InterPro conține trei entități principale: proteine, semnături (denumite, de asemenea, „metode” sau „modele”) și intrări. Proteinele din UniProtKB sunt, de asemenea, entitățile proteice centrale din InterPro. Informațiile privind semnăturile care se potrivesc în mod semnificativ cu aceste proteine sunt calculate pe măsură ce secvențele sunt publicate de UniProtKB, iar aceste rezultate sunt puse la dispoziția publicului (a se vedea mai jos). Potrivirile semnăturilor cu proteinele sunt cele care determină modul în care semnăturile sunt integrate împreună în intrările InterPro: suprapunerea comparativă a seturilor de proteine potrivite și localizarea potrivirii semnăturilor pe secvențe sunt utilizate ca indicatori de înrudire. Numai semnăturile considerate a fi de o calitate suficientă sunt integrate în InterPro. Începând cu versiunea 81.0 (lansată la 21 august 2020), intrările InterPro au adnotat 73,9 % din reziduurile găsite în UniProtKB, cu încă 9,2 % adnotate de semnături care sunt în curs de integrare.

InterPro include, de asemenea, date pentru variantele de îmbinare și proteinele conținute în bazele de date UniParc și UniMES.
Baze de date membre ale consorțiului InterProEdit
Semnăturile din InterPro provin din 13 „baze de date membre”, care sunt enumerate mai jos.
CATH-Gene3D Descrie familii de proteine și arhitecturi de domenii în genomuri complete. Familiile de proteine sunt formate cu ajutorul unui algoritm de grupare Markov, urmat de o grupare multi-linkage în funcție de identitatea secvenței. Cartografierea structurii prezise și a domeniilor de secvență se realizează cu ajutorul bibliotecilor de modele Markov ascunse care reprezintă domeniile CATH și Pfam. Se furnizează adnotări funcționale pentru proteine din mai multe resurse. Predicția funcțională și analiza arhitecturilor de domenii sunt disponibile pe site-ul Gene3D. Baza de date CDD Conserved Domain Database este o resursă de adnotare a proteinelor care constă într-o colecție de modele de aliniere a secvențelor multiple adnotate pentru domenii vechi și proteine de lungime completă. Acestea sunt disponibile ca matrici de scoruri specifice poziției (PSSM) pentru identificarea rapidă a domeniilor conservate în secvențe de proteine prin RPS-BLAST. HAMAP înseamnă High-quality Automated and Manual Annotation of microbial Proteomes (Adnotare automată și manuală de înaltă calitate a proteinomelor microbiene). Profilurile HAMAP sunt create manual de către curatori experți și identifică proteinele care fac parte din familii sau subfamilii de proteine bine conservate de bacterii, arhelii și plastide (de exemplu, cloroplaste, cianale, apicoplaste, plastide nefosintetice). MobiDB MobiDB este o bază de date care adnotează dezordinea intrinsecă a proteinelor. PANTHER PANTHER PANTHER este o colecție mare de familii de proteine care au fost subdivizate în subfamilii înrudite din punct de vedere funcțional, cu ajutorul expertizei umane. Aceste subfamilii modelează divergența funcțiilor specifice în cadrul familiilor de proteine, permițând o asociere mai precisă cu funcția (clasificări ale funcțiilor moleculare și ale proceselor biologice și diagrame ale căilor de acces, toate acestea fiind selectate de către oameni), precum și inferența aminoacizilor importanți pentru specificitatea funcțională. Modelele Markov ascunse (HMM) sunt construite pentru fiecare familie și subfamilie pentru clasificarea secvențelor proteice suplimentare. Pfam Este o colecție mare de alinieri de secvențe multiple și modele Markov ascunse care acoperă multe domenii și familii de proteine comune.
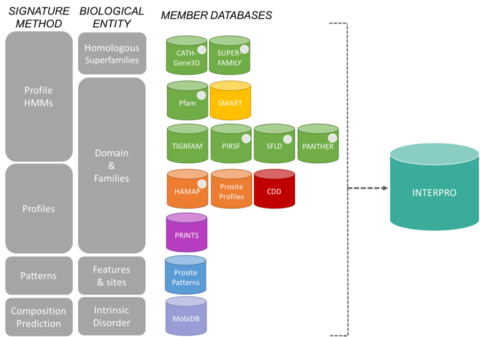
Sistemul de clasificare a proteinelor PIRSF Sistemul de clasificare a proteinelor este o rețea cu mai multe niveluri de diversitate a secvențelor, de la superfamilii la subfamilii, care reflectă relația evolutivă a proteinelor și domeniilor de lungime completă. Unitatea primară de clasificare PIRSF este familia homeomorfă, ai cărei membri sunt atât omologi (au evoluat de la un strămoș comun), cât și homeomorfi (care împărtășesc o similitudine de secvență pe toată lungimea și o arhitectură comună a domeniului). PRINTS PRINTS este un compendiu de amprente proteice. O amprentă digitală este un grup de motive conservate utilizate pentru a caracteriza o familie de proteine; puterea sa de diagnosticare este rafinată prin scanarea iterativă a UniProt. De obicei, motivele nu se suprapun, ci sunt separate de-a lungul unei secvențe, deși pot fi contigue în spațiul 3D. Amprentele digitale pot codifica falduri și funcționalități ale proteinelor într-un mod mai flexibil și mai puternic decât o pot face motivele individuale, întreaga lor putere de diagnosticare derivând din contextul reciproc oferit de vecinii motivelor. PROSITE PROSITE este o bază de date a familiilor și domeniilor de proteine. Aceasta constă în situri, modele și profiluri semnificative din punct de vedere biologic care ajută la identificarea fiabilă a familiei de proteine cunoscute (dacă există) din care face parte o nouă secvență. SMART Simple Modular Architecture Research Tool (Instrument simplu de cercetare a arhitecturii modulare) Permite identificarea și adnotarea domeniilor mobile din punct de vedere genetic și analiza arhitecturilor de domenii. Sunt detectabile peste 800 de familii de domenii întâlnite în proteine de semnalizare, extracelulare și asociate cu cromatina. Aceste domenii sunt adnotate în mod extensiv în ceea ce privește distribuțiile filitice, clasa funcțională, structurile terțiare și reziduurile importante din punct de vedere funcțional. SUPERFAMILY SUPERFAMILY este o bibliotecă de modele Markov ascunse de profil care reprezintă toate proteinele cu structură cunoscută. Biblioteca se bazează pe clasificarea SCOP a proteinelor: fiecare model corespunde unui domeniu SCOP și urmărește să reprezinte întreaga superfamilie SCOP din care face parte domeniul respectiv. SUPERFAMILY a fost utilizat pentru a efectua atribuiri structurale la toate genomurile complet secvențiate. SFLD O clasificare ierarhică a enzimelor care leagă caracteristicile specifice ale structurii secvenței de capacități chimice specifice. TIGRFAMs TIGRFAMs TIGRFAMs este o colecție de familii de proteine, cu alinieri de secvențe multiple curatoriate, modele Markov ascunse (HMM) și adnotări, care oferă un instrument pentru identificarea proteinelor înrudite din punct de vedere funcțional pe baza omologiei secvențelor. Acele intrări care sunt „equivalogs” grupează proteine omoloage care sunt conservate din punct de vedere funcțional.
Tipuri de dateEdit
InterPro constă în șapte tipuri de date furnizate de diferiți membri ai consorțiului:
| Tip de date | Descriere | Baze de date care contribuie |
|---|---|---|
| InterPro Entries | Structurale și/sau domeniile funcționale ale proteinelor prezise utilizând una sau mai multe semnături | Toate cele 13 baze de date membre |
| Semnături din bazele de date membre | Semnături din bazele de date membre. Acestea includ semnăturile care sunt integrate în InterPro, și cele care nu sunt | Toate cele 13 baze de date membre |
| Proteine | Secvențe de proteine | UniProtKB (Swiss-Prot și TrEMBL) |
| Proteom | Colecție de proteine care aparțin unui singur organism | UniProtKB |
| Structura | 3-structuri dimensionale ale proteinelor | PDBe |
| Taxonomie | Informații taxonomice ale proteinelor | UniProtKB |
| Set | Grupuri de familii înrudite din punct de vedere evolutiv | Pfam, CDD |

Tipuri de intrări InterProEdit
Intrările InterPro pot fi defalcate în continuare în cinci tipuri:
- Homologous Superfamily: Un grup de proteine care împărtășesc o origine evolutivă comună, așa cum reiese din asemănările lor structurale, chiar dacă secvențele lor nu sunt foarte asemănătoare. Aceste intrări sunt furnizate în mod specific doar de două baze de date membre: CATH-Gene3D și SUPERFAMILY.
- Familie: Un grup de proteine care au o origine evolutivă comună determinată prin similitudini structurale, funcții înrudite sau homologie de secvență.
- Domeniu: O unitate distinctă într-o proteină cu o anumită funcție, structură sau secvență.
- Repetiție: O secvență de aminoacizi, de obicei nu mai lungă de 50 de aminoacizi, care tinde să se repete de mai multe ori într-o proteină.
- Sit: O secvență scurtă de aminoacizi în care cel puțin un aminoacid este conservat. Acestea includ situri de modificare post-translație, situri conservate, situri de legare și situri active.