InterPro innehåller tre huvudsakliga enheter: proteiner, signaturer (även kallade ”metoder” eller ”modeller”) och poster. Proteinerna i UniProtKB är också de centrala proteinentiteterna i InterPro. Information om vilka signaturer som påtagligt matchar dessa proteiner beräknas när sekvenserna släpps av UniProtKB och dessa resultat görs tillgängliga för allmänheten (se nedan). Det är signaturernas matchningar med proteiner som avgör hur signaturerna integreras tillsammans i InterPro-posterna: jämförande överlappning av matchade proteinuppsättningar och placeringen av signaturernas matchningar på sekvenserna används som indikatorer på släktskap. Endast signaturer som anses vara av tillräcklig kvalitet integreras i InterPro. I version 81.0 (släppt den 21 augusti 2020) har InterPro-posterna annoterat 73,9 % av de rester som finns i UniProtKB och ytterligare 9,2 % har annoterats av signaturer som väntar på att integreras.

InterPro innehåller också data för skarvvarianter och de proteiner som ingår i databaserna UniParc och UniMES.
InterPro-konsortiets medlemsdatabaserRedigera
Signaturerna från InterPro kommer från 13 ”medlemsdatabaser”, som förtecknas nedan.
CATH-Gene3D Beskriver proteinfamiljer och domänarkitekturer i fullständiga genomer. Proteinfamiljer bildas med hjälp av en Markov-klusteralgoritm, följt av multi-linkage-klustering enligt sekvensidentitet. Kartläggning av förutspådd struktur och sekvensdomäner görs med hjälp av bibliotek med dolda Markovmodeller som representerar CATH- och Pfam-domäner. Proteiner förses med funktionell annotering från flera olika resurser. Funktionell prediktion och analys av domänarkitekturer finns tillgängliga på webbplatsen Gene3D. CDD Conserved Domain Database är en resurs för proteinannotering som består av en samling annoterade modeller för flera sekvensanpassningar för gamla domäner och proteiner i full längd. Dessa finns tillgängliga som positionsspecifika poängmatriser (PSSM) för snabb identifiering av bevarade domäner i proteinsekvenser via RPS-BLAST. HAMAP står för High-quality Automated and Manual Annotation of microbial Proteomes. HAMAP-profiler skapas manuellt av sakkunniga kuratorer som identifierar proteiner som ingår i välbevarade bakterie-, arkeal- och plastidkodade (dvs. kloroplaster, cyaneller, apikoplaster, icke-fotosyntetiska plastider) proteinfamiljer eller underfamiljer. MobiDB MobiDB är en databas för annotering av inneboende störningar i proteiner. PANTHER PANTHER är en stor samling av proteinfamiljer som med hjälp av mänsklig expertis har delats in i funktionellt relaterade underfamiljer. Dessa underfamiljer modellerar divergensen av specifika funktioner inom proteinfamiljer, vilket möjliggör en mer exakt koppling till funktion (mänskligt kurerade klassificeringar av molekylära funktioner och biologiska processer och diagram över vägar), samt en slutsats av aminosyror som är viktiga för funktionsspecificitet. Dolda Markovmodeller (HMM) byggs upp för varje familj och underfamilj för klassificering av ytterligare proteinsekvenser. Pfam är en stor samling av flera sekvensanpassningar och dolda Markovmodeller som täcker många vanliga proteindomäner och -familjer.
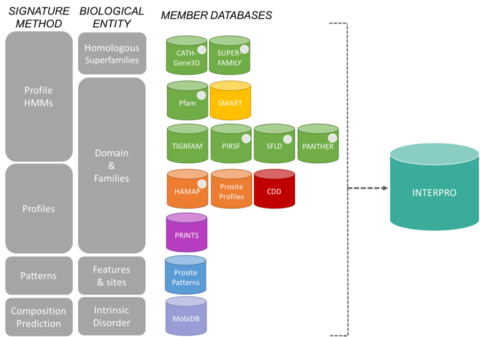
PIRSF Proteinklassificeringssystem är ett nätverk med flera nivåer av sekvensdiversitet från superfamiljer till underfamiljer som avspeglar det evolutionära förhållandet mellan proteiner och domäner i full längd. Den primära PIRSF-klassificeringsenheten är den homeomorfa familjen, vars medlemmar är både homologa (utvecklats från en gemensam förfader) och homeomorfa (delar likheter i sekvensen i full längd och en gemensam domänarkitektur). PRINTS PRINTS är ett kompendium av proteinfingeravtryck. Ett fingeravtryck är en grupp konserverade motiv som används för att karakterisera en proteinfamilj. Dess diagnostiska kraft förfinas genom iterativ skanning av UniProt. Motiven överlappar vanligtvis inte varandra, utan är separerade längs en sekvens, även om de kan vara sammanhängande i 3D-rummet. Fingeravtryck kan koda proteinveck och funktioner på ett mer flexibelt och kraftfullt sätt än vad enskilda motiv kan göra, och deras fulla diagnostiska styrka härrör från den ömsesidiga kontext som tillhandahålls av motivgrannar. PROSITE PROSITE är en databas över proteinfamiljer och -domäner. Den består av biologiskt betydelsefulla platser, mönster och profiler som hjälper till att på ett tillförlitligt sätt identifiera till vilken känd proteinfamilj (om någon) en ny sekvens hör. SMART Simple Modular Architecture Research Tool Gör det möjligt att identifiera och annotera genetiskt rörliga domäner och analysera domänarkitekturer. Mer än 800 domänfamiljer som finns i signalerande, extracellulära och kromatinassocierade proteiner kan upptäckas. Dessa domäner är utförligt annoterade med avseende på fyletisk fördelning, funktionell klass, tertiärstrukturer och funktionellt viktiga rester. SUPERFAMILY SUPERFAMILY är ett bibliotek med profilerade dolda Markovmodeller som representerar alla proteiner med känd struktur. Biblioteket bygger på SCOP-klassificeringen av proteiner: varje modell motsvarar en SCOP-domän och syftar till att representera hela den SCOP-superfamilj som domänen tillhör. SUPERFAMILY har använts för att utföra strukturella tilldelningar till alla fullständigt sekvenserade genomer. SFLD En hierarkisk klassificering av enzymer som relaterar specifika sekvensstrukturegenskaper till specifika kemiska förmågor. TIGRFAMs TIGRFAMs är en samling av proteinfamiljer, med kurerade multipla sekvensanpassningar, dolda Markovmodeller (HMM) och annotation, som ger ett verktyg för att identifiera funktionellt besläktade proteiner baserat på sekvenshomologi. De poster som är ”equivalogs” grupperar homologa proteiner som är konserverade med avseende på funktion.
DatatyperEdit
InterPro består av sju typer av data som tillhandahålls av olika medlemmar i konsortiet:
| Datatyper | Beskrivning | Bidragande databaser |
|---|---|---|
| InterPro Entries | Structural och/eller funktionella domäner hos proteiner som förutsetts med hjälp av en eller flera signaturer | Alla 13 medlemsdatabaser |
| Medlemsdatabasens signaturer | Signaturer från medlemsdatabaser. Dessa inkluderar signaturer som är integrerade i InterPro, och de som inte är det | Alla 13 medlemsdatabaser |
| Protein | Proteinsekvenser | UniProtKB (Swiss-Prot och TrEMBL) |
| Proteom | Samling av proteiner som tillhör en enda organism | UniProtKB |
| Struktur | 3-dimensionella strukturer av proteiner | PDBe |
| Taxonomi | Taxonomisk information om proteiner | UniProtKB |
| Set | Grupper av evolutionärt relaterade familjer | Pfam, CDD |

InterPro entry typesEdit
InterPro entries can be further broken down into five types:
- Homologous Superfamily: En grupp av proteiner som har ett gemensamt evolutionärt ursprung, vilket framgår av deras strukturella likheter, även om deras sekvenser inte är mycket lika. Dessa poster tillhandahålls specifikt endast av två medlemsdatabaser: CATH-Gene3D och SUPERFAMILY.
- Familj: En grupp proteiner som har ett gemensamt evolutionärt ursprung som fastställts genom strukturella likheter, relaterade funktioner eller sekvenshomologi.
- Domän: En grupp av proteiner som har ett gemensamt evolutionärt ursprung som fastställts genom strukturella likheter, relaterade funktioner eller sekvenshomologi: En distinkt enhet i ett protein med en särskild funktion, struktur eller sekvens.
- Repeat: En sekvens av aminosyror, vanligtvis inte längre än 50 aminosyror, som tenderar att upprepas många gånger i ett protein.
- Site: En kort sekvens av aminosyror där minst en aminosyra är bevarad. Dessa inkluderar modifieringsställen efter transformation, konserverade ställen, bindningsställen och aktiva ställen.