A fim de dar uma introdução adequada ao kernel gaussiano, o post desta semana vai começar um pouco mais abstrato do que o normal. Este nível de abstração não é estritamente necessário para entender como os grãos gaussianos funcionam, mas a perspectiva abstrata pode ser extremamente útil como fonte de intuição quando se tenta entender as distribuições de probabilidade em geral. Então é o seguinte: vou tentar construir a abstração lentamente, mas se você se perder ou não aguentar mais, você pode pular para o cabeçalho que diz “A parte prática” em negrito – É aí que eu vou mudar para uma descrição mais concreta do algoritmo do kernel gaussiano. Além disso, se você ainda estiver tendo problemas, não se preocupe muito – A maioria dos posts posteriores neste blog não vai exigir que você entenda os kernels gaussianos, então você pode simplesmente esperar pelo post da próxima semana (ou pular para ele se você estiver lendo isto mais tarde).
Recorde que um kernel é uma forma de colocar um espaço de dados em um espaço vetorial dimensional mais alto de modo que as interseções do espaço de dados com hiperplanos no espaço dimensional mais alto determinem limites de decisão mais complicados e curvos no espaço de dados. O exemplo principal que olhamos foi o kernel que envia um espaço de dados bidimensional para um espaço de dados de cinco dimensões enviando cada ponto com coordenadas 


Esta semana, vamos além dos espaços vectoriais dimensionais superiores para espaços vectoriais infinitamente dimensionais. Você pode ver como o kernel de nove dimensões acima é uma extensão do kernel de cinco dimensões – nós essencialmente só nos debruçamos sobre mais quatro dimensões no final. Se continuarmos a abordar mais dimensões desta forma, vamos obter núcleos dimensionais cada vez mais elevados. Se continuarmos a fazer isto “para sempre”, acabaremos por ter infinitas dimensões. Note que só podemos fazer isso em abstrato. Os computadores só podem lidar com coisas finitas, por isso não podem armazenar e processar computações em espaços vectoriais dimensionais infinitos. Mas nós vamos fingir por um minuto que podemos, só para ver o que acontece. Depois vamos traduzir as coisas de volta para o mundo finito.
Neste hipotético espaço vectorial infinito dimensional, podemos adicionar vectores da mesma forma que fazemos com os vectores normais, bastando para isso adicionar as coordenadas correspondentes. No entanto, neste caso, temos de adicionar coordenadas infinitas. Da mesma forma, podemos multiplicar por escalares, multiplicando cada uma das (infinitamente muitas) coordenadas por um dado número. Vamos definir o kernel polinomial infinito enviando cada ponto 

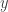


Para voltar ao mundo computacional, nós podemos recuperar nosso kernel quinqu-dimensional original apenas esquecendo todas, exceto as cinco primeiras entradas. Na verdade, o espaço quinqu-dimensional original está contido neste espaço dimensional infinito. (O kernel quinqu-dimensional original é o que obtemos ao projectarmos o kernel polinomial infinito neste espaço quinqu-dimensional.)
Agora respire fundo, porque vamos dar mais um passo em frente. Considere, por um momento, o que é um vector. Se você já tomou uma classe de álgebra linear matemática, você pode se lembrar que os vetores são oficialmente definidos em termos de suas propriedades de adição e multiplicação. Mas vou ignorar isso temporariamente (com desculpas a qualquer matemático que esteja lendo isso.) No mundo da computação, normalmente pensamos em um vetor como sendo uma lista de números. Se você leu até aqui, você pode estar disposto a deixar essa lista ser infinita. Mas quero que pensem num vector como sendo uma colecção de números em que cada número é atribuído a uma coisa em particular. Por exemplo, cada número do nosso tipo normal de vector é atribuído a uma das coordenadas/características. Num dos nossos vectores infinitos, cada número é atribuído a um ponto da nossa lista infinitamente longa.
Mas que tal isto: O que aconteceria se definíssemos um vector atribuindo um número a cada ponto do nosso espaço de dados (dimensional finito)? Tal vetor não escolhe um único ponto no espaço de dados; ao contrário, uma vez que você escolhe esse vetor, se você apontar para qualquer ponto no espaço de dados, o vetor lhe diz um número. Bem, na verdade, nós já temos um nome para isso: Algo que atribui um número a cada ponto no espaço de dados é uma função. Na verdade, nós temos olhado muito para funções neste blog, na forma de funções de densidade que definem distribuições de probabilidade. Mas o ponto é, podemos pensar nessas funções de densidade como vetores em um espaço vetorial infinito.
Como uma função pode ser um vetor? Bem, nós podemos adicionar duas funções simplesmente adicionando os seus valores em cada ponto. Este foi o primeiro esquema que discutimos para combinar distribuições no post da semana passada sobre modelos de mistura. As funções de densidade para dois vetores (blobs gaussianos) e o resultado de adicioná-los são mostrados na Figura abaixo. Podemos multiplicar uma função por um número de forma semelhante, o que resultaria em tornar a densidade total mais clara ou mais escura. Na verdade, estas são duas operações com as quais você provavelmente já teve muita prática na classe de álgebra e cálculo. Então ainda não estamos fazendo nada de novo, estamos apenas pensando nas coisas de uma maneira diferente.

O próximo passo é definir um kernel do nosso espaço de dados original para este espaço dimensional infinito, e aqui temos muitas escolhas. Uma das escolhas mais comuns é a função blob gaussiana que já vimos algumas vezes em posts anteriores. Para este kernel, vamos escolher um tamanho padrão para os blobs gaussianos, ou seja, um valor fixo para o desvio 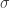
Agora, aqui está o problema: Para trazer as coisas de volta ao mundo computacional, precisamos escolher um espaço vetorial dimensional finito sentado nesse espaço vetorial dimensional infinito e “projetar” o espaço dimensional infinito no subespaço dimensional finito. Escolheremos um espaço finito dimensional escolhendo um número (finito) de pontos no espaço de dados, tomando então o espaço vectorial abrangido pelos blobs gaussianos centrados nesses pontos. Este é o equivalente ao ritmo dos vectores definido pelas primeiras cinco coordenadas do núcleo polinomial infinito, como acima descrito. A escolha destes pontos é importante, mas voltaremos a isso mais tarde. Por enquanto, a questão é como projetar?
Para vetores dimensionais finitos, a maneira mais comum de definir uma projeção é usando o produto ponto: Este é o número que obtemos multiplicando as coordenadas correspondentes de dois vectores, depois adicionando-os a todos juntos. Assim, por exemplo, o produto ponto dos vetores tridimensionais 


Poderíamos fazer algo semelhante com as funções, multiplicando os valores que elas assumem em pontos correspondentes no conjunto de dados. (Em outras palavras, multiplicamos as duas funções juntas.) Mas não podemos então adicionar todos esses números juntos porque são infinitamente muitos deles. Em vez disso, vamos tomar uma integral! (Repare que estou a passar por cima de uma tonelada de detalhes aqui, e peço novamente desculpa a qualquer matemático que esteja a ler isto). O bom aqui é que se multiplicarmos duas funções gaussianas e nos integrarmos, o número é igual a uma função gaussiana da distância entre os pontos centrais. (Embora a nova função gaussiana terá um valor de desvio diferente.)
Em outras palavras, o kernel gaussiano transforma o produto ponto no espaço dimensional infinito na função gaussiana da distância entre os pontos no espaço de dados: Se dois pontos no espaço de dados estiverem próximos, então o ângulo entre os vetores que os representam no espaço do kernel será pequeno. Se os pontos estiverem muito afastados então os vectores correspondentes estarão próximos da “perpendicular”.
A parte prática
Então, vamos rever o que temos até agora: Para definir um kernel gaussiano 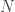
Para entender melhor como esse kernel funciona, vamos descobrir como é a intersecção de um hiperplano com o espaço de dados. (Isto é o que é feito com os kernels a maior parte do tempo, de qualquer forma.) Lembre-se que um plano é definido por uma equação da forma 


Isso ainda é bastante difícil de desempacotar, então vamos olhar para um exemplo onde cada um dos valores 

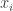





Se ajustarmos os parâmetros
Então, isto nos dá mais flexibilidade para escolher o limite de decisão (ou, pelo menos, um tipo diferente de flexibilidade) mas o resultado final será muito dependente dos vectores
Finding such a collection of points is a very different problem from what we’ve been focusing on the posts so far on this blog, and falls under the category of unsupervised learning/descriptive analytics. (No contexto dos kernels, também pode ser pensado como seleção/engenharia de recursos). Nos próximos posts, vamos trocar de roupa e começar a explorar idéias nesse sentido.