Manipularea erorilor este o parte esențială a RxJs, deoarece vom avea nevoie de ea în aproape orice program reactiv pe care îl scriem.
Manipularea erorilor în RxJS nu este probabil la fel de bine înțeleasă ca alte părți ale bibliotecii, dar este de fapt destul de simplu de înțeles dacă ne concentrăm pe înțelegerea mai întâi a contractului Observable în general.
În această postare, vom oferi un ghid complet care conține cele mai comune strategii de tratare a erorilor de care veți avea nevoie pentru a acoperi majoritatea scenariilor practice, începând cu elementele de bază (contractul Observable).
- Tabloul cuprinsului
- Contractul observabil și manipularea erorilor
- RxJs subscribe and error callback
- Exemplu de comportament de finalizare
- Limitări ale gestionarului de erori subscribe
- Operatorul catchError
- Cum funcționează catchError?
- Ce se întâmplă atunci când se aruncă o eroare?
- Strategia de captură și înlocuire
- Strategia Catch and Rethrow
- Dezmembrare Catch and Rethrow
- Utilizarea catchError de mai multe ori într-un lanț Observable
- Operatorul Finalize
- Exemplu de operator finalize
- Strategia de reluare a încercării
- Când să încercăm din nou?
- RxJs retryWhen Operator Marble Diagramă de marmură
- Descompunerea modului în care funcționează retryWhen
- Crearea unui Observabil de notificare
- Strategia de reluare imediată
- Immediate Retry Console Output
- Strategia de reluare întârziată a încercărilor
- Funcția de creare a observabilului timer
- Operatorul delayWhen
- DelayWhen Operator breakdown
- Implementarea strategiei de reluare întârziată
- Retry Strategy Console Output
- Repozitoriu Github în execuție (cu mostre de cod)
- Concluzii
Tabloul cuprinsului
În acest post, vom acoperi următoarele subiecte:
- Contractul Observable și manipularea erorilor
- RxJs subscribe și error callback
- Operatorul catchError
- Captura și înlocuirea Strategy
- throwError și strategia Catch and Rethrow
- Utilizarea catchError de mai multe ori într-un lanț Observable
- Operatorul finalize
- The Retry Strategy
- Then retryWhen Operator
- Crearea unei observabile de notificare
- Immediate Retry Strategy
- Delayed Retry Strategy
- The delayWhen Operator
- Funcția de creare a cronometrului Observable
- Executarea depozitului Github (cu exemple de cod)
- Concluzii
Așa că, fără alte comentarii, să începem cu scufundarea noastră în profunzime în RxJs Error Handling!
Contractul observabil și manipularea erorilor
Pentru a înțelege manipularea erorilor în RxJs, trebuie să înțelegem mai întâi că orice flux dat poate da eroare doar o singură dată. Acest lucru este definit de contractul Observable, care spune că un flux poate emite zero sau mai multe valori.
Contractul funcționează astfel pentru că exact așa funcționează în practică toate fluxurile pe care le observăm în timpul nostru de execuție. Cererile de rețea pot eșua, de exemplu.
Un flux poate, de asemenea, să se finalizeze, ceea ce înseamnă că:
- fluxul și-a încheiat ciclul de viață fără nicio eroare
- după finalizare, fluxul nu va mai emite alte valori
Ca o alternativă la finalizare, un flux poate, de asemenea, să iasă din eroare, ceea ce înseamnă că:
- fluxul și-a încheiat ciclul de viață cu o eroare
- după apariția erorii, fluxul nu va mai emite alte valori
Atenție, finalizarea sau eroarea se exclud reciproc:
- dacă fluxul se finalizează, nu poate ieși din eroare după aceea
- dacă fluxul iese din eroare, nu se poate finaliza după aceea
Atenție, de asemenea, la faptul că nu există nici o obligație ca fluxul să se finalizeze sau să iasă din eroare, aceste două posibilități sunt opționale. Dar numai una dintre cele două se poate întâmpla, nu amândouă.
Aceasta înseamnă că atunci când un anumit flux intră în eroare, nu îl mai putem folosi, conform contractului Observable. Probabil că vă gândiți în acest moment, cum putem recupera atunci după o eroare?
RxJs subscribe and error callback
Pentru a vedea comportamentul de tratare a erorilor RxJs în acțiune, să creăm un flux și să ne abonăm la el. Să ne amintim că apelul de abonare primește trei argumente opționale:
- o funcție de gestionare a succesului, care este apelată de fiecare dată când fluxul emite o valoare
- o funcție de gestionare a erorilor, care este apelată numai dacă apare o eroare. Acest handler primește el însuși eroarea
- o funcție handler de finalizare, care este apelată numai dacă fluxul se finalizează
Exemplu de comportament de finalizare
Dacă fluxul nu dă eroare, atunci aceasta este ceea ce vom vedea în consolă:
HTTP response {payload: Array(9)}HTTP request completed.După cum putem vedea, acest flux HTTP emite o singură valoare, iar apoi se finalizează, ceea ce înseamnă că nu au apărut erori.
Dar ce se întâmplă dacă fluxul aruncă în schimb o eroare? În acest caz, vom vedea în schimb următoarele în consolă:

După cum putem vedea, streamul nu a emis nicio valoare și a comis imediat o eroare. După eroare, nu a avut loc nicio finalizare.
Limitări ale gestionarului de erori subscribe
Manipularea erorilor folosind apelul subscribe este uneori tot ceea ce avem nevoie, dar această abordare de tratare a erorilor este limitată. Folosind această abordare, nu putem, de exemplu, să recuperăm din eroare sau să emitem o valoare alternativă de rezervă care să înlocuiască valoarea pe care o așteptam de la backend.
Să învățăm apoi câțiva operatori care ne vor permite să implementăm câteva strategii mai avansate de tratare a erorilor.
Operatorul catchError
În programarea sincronă, avem opțiunea de a înfășura un bloc de cod într-o clauză try, de a prinde orice eroare pe care ar putea-o arunca cu un bloc catch și apoi de a trata eroarea.
Iată cum arată sintaxa catch sincronă:
Acest mecanism este foarte puternic deoarece putem gestiona într-un singur loc orice eroare care apare în interiorul blocului try/catch.
Problema este că, în Javascript, multe operații sunt asincrone, iar un apel HTTP este un astfel de exemplu în care lucrurile se întâmplă asincron.
RxJs ne oferă ceva apropiat de această funcționalitate, prin intermediul operatorului RxJs catchError.
Cum funcționează catchError?
Ca de obicei și ca în cazul oricărui operator RxJs, catchError este pur și simplu o funcție care primește un Observable de intrare și emite un Observable de ieșire.
Cu fiecare apel către catchError, trebuie să-i transmitem o funcție pe care o vom numi funcția de tratare a erorilor.
Operatorul catchError ia ca intrare un Observable care ar putea da eroare și începe să emită valorile Observabilului de intrare în Observabilul de ieșire.
Dacă nu apare nici o eroare, Observabilul de ieșire produs de catchError funcționează exact în același mod ca și Observabilul de intrare.
Ce se întâmplă atunci când se aruncă o eroare?
Cu toate acestea, dacă apare o eroare, atunci logica catchError va intra în acțiune. Operatorul catchError va prelua eroarea și o va transmite funcției de tratare a erorilor.
Se așteaptă ca această funcție să returneze un Observable care va fi un Observable de înlocuire pentru fluxul care tocmai a suferit o eroare.
Să ne amintim că fluxul de intrare al funcției catchError s-a defectat, astfel încât, în conformitate cu contractul Observable, nu îl mai putem utiliza.
Acest Observable de înlocuire va fi apoi subscris și valorile sale vor fi utilizate în locul Observable-ului de intrare care s-a defectat.
Strategia de captură și înlocuire
Să dăm un exemplu despre modul în care catchError poate fi folosit pentru a furniza un Observable de înlocuire care emite valori de rezervă:
Să defalcăm implementarea strategiei de captură și înlocuire:
- pasăm operatorului catchError o funcție, care este funcția de tratare a erorilor
- funcția de tratare a erorilor nu este apelată imediat și, în general, de obicei nu este apelată
- numai atunci când apare o eroare în Observabilul de intrare al catchError, funcția de tratare a erorilor va fi apelată
- dacă apare o eroare în fluxul de intrare, această funcție returnează atunci un Observable construit cu ajutorul funcției
of() - funcția
of()construiește un Observable care emite o singură valoare () și apoi se finalizează - funcția de tratare a erorilor returnează Observable-ul de recuperare (
of()), care este subscrisă de operatorul catchError - valorile din Observabilul de recuperare sunt apoi emise ca valori de înlocuire în Observabilul de ieșire returnat de catchError
Ca rezultat final, Observabilul http$ nu va mai da eroare! Iată rezultatul pe care îl obținem în consolă:
HTTP response HTTP request completed.După cum putem vedea, callback-ul de tratare a erorilor din subscribe() nu mai este invocat. În schimb, iată ce se întâmplă:
- este emisă valoarea goală a tabloului
- observabilul
http$este apoi completat
După cum putem vedea, observabilul de înlocuire a fost utilizat pentru a oferi o valoare de rezervă implicită () abonaților din http$, în ciuda faptului că observabilul original a dat eroare.
Observați că am fi putut, de asemenea, să adăugăm o gestionare locală a erorilor, înainte de a returna Observabilul de înlocuire!
Și aceasta acoperă strategia Catch and Replace, acum să vedem cum putem folosi și catchError pentru a retrimite eroarea, în loc să furnizăm valori de rezervă.
Strategia Catch and Rethrow
Să începem prin a observa că observabilul de înlocuire furnizat prin catchError poate la rândul său să iasă din eroare, la fel ca orice alt observabil.
Și dacă acest lucru se întâmplă, eroarea va fi propagată la abonații Observabilului de ieșire al catchError.
Acest comportament de propagare a erorilor ne oferă un mecanism pentru a retrimite eroarea prinsă de catchError, după ce am tratat eroarea la nivel local. Putem face acest lucru în felul următor:
Dezmembrare Catch and Rethrow
Să defalcăm pas cu pas implementarea strategiei Catch and Rethrow:
- la fel ca înainte, capturăm eroarea și returnăm un Observable de înlocuire
- dar de data aceasta, în loc să furnizăm o valoare de ieșire de înlocuire ca
, acum tratăm eroarea la nivel local în funcția catchError - în acest caz, pur și simplu înregistrăm eroarea în consolă, dar am putea adăuga în schimb orice logică locală de tratare a erorilor pe care o dorim, cum ar fi, de exemplu, afișarea unui mesaj de eroare către utilizator
- Întoarcem apoi un Observable de înlocuire care, de data aceasta, a fost creat folosind throwError
- throwError creează un Observable care nu emite niciodată nicio valoare. În schimb, acesta emite imediat o eroare folosind aceeași eroare detectată de catchError
- acest lucru înseamnă că observabilul de ieșire al catchError va emite, de asemenea, o eroare cu exact aceeași eroare emisă de intrarea catchError
- acest lucru înseamnă că am reușit să retrimitem cu succes eroarea emisă inițial de observabilul de intrare al catchError către observabilul de ieșire al acestuia
- eroarea poate fi acum tratată în continuare de restul lanțului de observabile, dacă este necesar
Dacă executăm acum codul de mai sus, iată rezultatul pe care îl obținem în consolă:

După cum putem observa, aceeași eroare a fost înregistrată atât în blocul catchError, cât și în funcția de gestionare a erorilor de abonament, așa cum era de așteptat.
Utilizarea catchError de mai multe ori într-un lanț Observable
Rețineți că putem utiliza catchError de mai multe ori în puncte diferite din lanțul Observable, dacă este necesar, și să adoptăm strategii de eroare diferite în fiecare punct al lanțului.
De exemplu, putem, de exemplu, să capturăm o eroare mai sus în lanțul Observable, să o gestionăm local și să o aruncăm din nou, iar apoi, mai jos în lanțul Observable, să capturăm din nou aceeași eroare și, de data aceasta, să furnizăm o valoare de rezervă (în loc să o aruncăm din nou):
Dacă rulăm codul de mai sus, aceasta este ieșirea pe care o obținem în consolă:
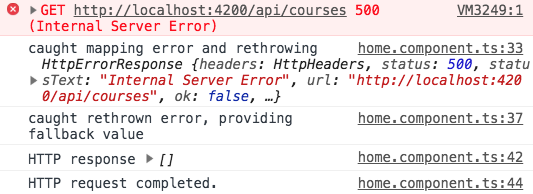
După cum putem vedea, eroarea a fost într-adevăr respinsă inițial, dar nu a ajuns niciodată la funcția de gestionare a erorilor de subscriere. În schimb, a fost emisă valoarea de rezervă , așa cum era de așteptat.
Operatorul Finalize
În afară de blocul catch pentru gestionarea erorilor, sintaxa sincronă Javascript oferă, de asemenea, un bloc finally care poate fi utilizat pentru a rula codul pe care dorim să fie executat întotdeauna.
Blocul finally este utilizat de obicei pentru a elibera resurse costisitoare, cum ar fi, de exemplu, închiderea conexiunilor de rețea sau eliberarea memoriei.
În mod diferit de codul din blocul catch, codul din blocul finally va fi executat independent dacă se aruncă sau nu o eroare:
RxJs ne pune la dispoziție un operator care are un comportament similar cu funcționalitatea finally, numit operatorul finalize.
Nota: nu îl putem numi în schimb operator finally, deoarece finally este un cuvânt cheie rezervat în Javascript
Exemplu de operator finalize
La fel ca operatorul catchError, putem adăuga mai multe apeluri finalize în diferite locuri din lanțul Observable, dacă este necesar, pentru a ne asigura că resursele multiple sunt eliberate corect:
Să rulăm acum acest cod și să vedem cum se execută blocurile multiple de finalizare:

Observați că ultimul bloc de finalizare este executat după funcțiile subscribe value handler și completion handler.
Strategia de reluare a încercării
Ca o alternativă la reluarea erorii sau la furnizarea de valori de rezervă, putem, de asemenea, să încercăm din nou pur și simplu să ne abonăm la Observabilul cu eroare.
Să ne amintim că, odată ce fluxul a suferit o eroare, nu îl mai putem recupera, dar nimic nu ne împiedică să ne abonăm din nou la Observabilul din care a fost derivat fluxul și să creăm un alt flux.
Iată cum funcționează acest lucru:
- vom lua Observabilul de intrare și ne vom abona la el, ceea ce creează un nou flux
- dacă acel flux nu intră în eroare, vom lăsa ca valorile sale să apară la ieșire
- dar dacă fluxul intră în eroare, ne vom abona din nou la Observabilul de intrare și vom crea un flux nou
Când să încercăm din nou?
Întrebarea cea mare aici este: când ne vom abona din nou la Observabilul de intrare și vom încerca din nou să executăm fluxul de intrare?
- Vom încerca din nou imediat?
- Vom aștepta o mică întârziere, sperând că problema este rezolvată și apoi vom încerca din nou?
- avem de gând să încercăm din nou doar de un număr limitat de ori și apoi să eliminăm din eroare fluxul de ieșire?
Pentru a răspunde la aceste întrebări, vom avea nevoie de un al doilea observabil auxiliar, pe care îl vom numi observabilul notificator. Este Notifier
Observable care va determina momentul în care are loc încercarea de reluare a încercării.
Observabilul Notifier va fi utilizat de către operatorul retryWhen, care este inima strategiei Retry.
RxJs retryWhen Operator Marble Diagramă de marmură
Pentru a înțelege cum funcționează Observabilul retryWhen, să aruncăm o privire la diagrama sa de marmură:

Observați că Observabilul care este reîncercat este Observabilul 1-2 din al doilea rând de sus, și nu Observabilul din primul rând.
Observabilul de pe primul rând cu valorile r-r este Observabilul de notificare, care va determina când ar trebui să aibă loc o nouă încercare.
Descompunerea modului în care funcționează retryWhen
Să descompunem ce se întâmplă în această diagramă:
- Observabilul 1-2 este subscris, iar valorile sale sunt reflectate imediat în Observabilul de ieșire returnat de retryCând
- chiar și după ce Observabilul 1-2 este finalizat, acesta poate fi încă re-încercat
- Observabilul de notificare emite atunci o valoare
r, cu mult după ce Observable 1-2 s-a finalizat - valoarea emisă de Observable de notificare (în acest caz
r) poate fi orice - ceea ce contează este momentul în care valoarea
ra fost emisă, pentru că acesta este momentul care va declanșa reintroducerea observabilului 1-2 - Observabilul 1-2 este subscris din nou de către retryWhen, iar valorile sale sunt din nou reflectate în observabilul de ieșire al retryWhen
- Observabilul de notificare va emite din nou o altă valoare
rși se va întâmpla același lucru: valorile unui flux nou subscris 1-2 vor începe să fie reflectate în output-ul lui retryWhen - dar apoi, Observabilul de notificare se termină în cele din urmă
- în acel moment, încercarea de reîncercare în curs de desfășurare a Observabilului 1-2 se finalizează și ea mai devreme, ceea ce înseamnă că doar valoarea 1 a fost emisă, dar nu și 2
După cum putem vedea, retryWhen reîncearcă pur și simplu Observabilul de intrare de fiecare dată când Observabilul de notificare emite o valoare!
Acum că am înțeles cum funcționează retryWhen, haideți să vedem cum putem crea un Observabil de notificare.
Crearea unui Observabil de notificare
Trebuie să creăm Observabilul de notificare direct în funcția transmisă operatorului retryWhen. Această funcție ia ca argument de intrare un Errors Observable, care emite ca valori erorile din Observabilul de intrare.
Acum, prin abonarea la acest Errors Observable, știm exact când apare o eroare. Să vedem acum cum am putea implementa o strategie de reluare imediată folosind Errors Observable.
Strategia de reluare imediată
Pentru a relua observabilul eșuat imediat după apariția erorii, tot ce trebuie să facem este să returnăm Errors Observable fără alte modificări.
În acest caz, nu facem decât să conducem operatorul tap în scopuri de logare, astfel încât Observabilul Errors rămâne neschimbat:
Să ne amintim, Observabilul pe care îl returnăm din apelul funcției retryWhen este Observabilul Notification!
Valoarea pe care o emite nu este importantă, este important doar momentul în care valoarea este emisă, deoarece aceasta este cea care va declanșa o încercare de reluare.
Immediate Retry Console Output
Dacă executăm acum acest program, vom găsi următoarea ieșire în consolă:

După cum putem vedea, cererea HTTP a eșuat inițial, dar apoi s-a încercat o nouă încercare și a doua oară cererea a trecut cu succes.
Să aruncăm acum o privire la întârzierea dintre cele două încercări, inspectând jurnalul de rețea:

După cum putem vedea, a doua încercare a fost emisă imediat după ce a apărut eroarea, așa cum era de așteptat.
Strategia de reluare întârziată a încercărilor
Să implementăm acum o strategie alternativă de recuperare a erorilor, în care așteptăm, de exemplu, 2 secunde de la apariția erorii, înainte de a încerca din nou.
Această strategie este utilă pentru a încerca să recuperăm anumite erori, cum ar fi, de exemplu, solicitările de rețea eșuate cauzate de traficul ridicat al serverului.
În acele cazuri în care eroarea este intermitentă, putem pur și simplu să încercăm din nou aceeași cerere după o scurtă întârziere, iar cererea ar putea trece a doua oară fără nicio problemă.
Funcția de creare a observabilului timer
Pentru a implementa strategia de reluare întârziată, va trebui să creăm un observabil de notificare ale cărui valori sunt emise la două secunde după fiecare apariție a erorii.
Să încercăm apoi să creăm un observabil de notificare folosind funcția de creare a timerului. Această funcție timer va primi câteva argumente:
- o întârziere inițială, înainte de care nu va fi emisă nicio valoare
- un interval periodic, în cazul în care dorim să emitem periodic noi valori
Să ne uităm apoi la diagrama de marmură pentru funcția timer:

După cum putem observa, prima valoare 0 va fi emisă abia după 3 secunde, iar apoi avem o nouă valoare în fiecare secundă.
Observați că al doilea argument este opțional, ceea ce înseamnă că, dacă îl omitem, Observabilul nostru va emite o singură valoare (0) după 3 secunde și apoi se va finaliza.
Acest Observable pare a fi un început bun pentru a putea întârzia încercările noastre de reluare, așa că haideți să vedem cum îl putem combina cu operatorii retryWhen și delayWhen.
Operatorul delayWhen
Un lucru important de reținut în legătură cu operatorul retryWhen este că funcția care definește Observable-ul de notificare este apelată doar o singură dată.
Așa că avem o singură șansă de a defini Observabilul nostru de notificare, care semnalează când ar trebui să se facă încercările de reluare.
Vom defini Observabilul de notificare luând Observabilul de erori și aplicându-i Operatorul delayWhen.
Imaginați-vă că în această diagramă de marmură, Observabilul sursă a-b-c este Observabilul Errors, care emite erori HTTP eșuate în timp:

DelayWhen Operator breakdown
Să urmărim diagrama, și să învățăm cum funcționează Operatorul delayWhen:
- fiecare valoare din Observabilul Erori de intrare va fi întârziată înainte de a apărea în Observabilul de ieșire
- întârzierea pentru fiecare valoare poate fi diferită și va fi creată într-un mod complet flexibil
- pentru a determina întârzierea, vom apela funcția transmisă la delayWhen (numită funcția de selectare a duratei) pentru fiecare valoare a Observabilului de intrare Errors
- această funcție va emite un Observabil care va determina când s-a scurs întârzierea fiecărei valori de intrare
- fiecare dintre valorile a-b-c are propriul Observabil de selectare a duratei, care va emite în cele din urmă o valoare (care poate fi orice) și apoi se va finaliza
- când fiecare dintre aceste Observabile cu selector de durată emite valori, atunci valoarea de intrare corespunzătoare a-b-c va apărea la ieșirea lui delayWhen
- notați că valoarea
bapare la ieșire după valoareac, acest lucru este normal - se datorează faptului că Observabilul selector de durată
b(a treia linie orizontală de sus) și-a emis valoarea doar după Observabilul selector de duratăc, și astfel se explică de cecapare în ieșire înainte deb
Implementarea strategiei de reluare întârziată
Să punem acum toate acestea cap la cap și să vedem cum putem relua consecutiv o cerere HTTP eșuată la 2 secunde după ce apare fiecare eroare:
Să defalcăm ceea ce se întâmplă aici:
- să ne amintim că funcția transmisă la retryWhen va fi apelată doar o singură dată
- întoarcem în acea funcție un Observable care va emite valori de fiecare dată când este nevoie de o reîncercare
- de fiecare dată când apare o eroare, operatorul delayWhen va crea un Observable cu selectare de durată, prin apelarea funcției timer
- acest Observable cu selectare de durată va emite valoarea 0 după 2 secunde, iar apoi va finaliza
- în momentul în care se întâmplă acest lucru, delayWhen Observable știe că întârzierea unei anumite erori de intrare s-a scurs
- numai după ce această întârziere se scurge (2 secunde de la apariția erorii), eroarea apare la ieșirea Observable-ului de notificare
- după ce o valoare este emisă în Observable-ul de notificare, operatorul retryWhen va executa atunci și numai atunci o tentativă de reîncercare
Retry Strategy Console Output
Să vedem acum cum arată acest lucru în consolă! Iată un exemplu de solicitare HTTP care a fost reîncercată de 5 ori, deoarece primele 4 ori au fost în eroare:

Și iată jurnalul de rețea pentru aceeași secvență de reîncercări:

După cum putem vedea, reîncercările au avut loc doar la 2 secunde după ce a apărut eroarea, așa cum era de așteptat!
Și cu aceasta, am încheiat turul nostru ghidat al unora dintre cele mai frecvent utilizate strategii de tratare a erorilor RxJs disponibile, să încheiem acum și să oferim câteva exemple de cod de execuție.
Repozitoriu Github în execuție (cu mostre de cod)
Pentru a încerca aceste strategii multiple de tratare a erorilor, este important să aveți un teren de joacă funcțional unde puteți încerca să gestionați cererile HTTP care eșuează.
Acest teren de joacă conține o mică aplicație în execuție cu un backend care poate fi folosit pentru a simula erori HTTP fie aleatoriu, fie sistematic. Iată cum arată aplicația:

Concluzii
După cum am văzut, înțelegerea manipulării erorilor RxJs constă în a înțelege mai întâi elementele fundamentale ale contractului Observable.
Trebuie să reținem că orice flux dat poate ieși din eroare doar o singură dată, iar acest lucru este exclusiv cu finalizarea fluxului; doar unul dintre cele două lucruri se poate întâmpla.
Pentru a recupera după o eroare, singura modalitate este de a genera cumva un flux de înlocuire ca alternativă la fluxul ieșit din eroare, așa cum se întâmplă în cazul operatorilor catchError sau retryWhen.
Sperăm că v-a plăcut această postare, dacă doriți să învățați mult mai multe despre RxJs, vă recomandăm să consultați cursul RxJs In Practice Course, unde sunt acoperite mult mai detaliat o mulțime de modele și operatori utili.
.