att visa de viktigaste delarna här. Hela källkoden finns tillgänglig efter länken ovan.
Här är CartPole-miljön. Jag använder OpenAI Gym för att visualisera och köra denna miljö. Målet är att flytta vagnen till vänster och höger för att hålla stången i ett vertikalt läge. Om stolpens lutning är mer än 15 grader från den vertikala axeln avslutas avsnittet och vi börjar om från början. Video 1 visar ett exempel på att köra flera episoder i denna miljö genom att vidta åtgärder slumpmässigt.
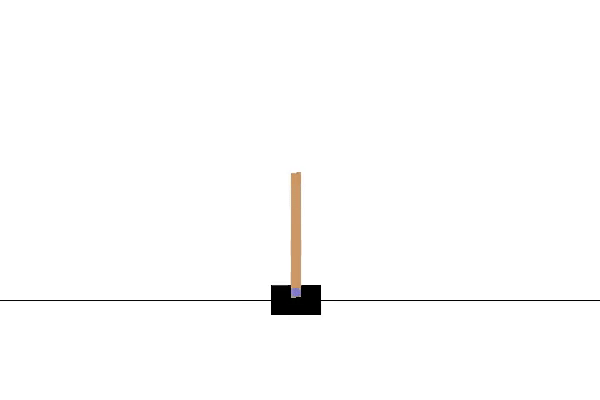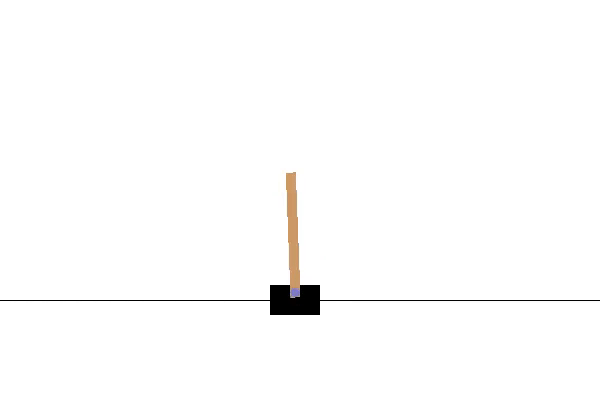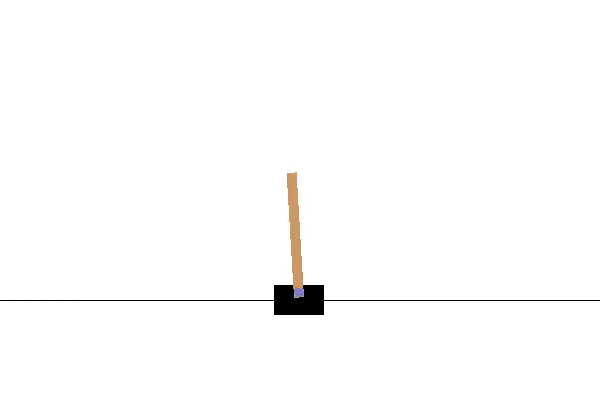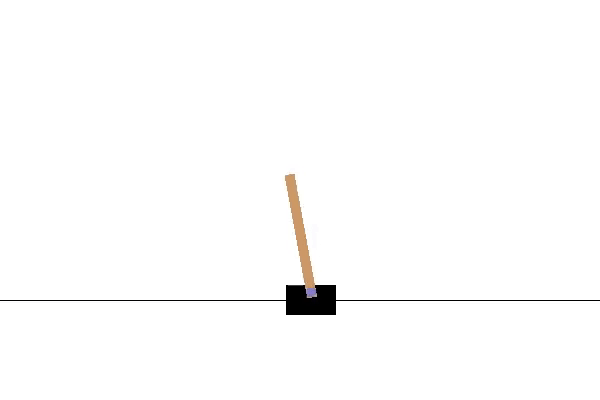
För att genomföra DQN-algoritmen börjar vi med att skapa DNN:erna main (main_nn) och target (target_nn). Målnätverket kommer att vara en kopia av huvudnätverket, men med en egen kopia av vikterna. Vi kommer också att behöva en optimerare och en förlustfunktion.
Nästan kommer vi att skapa erfarenhetsuppspelningsbufferten, för att lägga till erfarenheten i bufferten och ta ett urval av den senare för träning.
Vi kommer också att skriva en hjälpfunktion för att köra ε-greedy-policyn och för att träna huvudnätverket med hjälp av de data som lagras i bufferten.
Vi kommer också att definiera de nödvändiga hyperparametrarna och vi kommer att träna det neurala nätverket. Vi kommer att spela upp en episod med hjälp av ε-greedy-politiken, lagra data i erfarenhetsuppspelningsbufferten och träna huvudnätverket efter varje steg. En gång var 2 000:e steg kopierar vi vikterna från huvudnätverket till målnätverket. Vi kommer också att minska värdet på epsilon (ε) för att börja med hög utforskning och minska utforskningen med tiden. Vi kommer att se hur algoritmen börjar lära sig efter varje episod.
Detta är resultatet som kommer att visas:
Episode 0/1000. Epsilon: 0.99. Reward in last 100 episodes: 14.0 Episode 50/1000. Epsilon: 0.94. Reward in last 100 episodes: 22.2 Episode 100/1000. Epsilon: 0.89. Reward in last 100 episodes: 23.3 Episode 150/1000. Epsilon: 0.84. Reward in last 100 episodes: 23.4 Episode 200/1000. Epsilon: 0.79. Reward in last 100 episodes: 24.9 Episode 250/1000. Epsilon: 0.74. Reward in last 100 episodes: 30.4 Episode 300/1000. Epsilon: 0.69. Reward in last 100 episodes: 38.4 Episode 350/1000. Epsilon: 0.64. Reward in last 100 episodes: 51.4 Episode 400/1000. Epsilon: 0.59. Reward in last 100 episodes: 68.2 Episode 450/1000. Epsilon: 0.54. Reward in last 100 episodes: 82.4 Episode 500/1000. Epsilon: 0.49. Reward in last 100 episodes: 102.1 Episode 550/1000. Epsilon: 0.44. Reward in last 100 episodes: 129.7 Episode 600/1000. Epsilon: 0.39. Reward in last 100 episodes: 151.7 Episode 650/1000. Epsilon: 0.34. Reward in last 100 episodes: 173.0 Episode 700/1000. Epsilon: 0.29. Reward in last 100 episodes: 187.3 Episode 750/1000. Epsilon: 0.24. Reward in last 100 episodes: 190.9 Episode 800/1000. Epsilon: 0.19. Reward in last 100 episodes: 194.6 Episode 850/1000. Epsilon: 0.14. Reward in last 100 episodes: 195.9 Episode 900/1000. Epsilon: 0.09. Reward in last 100 episodes: 197.9 Episode 950/1000. Epsilon: 0.05. Reward in last 100 episodes: 200.0 Episode 1000/1000. Epsilon: 0.05. Reward in last 100 episodes: 200.0
Nu när agenten har lärt sig att maximera belöningen för CartPole-miljön kommer vi att låta agenten interagera med miljön en gång till, för att visualisera resultatet och se att den nu kan hålla stången i balans i 200 bilder.

Du kan köra TensorFlow-koden själv på den här länken (eller en PyTorch-version på den här länken).