Obsługa błędów jest istotną częścią RxJs, ponieważ będziemy jej potrzebować w prawie każdym reaktywnym programie, który napiszemy.
Obsługa błędów w RxJS prawdopodobnie nie jest tak dobrze rozumiana, jak inne części biblioteki, ale w rzeczywistości jest dość prosta do zrozumienia, jeśli skupimy się na zrozumieniu najpierw kontraktu Observable w ogóle.
W tym poście, zamierzamy dostarczyć kompletny przewodnik zawierający najczęstsze strategie obsługi błędów, które będą potrzebne do pokrycia większości praktycznych scenariuszy, zaczynając od podstaw (kontrakt Observable).
- Table Of Contents
- Kontrakt Observable i obsługa błędów
- RxJs subscribe and error callbacks
- Przykład zachowania zakończenia
- Ograniczenia obsługi błędów subscribe
- Operator catchError
- Jak działa catchError?
- Co się stanie, gdy zostanie rzucony błąd?
- Strategia łapania i zastępowania
- Strategia Catch and Rethrow
- Rozkład catch and retrow
- Używanie catchError wiele razy w łańcuchu Observable
- Operator finalizacji
- Przykład operatora finalize
- Strategia retry
- Kiedy ponowić próbę?
- RxJs retryWhen Operator Marble Diagram
- Przełamując jak działa retryWhen
- Tworzenie Notification Observable
- Immediate Retry Strategy
- Immediate Retry Console Output
- Strategia opóźnionego retry
- Funkcja tworzenia obserwowalnego timera
- Operator delayWhen
- delayWhen Operator breakdown
- Wdrożenie strategii opóźnionego ponownego próbowania
- Wyjście konsoli strategii retry
- Rozruchowe repozytorium Github (z próbkami kodu)
- Wnioski
Table Of Contents
W tym poście, zajmiemy się następującymi tematami:
- Kontrakt Observable i obsługa błędów
- RxJs subskrypcja i wywołania zwrotne błędów
- Operator catchError
- Złap i zamień (ang. Strategia
- throwError i Strategia Catch and Rethrow
- Użycie catchError wiele razy w łańcuchu Observable
- Operator finalize
- The Retry Strategy
- Then retryWhen Operator
- Tworzenie Notification Observable
- Immediate Retry Strategy
- Delayed Retry Strategy
- The delayWhen Operator
- Funkcja tworzenia timera Observable
- Rozruchowe repozytorium Github (z próbkami kodu)
- Wnioski
Więc bez dalszych ceregieli, zacznijmy od naszego głębokiego nurkowania w RxJs Error Handling!
Kontrakt Observable i obsługa błędów
Aby zrozumieć obsługę błędów w RxJs, musimy najpierw zrozumieć, że każdy dany strumień może tylko raz popełnić błąd. Jest to zdefiniowane przez kontrakt Observable, który mówi, że strumień może emitować zero lub więcej wartości.
Kontrakt działa w ten sposób, ponieważ tak właśnie działają w praktyce wszystkie strumienie, które obserwujemy w naszym runtime. Żądania sieciowe mogą zawieść, na przykład.
Strumień może również zakończyć, co oznacza, że:
- strumień zakończył swój cykl życia bez żadnego błędu
- po zakończeniu strumień nie wyemituje żadnych dalszych wartości
Jako alternatywa do zakończenia, strumień może również popełnić błąd, co oznacza, że:
- strumień zakończył swój cykl życia z błędem
- po rzuceniu błędu strumień nie wyemituje żadnych innych wartości
Zauważ, że zakończenie lub błąd wzajemnie się wykluczają:
- jeśli strumień ukończy, nie może potem popełnić błędu
- jeśli strumień popełni błąd, nie może potem ukończyć
Zauważ również, że nie ma obowiązku, aby strumień ukończył lub popełnił błąd, te dwie możliwości są opcjonalne. Ale tylko jedna z tych dwóch możliwości może wystąpić, nie obie.
To oznacza, że kiedy jeden konkretny strumień popełni błąd, nie możemy go już używać, zgodnie z kontraktem Observable. Zapewne zastanawiasz się w tym momencie, jak w takim razie możemy wyjść z błędu?
RxJs subscribe and error callbacks
Aby zobaczyć zachowanie RxJs związane z obsługą błędów w akcji, stwórzmy strumień i zasubskrybujmy go. Pamiętajmy, że wywołanie subskrypcji przyjmuje trzy opcjonalne argumenty:
- funkcja obsługi sukcesu, która jest wywoływana za każdym razem, gdy strumień wyemituje wartość
- funkcja obsługi błędu, która jest wywoływana tylko wtedy, gdy wystąpi błąd. Ten handler odbiera sam błąd
- funkcja obsługi zakończenia, która jest wywoływana tylko wtedy, gdy strumień się zakończy
Przykład zachowania zakończenia
Jeśli strumień nie zakończy się błędem, to jest to, co zobaczylibyśmy w konsoli:
HTTP response {payload: Array(9)}HTTP request completed.Jak widzimy, ten strumień HTTP emituje tylko jedną wartość, a następnie kończy się, co oznacza, że nie wystąpiły żadne błędy.
Ale co się stanie, jeśli zamiast tego strumień wyrzuci błąd? W takim przypadku, w konsoli zobaczymy następujące informacje:

Jak widzimy, strumień nie wyemitował żadnej wartości i natychmiast się wyłączył. Po błędzie nie nastąpiło żadne zakończenie.
Ograniczenia obsługi błędów subscribe
Obsługa błędów za pomocą wywołania subscribe jest czasami wszystkim, czego potrzebujemy, ale to podejście do obsługi błędów jest ograniczone. Korzystając z tego podejścia, nie możemy na przykład odzyskać danych po błędzie lub wyemitować alternatywnej wartości awaryjnej, która zastąpi wartość, której oczekiwaliśmy od backendu.
Poznajmy następnie kilka operatorów, które pozwolą nam zaimplementować bardziej zaawansowane strategie obsługi błędów.
Operator catchError
W programowaniu synchronicznym mamy możliwość zawinięcia bloku kodu w klauzulę try, wyłapania każdego błędu, który może on rzucić, za pomocą bloku catch, a następnie obsłużenia błędu.
Oto jak wygląda składnia catch synchronicznego:
Ten mechanizm jest bardzo potężny, ponieważ możemy obsłużyć w jednym miejscu każdy błąd, który wydarzy się wewnątrz bloku try/catch.
Problem polega na tym, że w Javascript wiele operacji jest asynchronicznych, a wywołanie HTTP jest jednym z takich przykładów, gdzie rzeczy dzieją się asynchronicznie.
RxJs zapewnia nam coś zbliżonego do tej funkcjonalności, poprzez operator RxJs catchError.
Jak działa catchError?
Jak zwykle i jak w przypadku każdego operatora RxJs, catchError jest po prostu funkcją, która przyjmuje Observable wejściową i wyprowadza Observable wyjściową.
Przy każdym wywołaniu catchError musimy przekazać mu funkcję, którą nazwiemy funkcją obsługi błędu.
Operator catchError bierze na wejście obserwowalną, która może popełnić błąd, i zaczyna emitować wartości wejściowej obserwowalnej w swojej wyjściowej obserwowalnej.
Jeśli nie wystąpi błąd, wyjściowa obserwowalna wyprodukowana przez catchError działa dokładnie tak samo jak wejściowa obserwowalna.
Co się stanie, gdy zostanie rzucony błąd?
Jednakże, jeśli wystąpi błąd, wtedy logika catchError zacznie działać. Operator catchError weźmie błąd i przekaże go do funkcji obsługi błędów.
Oczekuje się, że ta funkcja zwróci Observable, która będzie zastępczą Observable dla strumienia, który właśnie się wywalił.
Pamiętajmy, że strumień wejściowy catchError uległ awarii, więc zgodnie z kontraktem Observable nie możemy go już używać.
Ta zastępcza Observable zostanie następnie zasubskrybowana, a jej wartości zostaną użyte w miejsce usuniętej wejściowej Observable.
Strategia łapania i zastępowania
Podajmy przykład, jak catchError może być użyty do dostarczenia zastępczej Observable, która emituje wartości awaryjne:
Rozbijmy implementację strategii łapania i zastępowania:
- przekazujemy do operatora catchError funkcję, która jest funkcją obsługi błędów
- funkcja obsługi błędów nie jest wywoływana od razu, a w ogóle zazwyczaj nie jest wywoływana
- tylko wtedy, gdy w wejściowym Observable z catchError wystąpi błąd, zostanie wywołana funkcja obsługi błędów
- jeśli w strumieniu wejściowym wystąpi błąd, funkcja ta zwraca wtedy Observable zbudowaną przy użyciu funkcji
of() - funkcja
of()buduje Observable, która emituje tylko jedną wartość (), a następnie kończy działanie - funkcja obsługi błędów zwraca Observable odzysku (
of()), która zostaje zasubskrybowana przez operatora catchError - wartości z recovery Observable są następnie emitowane jako wartości zastępcze w wyjściowej Observable zwróconej przez catchError
Jako wynik końcowy, http$ Observable nie będzie już błędem! Oto wynik, który otrzymamy w konsoli:
HTTP response HTTP request completed.Jak widzimy, wywołanie zwrotne obsługi błędu w subscribe() nie jest już wywoływane. Zamiast tego, oto co się dzieje:
- pusta wartość tablicy
jest emitowana - obserwowalna
http$jest następnie zakończona
Jak widzimy, zastępcza obserwowalna została użyta do zapewnienia domyślnej wartości awaryjnej () subskrybentom http$, pomimo faktu, że oryginalna obserwowalna popełniła błąd.
Zauważ, że mogliśmy również dodać jakąś lokalną obsługę błędów, przed zwróceniem zastępczej Observable!
I to obejmuje strategię Catch and Replace, teraz zobaczmy, jak możemy również użyć catchError do ponownego wyrzucenia błędu, zamiast dostarczania wartości awaryjnych.
Strategia Catch and Rethrow
Zacznijmy od zauważenia, że zastępcza obserwowalna dostarczona przez catchError może również wyrzucić błąd, tak jak każda inna obserwowalna.
I jeśli tak się stanie, błąd będzie propagowany do subskrybentów wyjściowej Observable z catchError.
To zachowanie propagacji błędu daje nam mechanizm do ponownego wyrzucenia błędu złapanego przez catchError, po obsłudze błędu lokalnie. Możemy to zrobić w następujący sposób:
Rozkład catch and retrow
Rozłóżmy krok po kroku implementację strategii Catch and Rethrow:
- tak jak poprzednio, łapiemy błąd, i zwracamy zastępczą Observable
- ale tym razem, zamiast dostarczać zastępczą wartość wyjściową jak
, teraz obsługujemy błąd lokalnie w funkcji catchError - w tym przypadku, po prostu logujemy błąd do konsoli, ale zamiast tego możemy dodać dowolną lokalną logikę obsługi błędów, jaką chcemy, taką jak na przykład wyświetlenie komunikatu o błędzie użytkownikowi
- Potem zwracamy zastępczą Observable, która tym razem została utworzona przy użyciu throwError
- throwError tworzy Observable, która nigdy nie emituje żadnej wartości. Zamiast tego, natychmiast wyrzuca błąd używając tego samego błędu wyłapanego przez catchError
- to oznacza, że wyjściowa obserwowalność catchError również wyrzuci błąd z dokładnie tym samym błędem wyrzuconym przez wejście catchError
- to oznacza, że udało nam się pomyślnie wyrzucić błąd początkowo wyrzucony przez wejściową obserwowalność catchError do jej wyjściowej obserwowalności
- błąd może być teraz dalej obsługiwany przez resztę łańcucha obserwowalności, jeśli zajdzie taka potrzeba
Jeśli teraz uruchomimy powyższy kod, oto wynik, jaki otrzymamy w konsoli:

Jak widzimy, ten sam błąd został zalogowany zarówno w bloku catchError, jak i w funkcji obsługi błędu subskrypcji, zgodnie z oczekiwaniami.
Używanie catchError wiele razy w łańcuchu Observable
Zauważ, że możemy używać catchError wiele razy w różnych punktach łańcucha Observable, jeśli jest to potrzebne, i przyjmować różne strategie błędów w każdym punkcie łańcucha.
Możemy, na przykład, złapać błąd w górę łańcucha Observable, obsłużyć go lokalnie i ponownie rzucić, a następnie dalej w dół łańcucha Observable możemy złapać ten sam błąd ponownie i tym razem dostarczyć wartość awaryjną (zamiast ponownego rzucania):
Jeśli uruchomimy powyższy kod, oto dane wyjściowe, które otrzymamy w konsoli:
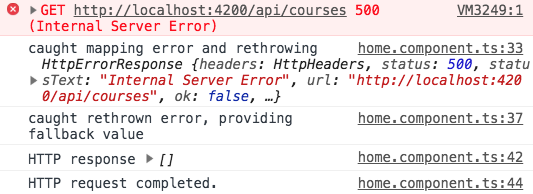
Jak widzimy, błąd rzeczywiście został początkowo rethrow, ale nigdy nie dotarł do funkcji obsługi błędu subscribe. Zamiast tego została wyemitowana wartość fallback , zgodnie z oczekiwaniami.
Operator finalizacji
Poza blokiem catch do obsługi błędów, synchroniczna składnia języka Javascript zapewnia również blok finally, który może być użyty do uruchomienia kodu, który zawsze chcemy wykonać.
Blok finally jest zwykle używany do zwalniania drogich zasobów, takich jak na przykład zamykanie połączeń sieciowych lub zwalnianie pamięci.
W przeciwieństwie do kodu w bloku catch, kod w bloku finally zostanie wykonany niezależnie od tego, czy błąd zostanie wyrzucony czy nie:
RxJs dostarcza nam operatora, który ma podobne zachowanie do funkcjonalności finally, zwanego operatorem finalize.
Uwaga: nie możemy nazwać go operatorem finally, ponieważ finally jest zarezerwowanym słowem kluczowym w Javascript
Przykład operatora finalize
Tak jak operator catchError, możemy dodać wiele wywołań finalize w różnych miejscach w łańcuchu Observable, jeśli to konieczne, aby upewnić się, że wiele zasobów jest poprawnie zwolnionych:
Uruchommy teraz ten kod i zobaczmy, jak wykonywane są wielokrotne bloki finalizujące:

Zauważmy, że ostatni blok finalizujący jest wykonywany po funkcjach obsługi wartości subskrypcji i obsługi zakończenia.
Strategia retry
Jako alternatywa do ponownego wyrzucenia błędu lub dostarczenia wartości awaryjnych, możemy również po prostu ponowić próbę subskrybowania zbłądzonej obserwowalnej.
Pamiętajmy, że gdy strumień się zbłądzi, nie możemy go odzyskać, ale nic nie stoi na przeszkodzie, aby ponownie subskrybować obserwowalną, z której strumień został wyprowadzony, i utworzyć inny strumień.
Oto jak to działa:
- bierzemy wejściową obserwowalną i subskrybujemy ją, co tworzy nowy strumień
- jeśli ten strumień nie popełni błędu, pozwolimy, aby jego wartości pojawiły się na wyjściu
- ale jeśli strumień popełni błąd, zamierzamy ponownie subskrybować wejściową obserwowalną i stworzyć zupełnie nowy strumień
Kiedy ponowić próbę?
Ważnym pytaniem jest, kiedy ponownie zasubskrybujemy wejściową Obserwowalną i spróbujemy ponownie wykonać strumień wejściowy?
- Czy zamierzamy ponowić próbę natychmiast?
- Czy zamierzamy poczekać na małe opóźnienie, mając nadzieję, że problem zostanie rozwiązany i wtedy spróbować ponownie?
- Czy będziemy ponawiać próby tylko ograniczoną ilość razy, a następnie usuniemy błąd ze strumienia wyjściowego?
Aby odpowiedzieć na te pytania, będziemy potrzebować drugiej pomocniczej obserwowalnej, którą nazwiemy obserwowalną Notifier. To właśnie Notifier
Observable będzie określał, kiedy następuje próba retry.
Observable Notifier będzie używany przez operator retryWhen, który jest sercem strategii Retry.
RxJs retryWhen Operator Marble Diagram
Aby zrozumieć, jak działa obserwowalny retryWhen, spójrzmy na jego marmurowy diagram:

Zauważ, że obserwowalny, który jest ponownie próbowany, to 1-2 obserwowalny w drugiej linii od góry, a nie obserwowalny w pierwszej linii.
Obserwowalna w pierwszej linii z wartościami r-r jest Obserwowalną Powiadamiania, która będzie określać kiedy powinna nastąpić próba ponownego próbowania.
Przełamując jak działa retryWhen
Przełammy co się dzieje na tym diagramie:
- Obserwowalna 1-2 zostaje zasubskrybowana, a jej wartości są natychmiast odzwierciedlane w wyjściowej Obserwowalnej zwracanej przez retryWtedy
- nawet po zakończeniu Obserwowalnej 1-2, nadal może być próbowana ponownie
- obserwowalna notyfikująca emituje wartość
r, nawet po wykonaniu Obserwowalnego 1-2 - Wartość wyemitowana przez Obserwowalne powiadomienie (w tym przypadku
r) może być dowolna - ważny jest moment, w którym wartość
rzostała wyemitowana, ponieważ to właśnie spowoduje, że 1-2 Observable zostanie ponownie zasubskrybowana - obserwowalna 1-2 zostanie ponownie zasubskrybowana przez retryWhen, a jej wartości zostaną ponownie odzwierciedlone w wyjściowej Observable z retryWhen
- Obserwowalna powiadomienia ponownie wyemituje kolejną wartość
r, i to samo się dzieje: wartości nowo subskrybowanego strumienia 1-2 zaczną być odzwierciedlane na wyjściu retryWhen - , ale wtedy, notification Observable ostatecznie zakończy
- w tym momencie, trwająca próba retry 1-2 Observable jest również zakończona wcześniej, co oznacza, że tylko wartość 1 została wyemitowana, ale nie 2
Jak widzimy, retryWhen po prostu wykonuje retry Observable za każdym razem, gdy Notification Observable wyemituje wartość!
Teraz, gdy rozumiemy jak działa retryWhen, zobaczmy jak możemy utworzyć Notification Observable.
Tworzenie Notification Observable
Musimy utworzyć Notification Observable bezpośrednio w funkcji przekazywanej do operatora retryWhen. Ta funkcja przyjmuje jako argument wejściowy Errors Observable, która emituje jako wartości błędy wejściowej Observable.
Więc poprzez subskrybowanie tej Errors Observable, wiemy dokładnie kiedy pojawia się błąd. Zobaczmy teraz, jak moglibyśmy zaimplementować strategię natychmiastowego retry przy użyciu Errors Observable.
Immediate Retry Strategy
Aby ponownie wykonać nieudaną obserwację natychmiast po wystąpieniu błędu, wszystko, co musimy zrobić, to zwrócić Errors Observable bez żadnych dalszych zmian.
W tym przypadku, my tylko piping the tap operator for logging purposes, so the Errors Observable remains unchanged:
Pamiętajmy, że Observable, którą zwracamy z wywołania funkcji retryWhen jest Notification Observable!
Wartość, którą emituje nie jest ważna, ważne jest tylko, kiedy wartość zostanie wyemitowana, ponieważ to jest to, co będzie wyzwalać próbę retry.
Immediate Retry Console Output
Jeśli teraz wykonamy ten program, w konsoli znajdziemy następujące dane wyjściowe:

Jak widzimy, żądanie HTTP początkowo nie powiodło się, ale następnie spróbowano ponowić próbę i za drugim razem żądanie przeszło pomyślnie.
Spójrzmy teraz na opóźnienie między dwiema próbami, sprawdzając dziennik sieciowy:

Jak widzimy, druga próba została wydana natychmiast po wystąpieniu błędu, zgodnie z oczekiwaniami.
Strategia opóźnionego retry
Zaimplementujmy teraz alternatywną strategię odzyskiwania błędów, w której czekamy na przykład 2 sekundy po wystąpieniu błędu, zanim podejmiemy ponowną próbę.
Strategia ta jest przydatna przy próbach odzyskiwania po pewnych błędach, takich jak na przykład nieudane żądania sieciowe spowodowane dużym ruchem na serwerze.
W tych przypadkach, gdy błąd jest przerywany, możemy po prostu ponowić próbę tego samego żądania po krótkim opóźnieniu, a żądanie może przejść za drugim razem bez żadnego problemu.
Funkcja tworzenia obserwowalnego timera
Aby zaimplementować strategię Delayed Retry, będziemy musieli utworzyć obserwowalną notyfikację, której wartości będą emitowane dwie sekundy po wystąpieniu każdego błędu.
Spróbujmy zatem utworzyć obserwowalną notyfikację za pomocą funkcji tworzenia timera. Funkcja timera przyjmie kilka argumentów:
- początkowe opóźnienie, przed którym nie będą emitowane żadne wartości
- okresowy interwał, na wypadek gdybyśmy chcieli okresowo emitować nowe wartości
Przyjrzyjrzyjmy się następnie diagramowi marmurkowemu dla funkcji timera:

Jak widzimy, pierwsza wartość 0 zostanie wyemitowana dopiero po 3 sekundach, a potem co sekundę mamy nową wartość.
Zauważ, że drugi argument jest opcjonalny, co oznacza, że jeśli go pominiemy nasz Observable będzie emitował tylko jedną wartość (0) po 3 sekundach, a następnie zakończy działanie.
Ta obserwowalna wygląda jak dobry początek do opóźniania prób ponawiania prób, więc zobaczmy jak możemy ją połączyć z operatorami retryWhen i delayWhen.
Operator delayWhen
Jedną ważną rzeczą do zapamiętania w operatorze retryWhen, jest to, że funkcja, która definiuje obserwowalną notyfikację jest wywoływana tylko raz.
Więc mamy tylko jedną szansę na zdefiniowanie naszej Obserwowalnej Powiadamiania, która sygnalizuje kiedy należy ponowić próbę retry.
Zdefiniujemy Obserwowalną Powiadamiania biorąc Obserwowalną Błędów i stosując ją do Operatora delayWhen.
Wyobraźmy sobie, że w tym marmurowym diagramie, źródłowa obserwowalna a-b-c jest obserwowalną Errors, która emituje nieudane błędy HTTP w czasie:

delayWhen Operator breakdown
Prześledźmy diagram i dowiedzmy się jak działa operator delayWhen:
- każda wartość w wejściowej Errors Observable będzie opóźniona zanim pojawi się w wyjściowej Observable
- opóźnienie na każdą wartość może być inne, i będzie tworzone w całkowicie elastyczny sposób
- w celu określenia opóźnienia, wywołamy funkcję przekazaną do delayWhen (zwaną funkcją selektora czasu trwania) dla każdej wartości wejściowej Errors Observable
- ta funkcja będzie emitować Observable, która będzie określać kiedy upłynęło opóźnienie każdej wartości wejściowej
- każda z wartości a-b-c ma swój własny selektor czasu trwania Observable, która w końcu wyemituje jedną wartość (to może być cokolwiek), a następnie zakończy
- gdy każda z tych selektorów czasu trwania Observables wyemituje wartości, to odpowiadająca im wartość wejściowa a-b-c pojawi się na wyjściu delayWhen
- notice that the value
bshows up in the output after the valuec, this is normal - this is because the
bduration selector Observable (the third horizontal line from the top) only emitted its value after the duration selector Observable ofc, i to wyjaśnia, dlaczegocpojawia się na wyjściu przedb
Wdrożenie strategii opóźnionego ponownego próbowania
Złóżmy to wszystko razem i zobaczmy, jak możemy kolejno ponawiać nieudane żądania HTTP 2 sekundy po wystąpieniu każdego błędu:
Rozbijmy to, co się tutaj dzieje:
- let’s remember that the function passed to retryWhen is going to be called only once
- we are returning in that function an Observable that will emit values whenever a retry is needed
- each every time that there is an error, operator delayWhen stworzy Observable z selektorem czasu trwania, poprzez wywołanie funkcji timer
- ten selektor czasu trwania Observable wyemituje wartość 0 po 2 sekundach, a następnie zakończy działanie
- jak tylko to się stanie, delayWhen Observable wie, że upłynęło opóźnienie danego błędu na wejściu
- tylko gdy to opóźnienie upłynie (2 sekundy po wystąpieniu błędu), błąd pojawi się na wyjściu powiadomienia Observable
- gdy wartość zostanie wyemitowana w powiadomieniu Observable, operator retryWhen wykona wtedy i tylko wtedy próbę retry
Wyjście konsoli strategii retry
Zobaczmy teraz, jak to wygląda w konsoli! Oto przykład żądania HTTP, które było ponawiane 5 razy, ponieważ pierwsze 4 razy zakończyły się błędem:

A oto log sieciowy dla tej samej sekwencji ponawiania prób:

Jak widzimy, ponawianie prób nastąpiło dopiero 2 sekundy po wystąpieniu błędu, zgodnie z oczekiwaniami!
I tym samym zakończyliśmy naszą wycieczkę po niektórych z najczęściej używanych strategii obsługi błędów RxJs, teraz zawińmy sprawy i dostarczmy trochę działającego przykładowego kodu.
Rozruchowe repozytorium Github (z próbkami kodu)
Aby wypróbować te liczne strategie obsługi błędów, ważne jest posiadanie działającego placu zabaw, gdzie można spróbować obsługi nieudanych żądań HTTP.
Ten plac zabaw zawiera małą działającą aplikację z backendem, która może być używana do symulowania błędów HTTP losowo lub systematycznie. Oto jak wygląda ta aplikacja:

Wnioski
Jak widzieliśmy, zrozumienie obsługi błędów RxJs polega na zrozumieniu podstaw kontraktu Observable.
Musimy pamiętać, że dowolny strumień może tylko raz popełnić błąd i jest to wyłączne z zakończeniem strumienia; tylko jedna z tych dwóch rzeczy może się zdarzyć.
Aby odzyskać po błędzie, jedynym sposobem jest wygenerowanie w jakiś sposób strumienia zastępczego jako alternatywy dla błędnego strumienia, tak jak to się dzieje w przypadku operatorów catchError lub retryWhen.
Mam nadzieję, że podobał Ci się ten post, jeśli chciałbyś dowiedzieć się o wiele więcej o RxJs, polecamy sprawdzić kurs RxJs In Practice Course, gdzie wiele przydatnych wzorców i operatorów jest omówionych znacznie bardziej szczegółowo.
Mam nadzieję, że podobał Ci się ten wpis, jeśli chciałbyś dowiedzieć się o wiele więcej o RxJs, polecamy sprawdzić kurs RxJs In Practice Course, gdzie wiele przydatnych wzorców i operatorów jest omówionych znacznie bardziej szczegółowo.