Pentru a face o introducere corectă în nucleele gaussiene, articolul din această săptămână va începe cu o prezentare puțin mai abstractă decât de obicei. Acest nivel de abstractizare nu este strict necesar pentru a înțelege cum funcționează nucleele gaussiene, dar perspectiva abstractă poate fi extrem de utilă ca sursă de intuiție atunci când încercăm să înțelegem distribuțiile de probabilitate în general. Așadar, iată cum stă treaba: voi încerca să dezvolt treptat gradul de abstractizare, dar dacă vreodată vă pierdeți iremediabil sau pur și simplu nu mai puteți rezista, puteți sări până la titlul care spune „Partea practică” în bold – Acolo voi trece la o descriere mai concretă a algoritmului kernelului gaussian. De asemenea, dacă încă aveți probleme, nu vă faceți prea multe griji – Majoritatea postărilor ulterioare de pe acest blog nu vor necesita să înțelegeți nucleele gaussiene, așa că puteți aștepta postul de săptămâna viitoare (sau puteți sări la el dacă citiți acest articol mai târziu).
Reamintiți-vă că un nucleu este o modalitate de a plasa un spațiu de date într-un spațiu vectorial cu dimensiuni mai mari, astfel încât intersecțiile spațiului de date cu hiperplanele din spațiul cu dimensiuni mai mari să determine limite de decizie mai complicate și curbe în spațiul de date. Exemplul principal pe care l-am analizat a fost nucleul care trimite un spațiu de date bidimensional într-un spațiu cu cinci dimensiuni, trimițând fiecare punct cu coordonatele 


În această săptămână, vom trece de la spațiile vectoriale cu dimensiuni mai mari la spațiile vectoriale cu dimensiuni infinite. Puteți vedea cum nucleul cu nouă dimensiuni de mai sus este o extensie a nucleului cu cinci dimensiuni – în esență, am adăugat doar patru dimensiuni suplimentare la sfârșit. Dacă vom continua să adăugăm mai multe dimensiuni în acest fel, vom obține nuclee dimensionale din ce în ce mai mari. Dacă am continua să facem acest lucru „la nesfârșit”, am ajunge să avem un număr infinit de dimensiuni. Rețineți că putem face acest lucru doar în abstract. Calculatoarele se pot ocupa doar de lucruri finite, deci nu pot stoca și procesa calcule în spații vectoriale cu dimensiuni infinite. Dar ne vom preface pentru un minut că putem, doar pentru a vedea ce se întâmplă. Apoi vom transpune lucrurile înapoi în lumea finită.
În acest spațiu vectorial infinit-dimensional ipotetic, putem adăuga vectori în același mod în care o facem cu vectorii obișnuiți, prin simpla adăugare a coordonatelor corespunzătoare. Cu toate acestea, în acest caz, trebuie să adăugăm coordonate la infinit. În mod similar, putem înmulți cu scalari, înmulțind fiecare dintre (infinit de multe) coordonate cu un număr dat. Vom defini nucleul polinomial infinit trimițând fiecare punct 

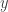


Pentru a ne întoarce în lumea calculatoarelor, putem recupera nucleul nostru original cu cinci dimensiuni prin simpla uitare a tuturor intrărilor, cu excepția primelor cinci. De fapt, spațiul bidimensional original cu cinci dimensiuni este conținut în acest spațiu infinit dimensional. (Nucleul original cu cinci dimensiuni este ceea ce obținem prin proiectarea nucleului polinomial infinit în acest spațiu cu cinci dimensiuni.)
Acum respirați adânc, pentru că vom face un pas mai departe. Luați în considerare, pentru un moment, ce este un vector. Dacă ați urmat vreodată un curs de algebră liniară matematică, poate vă amintiți că vectorii sunt definiți oficial în funcție de proprietățile lor de adunare și înmulțire. Dar voi ignora temporar acest lucru (cu scuzele de rigoare față de orice matematicieni care citesc acest text.) În lumea informatică, ne gândim de obicei la un vector ca fiind o listă de numere. Dacă ați citit până aici, s-ar putea să fiți dispus să lăsați acea listă să fie infinită. Dar eu vreau să vă gândiți la un vector ca fiind o colecție de numere în care fiecare număr este atribuit unui anumit lucru. De exemplu, fiecare număr din tipul nostru obișnuit de vector este atribuit uneia dintre coordonate/caracteristici. Într-unul dintre vectorii noștri infinit, fiecare număr este atribuit unui loc din lista noastră infinit de lungă.
Dar ce ziceți de asta: Ce s-ar întâmpla dacă am defini un vector prin atribuirea unui număr fiecărui punct din spațiul nostru de date (finit dimensional)? Un astfel de vector nu alege un singur punct din spațiul de date; mai degrabă, odată ce ați ales acest vector, dacă indicați orice punct din spațiul de date, vectorul vă spune un număr. Ei bine, de fapt, avem deja un nume pentru asta: Ceva care atribuie un număr fiecărui punct din spațiul de date este o funcție. De fapt, ne-am uitat mult la funcții pe acest blog, sub forma funcțiilor de densitate care definesc distribuțiile de probabilitate. Dar ideea este că ne putem gândi la aceste funcții de densitate ca fiind vectori într-un spațiu vectorial infinit-dimensional.
Cum poate fi o funcție un vector? Ei bine, putem aduna două funcții prin simpla adăugare a valorilor lor în fiecare punct. Aceasta a fost prima schemă pe care am discutat-o pentru combinarea distribuțiilor în postarea de săptămâna trecută despre modelele de amestec. Funcțiile de densitate pentru doi vectori (pete gaussiene) și rezultatul adăugării lor sunt prezentate în figura de mai jos. În mod similar, putem înmulți o funcție cu un număr, ceea ce ar avea ca rezultat o densitate generală mai deschisă sau mai închisă. De fapt, acestea sunt ambele operații cu care probabil că ați exersat foarte mult la orele de algebră și de calcul. Deci nu facem nimic nou încă, doar ne gândim la lucruri într-un mod diferit.

Postul următor este să definim un nucleu din spațiul nostru de date original în acest spațiu infinit dimensional, iar aici avem o mulțime de opțiuni. Una dintre cele mai comune alegeri este funcția Gaussian blob, pe care am văzut-o de câteva ori în postările anterioare. Pentru acest kernel, vom alege o dimensiune standard pentru bloburile gaussiene, adică o valoare fixă pentru abaterea 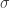
Acum, iată care este problema: pentru a readuce lucrurile în lumea computațională, trebuie să alegem un spațiu vectorial cu dimensiuni finite așezat în acest spațiu vectorial cu dimensiuni infinite și să „proiectăm” spațiul cu dimensiuni infinite în subspațiul cu dimensiuni finite. Vom alege un spațiu finit-dimensional alegând un număr (finit) de puncte în spațiul de date, apoi vom lua spațiul vectorial cuprins de petele gaussiene centrate în acel punct. Acesta este echivalentul ritmului vectorilor definit de primele cinci coordonate ale nucleului polinomial infinit, ca mai sus. Alegerea acestor puncte este importantă, dar vom reveni asupra acestui aspect mai târziu. Deocamdată, întrebarea este cum proiectăm?
Pentru vectori cu dimensiune finită, cel mai comun mod de a defini o proiecție este prin utilizarea produsului punct: Acesta este numărul pe care îl obținem prin înmulțirea coordonatelor corespunzătoare a doi vectori, apoi prin adunarea lor. Astfel, de exemplu, produsul punct al vectorilor tridimensionali 


Am putea face ceva similar cu funcțiile, prin înmulțirea valorilor pe care le iau în punctele corespunzătoare din setul de date. (Cu alte cuvinte, înmulțim cele două funcții împreună.) Dar nu putem apoi să adunăm toate aceste numere, deoarece sunt infinit de multe. În schimb, vom face o integrală! (Rețineți că trec peste o tonă de detalii aici și îmi cer din nou scuze oricărui matematician care citește acest text). Lucrul frumos aici este că, dacă înmulțim două funcții gaussiene și integrăm, numărul este egal cu o funcție gaussiană a distanței dintre punctele centrale. (Deși noua funcție gaussiană va avea o valoare diferită a abaterii.)
Cu alte cuvinte, nucleul gaussian transformă produsul punctelor din spațiul infinit dimensional în funcția gaussiană a distanței dintre punctele din spațiul de date: Dacă două puncte din spațiul de date sunt apropiate, atunci unghiul dintre vectorii care le reprezintă în spațiul kernel va fi mic. Dacă punctele sunt îndepărtate, atunci vectorii corespunzători vor fi apropiați de „perpendicularitate”.
Partea practică
Deci, să trecem în revistă ceea ce avem până acum: Pentru a defini un kernel gaussian 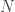
Pentru a înțelege mai bine cum funcționează acest kernel, haideți să ne dăm seama cum arată intersecția unui hiperplan cu spațiul de date. (Oricum, aceasta este ceea ce se face cu kernel-urile de cele mai multe ori.) Reamintim că un plan este definit de o ecuație de forma 


Este încă destul de greu de deslușit, așa că haideți să ne uităm la un exemplu în care fiecare dintre valorile 

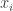





Dacă ajustăm parametrii
Deci, acest lucru ne oferă mai multă flexibilitate pentru alegerea limitei de decizie (sau, cel puțin, un alt tip de flexibilitate), dar rezultatul final va depinde foarte mult de vectorii
Căutarea unei astfel de colecții de puncte este o problemă foarte diferită de cea pe care ne-am concentrat în postările de până acum de pe acest blog și intră în categoria învățării nesupravegheate/analizei descriptive. (În contextul nucleelor, poate fi considerată, de asemenea, ca selecție/inginerie a caracteristicilor). În următoarele postări, vom schimba vitezele și vom începe să explorăm idei în această direcție.
.