För att ge en ordentlig introduktion till Gaussiska kärnor kommer veckans inlägg att börja lite mer abstrakt än vanligt. Denna abstraktionsnivå är inte strikt nödvändig för att förstå hur Gaussiska kärnor fungerar, men det abstrakta perspektivet kan vara extremt användbart som en källa till intuition när man försöker förstå sannolikhetsfördelningar i allmänhet. Så här är det: Jag kommer att försöka bygga upp abstraktionen långsamt, men om du någonsin blir hopplöst vilse, eller om du helt enkelt inte orkar mer, kan du hoppa ner till rubriken där det står ”Den praktiska delen” i fetstil – Där kommer jag att övergå till en mer konkret beskrivning av algoritmen för den gaussiska kärnan. Om du fortfarande har problem, oroa dig inte för mycket – De flesta av de senare inläggen på den här bloggen kommer inte att kräva att du förstår Gaussiska kärnor, så du kan bara vänta på nästa veckas inlägg (eller hoppa över till det om du läser det här senare).
Håll dig till minnet att en kärna är ett sätt att placera ett datarum i ett mer tredimensionellt vektorrum, så att datarummets skärningspunkter med hyperplan i det mer tredimensionella rummet bestämmer mer komplicerade, böjda beslutsgränser i datarummet. Det viktigaste exemplet som vi tittade på var kärnan som skickar ett tvådimensionellt datarum till ett femdimensionellt rum genom att skicka varje punkt med koordinaterna 


Den här veckan kommer vi att gå bortom högre dimensionella vektorrum och gå till oändligt dimensionella vektorrum. Du kan se hur den niodimensionella kärnan ovan är en förlängning av den femdimensionella kärnan – vi har i princip bara lagt till ytterligare fyra dimensioner i slutet. Om vi fortsätter att lägga till fler dimensioner på detta sätt får vi allt högre och högre dimensionella kärnor. Om vi skulle fortsätta att göra detta ”för evigt” skulle vi få oändligt många dimensioner. Observera att vi bara kan göra detta i abstrakt form. Datorer kan bara hantera ändliga saker, så de kan inte lagra och bearbeta beräkningar i oändligt dimensionella vektorrum. Men vi låtsas för en stund att vi kan det, bara för att se vad som händer. Sedan översätter vi saker och ting tillbaka till den finita världen.
I detta hypotetiska oändligt dimensionella vektorrum kan vi lägga till vektorer på samma sätt som vi gör med vanliga vektorer, genom att bara lägga till motsvarande koordinater. I det här fallet måste vi dock lägga till oändligt många koordinater. På samma sätt kan vi multiplicera med skalarer, genom att multiplicera var och en av de (oändligt många) koordinaterna med ett givet tal. Vi definierar den oändliga polynomkärnan genom att skicka varje punkt 

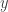


För att återgå till beräkningsvärlden kan vi återfå vår ursprungliga femdimensionella kärna genom att helt enkelt glömma bort alla poster utom de fem första. Faktum är att det ursprungliga femdimensionella rummet finns i detta oändligt dimensionella rum. (Den ursprungliga femdimensionella kärnan är vad vi får genom att projicera den oändliga polynomkärnan in i detta femdimensionella rum.)
Ta nu ett djupt andetag, för vi ska ta detta ett steg längre. Tänk för ett ögonblick på vad en vektor är. Om du någonsin gått en kurs i matematisk linjär algebra kommer du kanske ihåg att vektorer officiellt definieras i termer av deras additions- och multiplikationsegenskaper. Men jag tänker tillfälligt ignorera det (med ursäkt till alla matematiker som läser detta.) I datorvärlden tänker vi vanligtvis på en vektor som en lista med siffror. Om du har läst så här långt är du kanske villig att låta den listan vara oändlig. Men jag vill att du ska tänka på en vektor som en samling tal där varje tal tilldelas en viss sak. Till exempel tilldelas varje nummer i vår vanliga typ av vektor en av koordinaterna/detaljerna. I en av våra oändliga vektorer är varje nummer tilldelat en plats i vår oändligt långa lista.
Men vad sägs om detta: Vad skulle hända om vi definierade en vektor genom att tilldela varje punkt i vårt (ändligt dimensionella) datarum ett nummer? En sådan vektor väljer inte ut en enda punkt i datarummet, utan när du väl har valt denna vektor, om du pekar på någon punkt i datarummet, ger vektorn dig ett nummer. Egentligen har vi redan ett namn för detta: Något som tilldelar varje punkt i datarummet ett nummer är en funktion. Vi har faktiskt tittat mycket på funktioner på den här bloggen, i form av täthetsfunktioner som definierar sannolikhetsfördelningar. Men poängen är att vi kan tänka oss dessa densitetsfunktioner som vektorer i ett oändligt dimensionellt vektorrum.
Hur kan en funktion vara en vektor? Jo, vi kan addera två funktioner genom att bara addera deras värden i varje punkt. Detta var det första schemat vi diskuterade för att kombinera fördelningar i förra veckans inlägg om blandningsmodeller. Densitetsfunktionerna för två vektorer (gaussiska klot) och resultatet av att addera dem visas i figuren nedan. Vi kan multiplicera en funktion med ett tal på ett liknande sätt, vilket skulle resultera i att göra den totala densiteten ljusare eller mörkare. I själva verket är detta båda operationer som du förmodligen har haft mycket övning med i algebraundervisningen och kalkyleringen. Så vi gör inget nytt ännu, vi tänker bara på saker och ting på ett annat sätt.

Nästa steg är att definiera en kärna från vårt ursprungliga datarum till detta oändligt dimensionella rum, och här har vi många valmöjligheter. Ett av de vanligaste valen är Gaussian blob-funktionen som vi har sett några gånger i tidigare inlägg. För den här kärnan väljer vi en standardstorlek för de gaussiska blobs, dvs. ett fast värde för avvikelsen 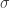
Nu kommer problemet: För att föra tillbaka saker och ting till beräkningsvärlden måste vi plocka ut ett ändligt dimensionellt vektorrum som sitter i det här oändligt dimensionella vektorrummet och ”projicera” det oändligt dimensionella rummet in i det ändligt dimensionella underrummet. Vi väljer ett finitdimensionellt rum genom att välja ett (ändligt) antal punkter i datarummet och sedan ta det vektorrum som spänns upp av de gaussiska klumparna med centrum i dessa punkter. Detta är motsvarigheten till den vektortakt som definieras av de fem första koordinaterna i den oändliga polynomkärnan, enligt ovan. Valet av dessa punkter är viktigt, men vi återkommer till det senare. För tillfället är frågan hur vi projicerar?
För ändligt dimensionella vektorer är det vanligaste sättet att definiera en projektion genom att använda punktprodukten: Detta är det tal som vi får genom att multiplicera motsvarande koordinater för två vektorer och sedan addera dem tillsammans. Så till exempel är punktprodukten av de tredimensionella vektorerna 


Vi skulle kunna göra något liknande med funktioner genom att multiplicera de värden som de tar på motsvarande punkter i datamängden. (Med andra ord multiplicerar vi de två funktionerna med varandra.) Men vi kan då inte addera alla dessa tal eftersom det finns oändligt många av dem. Istället tar vi en integral! (Observera att jag glänser över en massa detaljer här, och jag ber återigen om ursäkt till alla matematiker som läser detta). Det fina här är att om vi multiplicerar två gaussiska funktioner och integrerar så blir talet lika med en gaussisk funktion av avståndet mellan centrumpunkterna. (Även om den nya gaussiska funktionen kommer att ha ett annat avvikelsevärde.)
Med andra ord omvandlar den gaussiska kärnan punktprodukten i det oändligt dimensionella rummet till en gaussisk funktion av avståndet mellan punkterna i datarummet: Om två punkter i datarummet ligger nära varandra kommer vinkeln mellan de vektorer som representerar dem i kärnutrymmet att vara liten. Om punkterna är långt ifrån varandra kommer motsvarande vektorer att vara nära ”vinkelräta”.
Den praktiska delen
Så, låt oss gå igenom vad vi har hittills: För att definiera en 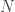
För att bättre förstå hur denna kärna fungerar kan vi ta reda på hur skärningen mellan ett hyperplan och datarummet ser ut. (Detta är vad man gör med kärnor för det mesta i alla fall.) Minns att ett plan definieras av en ekvation av formen 


Det är fortfarande ganska svårt att packa upp, så låt oss titta på ett exempel där vart och ett av värdena 

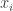





Om vi justerar parametrarna
Detta ger oss alltså mer flexibilitet när det gäller att välja beslutsgränsen (eller åtminstone en annan typ av flexibilitet), men slutresultatet kommer att vara mycket beroende av de
Att hitta en sådan samling punkter är ett mycket annorlunda problem än vad vi har fokuserat på i inläggen hittills på den här bloggen, och faller under kategorin oövervakad inlärning/beskrivande analys. (I samband med kärnor kan det också betraktas som urval/utveckling av funktioner). I de kommande inläggen kommer vi att byta växel och börja utforska idéer i den här riktningen.