Bem vindo à lição nove ‘Manipulando seus Dados’ do SQL Tutorial, que faz parte do Curso de Treinamento SQL. Nesta lição, vamos falar sobre as instruções INSERT, UPDATE, e DELETE do SQL.
Objectivos
Ao final desta lição, você será capaz de:
-
Explicar a instrução INSERT e como ela pode ser usada
-
Descrever a consulta UPDATE com exemplos
-
Explicar a instrução DELETE com exemplo
A instrução INSERT
A instrução INSERT é uma das três instruções pertencentes à instrução so-chamada “linguagem de manipulação de dados” parte do SQL – que é o INSERT, ACTUALIZAR, e APAGAR.
Todos os três comandos permitem alterar dados no banco de dados, não alterando a estrutura, mas alterando o conteúdo. Elas são diferentes da instrução SELECT, que só lhe permite ler os dados da base de dados.
Então a instrução INSERT permite-lhe adicionar novos registos à sua tabela da base de dados. Geralmente, ela é usada para adicionar registros no final da tabela. Uma coisa que é importante sempre que você fizer INSERT é que seus dados precisam satisfazer todas as regras da sua base de dados.
Considerar a imagem mostrada abaixo:
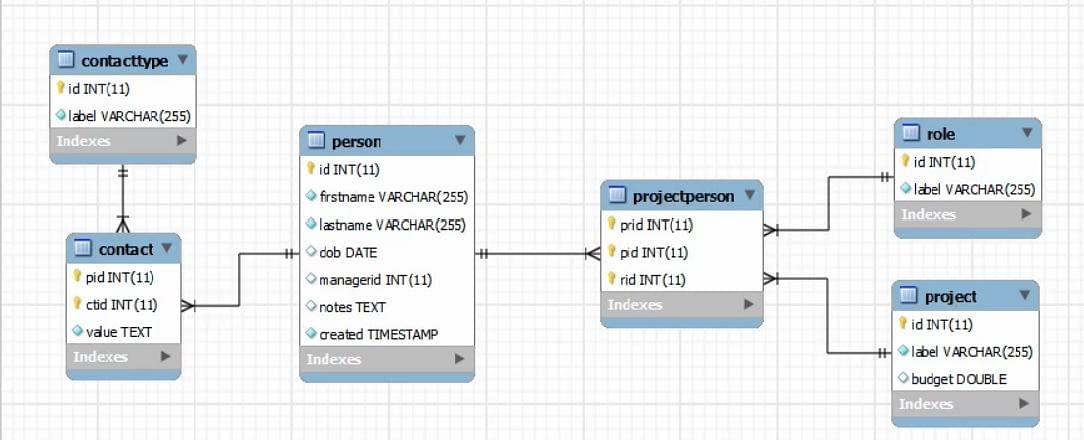
Primeiro, nós olhamos para a tabela Pessoa como um exemplo. Aqui temos a chave primária. As chaves primárias nessa base de dados estão previamente definidas para incrementos automáticos no nosso SQL.
Nunca inserimos a chave primária nós próprios, deixamos isso para a base de dados. Depois temos um primeiro e último nome, que NÃO tem a bandeira NULL. O diamante sólido indica que estes campos são obrigatórios, não podemos ignorá-los.
O último é o timestamp, que NÃO é NULL, mas ao mesmo tempo, o valor padrão é o timestamp atual. Então, mais uma vez, isso definirá automaticamente um carimbo de tempo atual se não colocarmos nenhuma data lá.
Se precisarmos inserir registros em outra tabela, precisamos ter certeza de que os dados realmente existem. Portanto, nestes tipos de tabelas de fim a fim ou em qualquer tipo de situação de chave estrangeira, você sempre precisa ter certeza de que os dados que você inserir lá realmente representam valores válidos nas tabelas referidas.
Deixe-nos usar nossa tabela Pessoa novamente como um ponto de partida.
Tabela Pessoa no início é como mostrado.
Considerar um exemplo mostrado abaixo:
selecionar * de pessoa
inserir em pessoa
valores (7, ‘Martin’, ‘Holzke’, ‘1980-05-05’, ‘xxx’, agora());
>
Só podemos inserir em uma tabela de cada vez. Você pode unir dados usando a função SELECT, mas tradicionalmente falando, você pode fazer manipulação de dados em uma tabela de cada vez.
O que consideramos no exemplo acima é o ‘insert implícito’. Isso significa que não estamos mencionando as colunas que queremos preencher, precisamos colocá-las todas exatamente na ordem em que a tabela existe.
O insert irá combinar os novos valores com as colunas da tabela automaticamente.
Note: Para o insert, update, e delete statement, precisamos ter em mente que as bases de dados não têm um botão de desfazer. Então uma vez que você enviou qualquer valor, ele é armazenado no banco de dados.
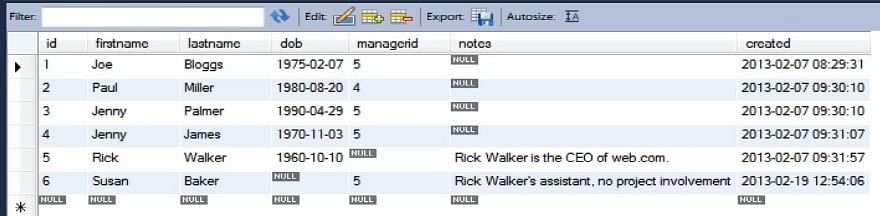
Desde que estamos aprendendo sobre a inserção implícita, precisamos especificar os valores para cada coluna. Assim, ver a tabela da base de dados na mesma tela ajuda imensamente.
Agora, se executarmos o código acima, você pode ver que a tabela foi atualizada e o registro inserido pode ser visto na posição 7.
Além disso, o comando insert não retorna nada, ao contrário do comando SELECT. É por isso que a tela fica em branco depois.
Next. vamos ver a versão explícita, que é altamente recomendada para uso.
selecionar * de pessoa
inserir pessoalmente (primeiro nome, último nome, managerid, dob)
valores (‘Martin’, ‘Holzke’, 5, ‘1980-05-05’);
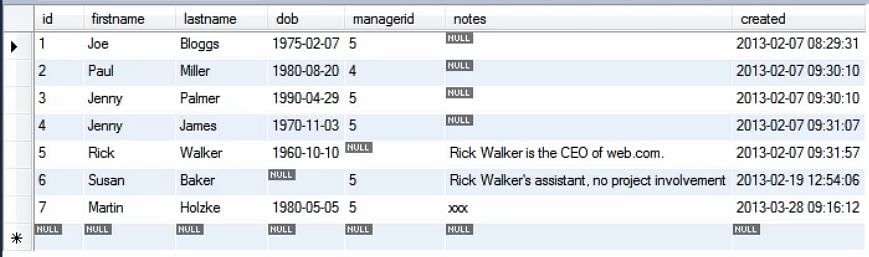
No exemplo acima, acabamos de mencionar 4 valores da tabela. O resto é preenchido por defeito. Quando executamos a consulta, vemos que os novos valores foram adicionados à tabela.
O valor da chave primária é 9 e não 8 porque esse valor porque já foi usado em algum ponto do banco de dados.
Isso é vantajoso para fins de segurança, uma vez que a chave primária não pode ser reutilizada e os erros podem ser identificados.
Vemos também que o valor da coluna ‘criado’ é definido com o timestamp actual quando não o mencionamos explicitamente.
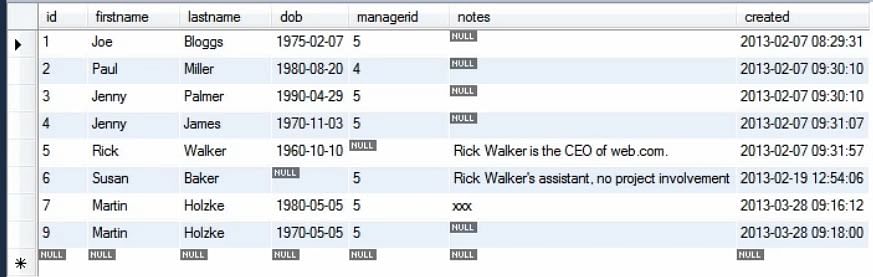
Próximo, para fazer múltiplas inserções, podemos executar a consulta acima, repetidamente, usando valores diferentes.
As múltiplas inserções podem ser executadas usando apenas uma instrução de inserção. Nós adicionamos o novo conjunto de valores que são separados por vírgulas.
selecionar * de pessoa
inserir em pessoa (primeiro nome, último nome, managerid, dob)
valores (‘Martin’, ‘Holzke’, 5, ‘1980-05-05’),
(‘Fred’, ‘Flintstone’, 5, ‘1987-06-02’);
A imagem seguinte mostra a tabela actualizada quando são feitas múltiplas inserções.
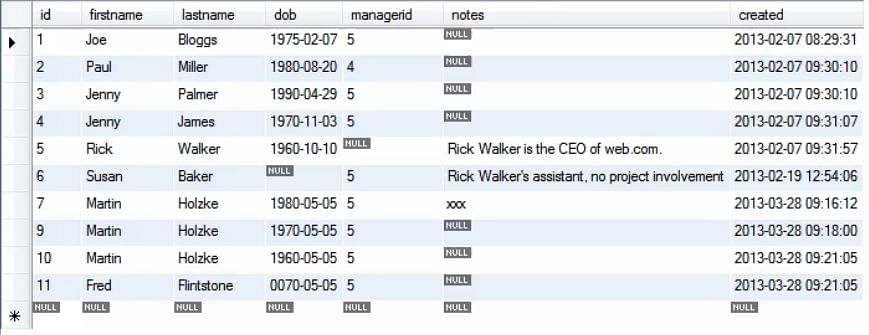
Next, queremos fazer uma inserção seleccionando dados da mesma tabela, para que possa copiar dados que se revelem bastante úteis para povoar uma base de dados. Por exemplo, na migração de dados, você realmente quer copiar dados dentro de uma base de dados ou entre diferentes bases de dados/tabelas.
O código a seguir mostra como copiar dados.
selecionar * da pessoa
inserir pessoalmente (primeiro nome, sobrenome, managerid, dob)
selecionar concat(‘cópia de’, primeiro nome), sobrenome, managerid, dob
de pessoa
onde id>=10
>
A imagem seguinte mostra os valores da tabela quando só executamos o comando select.
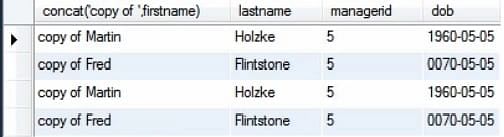
Agora, executamos a consulta junto com o comando insert. Isto pode ser feito apenas selecionando os comandos que queremos executar e executar essa consulta.
A imagem seguinte mostra como a tabela foi modificada após executar a consulta acima.
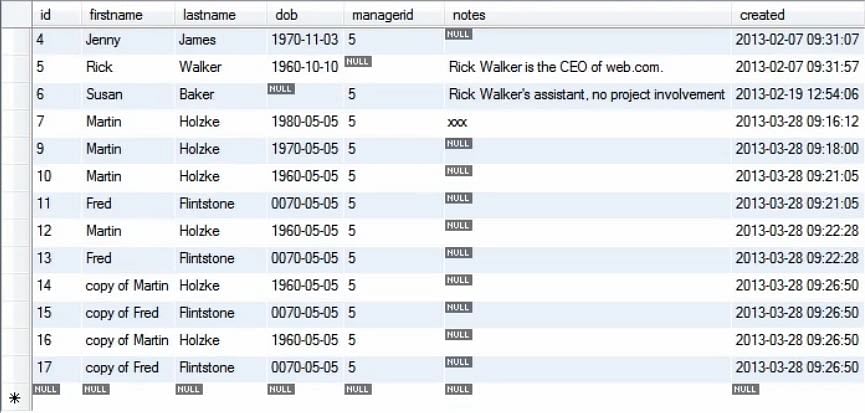 Hence, vimos como copiar valores usando o comando insert pode povoar a base de dados. Geralmente povoamos a base de dados quando executamos as consultas em um ambiente de teste.
Hence, vimos como copiar valores usando o comando insert pode povoar a base de dados. Geralmente povoamos a base de dados quando executamos as consultas em um ambiente de teste.
SQL – Update Query
A consulta ou comando de atualização é o segundo dos três comandos de linguagem de manipulação de dados, que são INSERT, UPDATE e DELETE. Então a consulta UPDATE permite modificar registros existentes em uma tabela.
Desde que estamos falando do SQL como uma linguagem baseada em set, a consulta UPDATE irá funcionar em um conjunto de registros e não em um registro (dependendo de como você executa sua UPDATE).
Então como fazemos todas as nossas atualizações?
Considerar a consulta dada abaixo:
selecionar * de pessoa
where id = 10
update person
set dob = ‘1990-01-01’
where id = 10
Na consulta acima, primeiro selecionamos os registros da tabela Person cujo id é igual a 10. A imagem seguinte mostra o valor que é selecionado.

Em seguida, usamos a consulta Atualizar para definir o DOB para o registro cujo id é 10. Se não usarmos o comando where, ele irá atualizar cada registro da nossa tabela para o valor definido.
Na execução da consulta acima, vemos que o valor dob para a 10ª entrada na tabela foi atualizado.
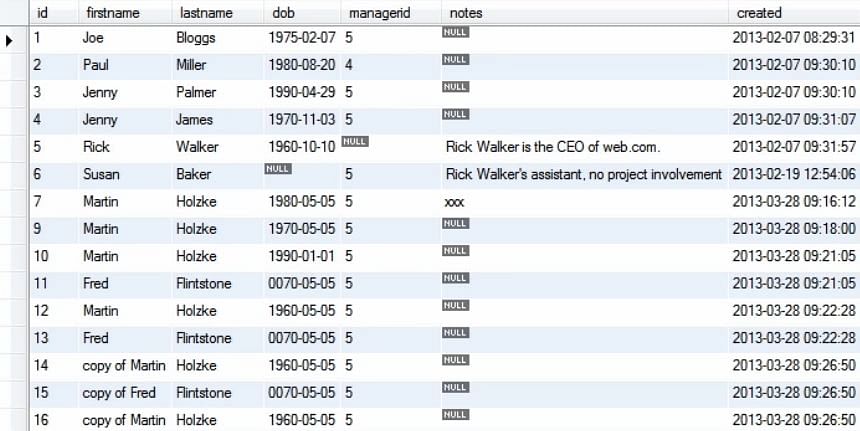 Agora, para atualizar várias coisas em um registro, podemos usar a lista separada por vírgulas.
Agora, para atualizar várias coisas em um registro, podemos usar a lista separada por vírgulas.
Consulte a consulta mostrada abaixo:
selecione * da pessoa
where id = 10
update person
set dob = ‘1990-01-01’, firstname = ‘Mike’
where id = 10
>
Ao executar a consulta acima, obtemos a tabela atualizada como mostrado:
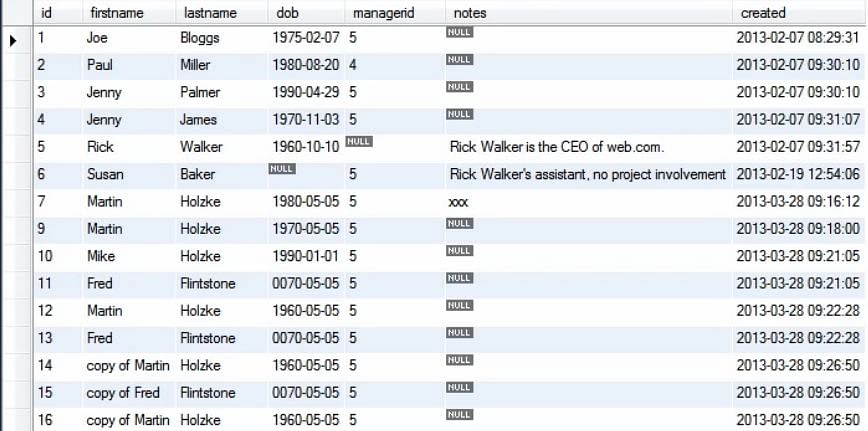
Next, se quisermos alterar mais do que um registo, podemos fazer o seguinte:
selecionar * de pessoa
where firstname = ‘Martin’
update person
set firstname = ‘Mike’
where firstname = ‘Martin’
>
Na consulta acima, mudamos o valor do primeiro nome de Martin para Mike, onde quer que ele existisse anteriormente na tabela Pessoa.
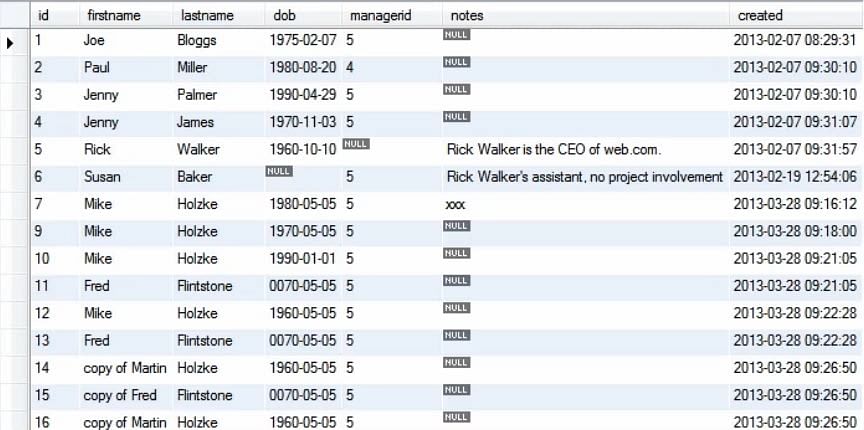
Deixe-nos considerar um exemplo diferente:
A tabela de pessoas não tinha qualquer possibilidade de fazer um pouco mais de coisas numéricas, então vamos considerar a tabela do projeto.
Aqui, tentamos pegar um cenário onde uma manipulação em toda a tabela pode ser desejável.
A tabela do projeto tem três registros no momento, como mostrado.
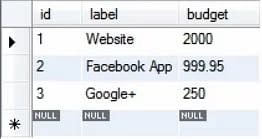
Cada registro tem um valor orçamentário. Digamos que queremos actualizá-los a todos em cerca de 20%. Podemos fazer isso usando a consulta mostrada abaixo:
selecionar * do projeto
atualizar projeto
set budget = orçamento*1.2
>
Então a consulta acima agora aumentaria todos os registros na tabela do projeto em cerca de 20%.
Os registros atualizados são como mostrado abaixo:
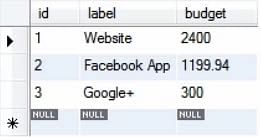
Hence, muitas operações matemáticas podem ser realizadas nos valores como no exemplo mostrado acima.
Uma coisa a ser lembrada ao usar a declaração UPDATE é usar a cláusula ‘where’ sempre que aplicável. Caso contrário, ele irá atualizar os valores de todas as entradas da tabela.
Sql DELETE Statement
Vamos estudar o comando DELETE agora, que é o último comando das três instruções de linguagem de manipulação de dados. O comando DELETE tem a capacidade de apagar um ou mais registos na totalidade. Não estamos falando em excluir o conteúdo individual das colunas porque não podemos fazer isso.
Se você quiser fazer isso, você precisa usar a instrução UPDATE para alterar o conteúdo das colunas individuais. Então DELETE é a exclusão de um registro completo ou múltiplos registros completos.
Como aplicável com a instrução INSERT e UPDATE, uma vez que você exclua uma série de registros, eles desaparecem e não há como recuperá-los.
Tambem precisamos ter certeza de que quando excluímos qualquer registro da tabela, essa entrada (ou seu valor) não está sendo usada por nenhuma outra tabela.
A tabela de pessoas tem as seguintes entradas iniciais.
A declaração DELETE pode ser usada como mostrado na seguinte consulta:
select * from person
where id = 10
delete from person
where id = 10
Na consulta mostrada acima, apagámos o registo cujo valor de id era 10.
Note: Lembre-se de usar a cláusula ‘where’ com a declaração DELETE. Caso contrário, o comando irá rapidamente esvaziar a sua tabela pessoal sem a cláusula ‘where’.
Quando executamos a consulta acima, verificamos que a entrada com o valor id 10 foi apagada e a tabela actualizada é a que aparece. Tudo o resto permanece, excepto a que tem uma chave primária dez.
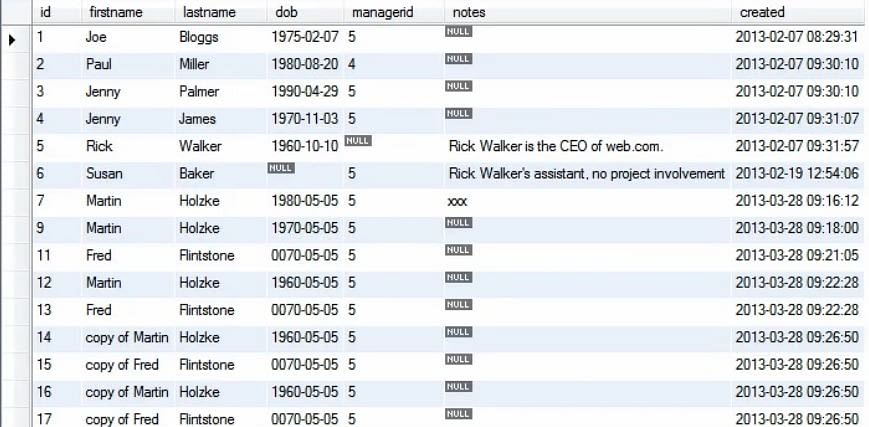
Há situações em que nos queremos ver livres de um bloco inteiro. Por exemplo, desejamos apagar todas as entradas de cópia da tabela de pessoas, como mostrado.
A consulta para excluir todos os registros de cópia da tabela de pessoas é mostrada abaixo:
selecionar * da pessoa
onde primeiro nome como ‘copy%’
apagar da pessoa
onde primeiro nome como ‘copy%’
Na consulta acima, ‘copy%’ indica as afirmações que começam com copy e continuam com qualquer palavra a mais.
Na execução da consulta acima, podemos ver que todos os registos que começaram com ‘Copy’ foram apagados da tabela de pessoas.
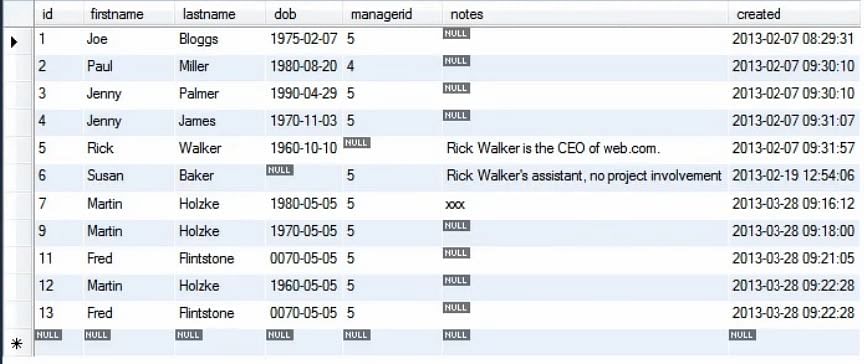
Nota: É sempre recomendado usar a declaração DELETE para uma tabela de cada vez. Não é recomendado usar o comando no caso de tabelas conjuntas.
Conclusão
Com isto, chegamos ao fim desta lição sobre ‘Manipulação de Dados em SQL’. A próxima lição foca o Controle de Transações.
{{lectureCoursePreviewTitle}}} Ver Transcript Watch Video
Para aprender mais, faça o Curso
Treinamento de Certificação de Treinamento SQL
Ir para o Curso
Para aprender mais, Faça o Curso
Treinamento de Certificação de Treinamento SQL Vá ao Curso