Witamy w lekcji dziewiątej 'Manipulowanie danymi’ samouczka SQL, który jest częścią kursu szkoleniowego SQL. W tej lekcji porozmawiamy o instrukcjach INSERT, UPDATE i DELETE języka SQL.
Cele
Do końca tej lekcji, będziesz w stanie:
-
Wyjaśnić instrukcję INSERT i sposoby jej użycia
-
Opisać zapytanie UPDATE na przykładach
-
Wyjaśnić instrukcję DELETE na przykładzie
Konstrukcja INSERT
Konstrukcja INSERT jest jedną z trzech instrukcji należących do tzw.części SQL zwanej „językiem manipulacji danymi” – czyli INSERT, UPDATE, i DELETE.
Wszystkie trzy instrukcje pozwalają na zmianę danych w bazie danych, nie zmieniając struktury, ale zmieniając zawartość. Różnią się one od instrukcji SELECT, która pozwala tylko na odczytywanie danych z bazy danych.
Więc instrukcja INSERT pozwala na dodawanie nowych rekordów do tabeli bazy danych. Ogólnie rzecz biorąc, jest ona używana do dodawania rekordów na końcu tabeli. Jedna rzecz, która jest ważna za każdym razem, gdy robisz INSERT jest to, że dane muszą spełniać wszystkie reguły w bazie danych.
Rozważmy obraz pokazany poniżej:
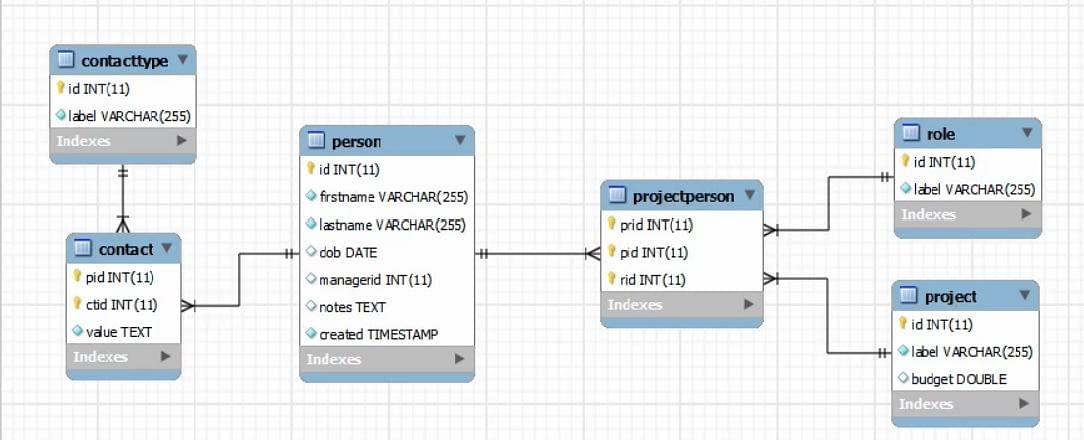
Pierwszy, patrzymy na tabeli Osoba jako przykład. Mamy tu klucz główny. Klucze podstawowe w tej bazie danych są wcześniej ustawione na auto increment w naszym SQL.
Nigdy nie wstawiamy klucza podstawowego samodzielnie, zostawiamy to bazie danych. Następnie mamy firstname i lastname, które mają flagę NOT NULL. Solidny diament wskazuje, że te pola są obowiązkowe, nie możemy ich pominąć.
Ostatni jest timestamp, który jest NOT NULL, ale w tym samym czasie, domyślną wartością jest aktualny timestamp. Więc ponownie, to automatycznie ustawi aktualny znacznik czasu, jeśli nie umieścimy tam żadnej daty.
Jeśli potrzebujemy wstawić rekordy do innej tabeli, musimy się upewnić, że dane faktycznie istnieją. Tak więc w tego rodzaju tabelach typu koniec do końca lub w każdym rodzaju sytuacji z kluczem obcym, zawsze trzeba się upewnić, że dane, które tam wstawiamy, rzeczywiście reprezentują prawidłowe wartości w tabelach, do których się odwołujemy.
Użyjmy naszej tabeli Person ponownie jako punktu wyjścia.
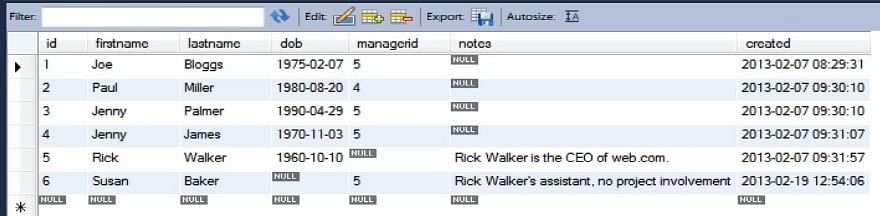
Tabela Person na początku jest taka, jak pokazano.
Rozważmy przykład pokazany poniżej:
select * from person
insert into person
values (7, 'Martin’, 'Holzke’, '1980-05-05′, 'xxx’, now());
Możemy wstawiać dane tylko do jednej tabeli na raz. Możesz łączyć dane za pomocą funkcji SELECT, ale tradycyjnie rzecz biorąc, możesz wykonywać manipulacje danymi na jednej tabeli w tym samym czasie.
To, co rozważaliśmy w powyższym przykładzie, to 'implicit insert.’ Oznacza to, że nie wymieniamy kolumn, które chcemy wypełnić, musimy umieścić je wszystkie dokładnie w takiej kolejności, w jakiej istnieje tabela.
Wstawka automatycznie dopasuje nowe wartości do kolumn tabeli.
Uwaga: W przypadku instrukcji wstawiania, aktualizacji i usuwania musimy pamiętać, że bazy danych nie mają przycisku cofania. Tak więc po wysłaniu jakiejkolwiek wartości, zostanie ona zapisana w bazie danych.
Ponieważ uczymy się o niejawnym wstawianiu, musimy określić wartości dla każdej kolumny. Tak więc zobaczenie tabeli bazy danych na tym samym ekranie jest bardzo pomocne.
Teraz, jeśli uruchomimy powyższy kod, możesz zobaczyć, że tabela została zaktualizowana i wstawiony rekord jest widoczny na pozycji 7.
Ponadto, instrukcja insert nie zwraca niczego, w przeciwieństwie do instrukcji SELECT. To dlatego ekran jest pusty.
Następnie. zobaczmy wersję explicit, której użycie jest wysoce zalecane.
select * from person
insert into person (firstname, lastname, managerid, dob)
values (’Martin’, 'Holzke’, 5, '1980-05-05′);
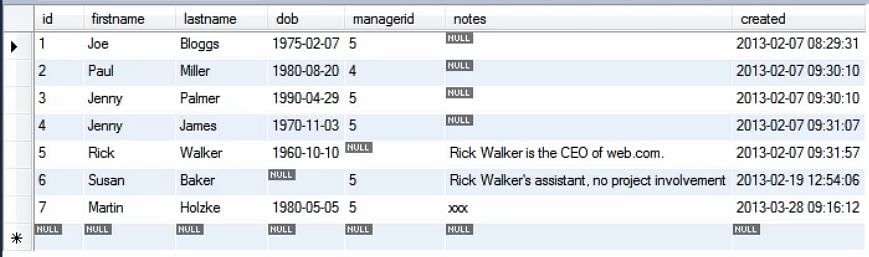
W powyższym przykładzie wymieniliśmy tylko 4 wartości tabeli. Reszta jest domyślnie wypełniana. Kiedy uruchamiamy zapytanie, widzimy, że nowe wartości zostały dodane do tabeli.
Wartość klucza głównego jest 9, a nie 8, ponieważ ta wartość, ponieważ był używany w pewnym momencie w bazie danych już.
Jest to korzystne dla celów bezpieczeństwa, ponieważ klucz główny nie może być ponownie użyty i błędy mogą być zidentyfikowane.
Widzimy również, że wartość kolumny 'created’ jest ustawiona z bieżącym znacznikiem czasu, gdy wyraźnie o tym nie wspominamy.
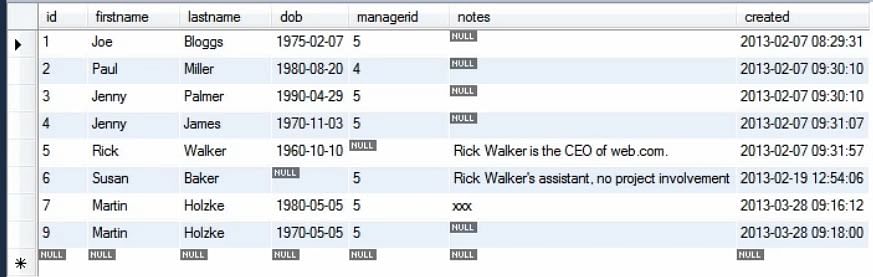
Następnie, aby wykonać wielokrotne wstawienia, możemy uruchomić powyższe zapytanie, ponownie i ponownie, używając różnych wartości.
Krotne wstawienia mogą być wykonane przy użyciu tylko jednej instrukcji wstawiania. Dodajemy nowy zestaw wartości, które są oddzielone przecinkami.
select * from person
insert into person (firstname, lastname, managerid, dob)
values (’Martin’, 'Holzke’, 5, '1980-05-05′),
(’Fred’, 'Flintstone’, 5, '1987-06-02′);
Następujący obrazek przedstawia zaktualizowaną tabelę, gdy wykonano wiele wstawek.
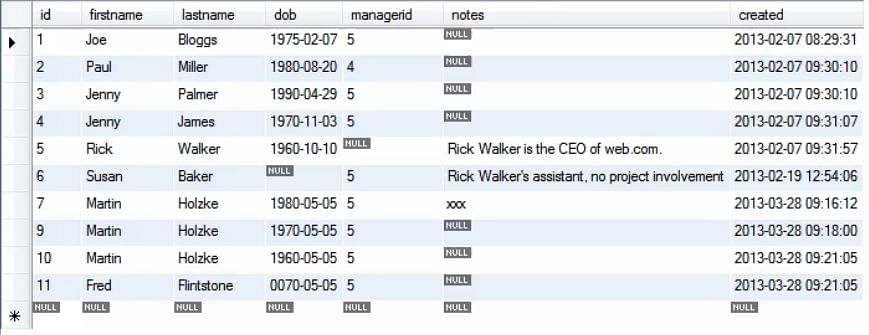
Następnie chcemy wykonać wstawkę wybierając dane z tej samej tabeli, więc można kopiować dane, co okazuje się całkiem przydatne przy wypełnianiu bazy danych. Na przykład, podczas migracji danych, chcemy skopiować dane w obrębie bazy danych lub pomiędzy różnymi bazami danych/tabelami.
Poniższy kod pokazuje jak skopiować dane.
select * from person
insert into person (firstname, lastname, managerid, dob)
select concat(’copy of’, firstname), lastname, managerid, dob
from person
where id>=10
Następujący obrazek pokazuje wartości tabeli, gdy wykonujemy tylko instrukcję select.
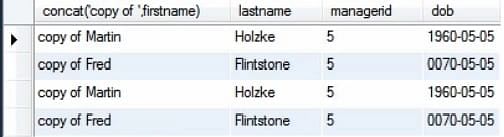
Teraz uruchamiamy zapytanie wraz z instrukcją insert. Można to zrobić poprzez wybranie polecenia, które chcemy uruchomić i wykonanie tego zapytania.
Następny obrazek pokazuje jak tabela została zmodyfikowana po uruchomieniu powyższego zapytania.
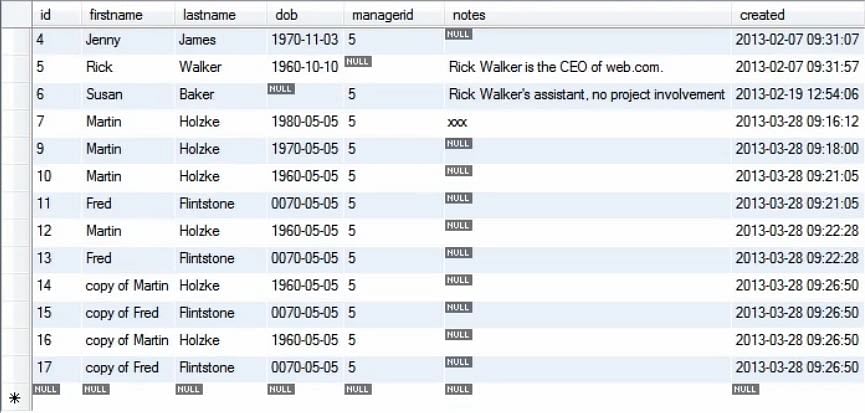 W ten sposób zobaczyliśmy jak kopiowanie wartości przy użyciu instrukcji insert może wypełnić bazę danych. Zazwyczaj wypełniamy bazę danych, gdy uruchamiamy zapytania w środowisku testowym.
W ten sposób zobaczyliśmy jak kopiowanie wartości przy użyciu instrukcji insert może wypełnić bazę danych. Zazwyczaj wypełniamy bazę danych, gdy uruchamiamy zapytania w środowisku testowym.
SQL – Update Query
Kwerenda lub instrukcja update jest drugą z trzech instrukcji języka manipulacji danymi, którymi są INSERT, UPDATE i DELETE. Tak więc zapytanie UPDATE pozwala na modyfikację istniejących rekordów w tabeli.
Ponieważ mówimy o SQL jako o języku opartym na zestawach, zapytanie UPDATE będzie działać na zestawie rekordów, a nie na jednym rekordzie (w zależności od tego, jak uruchomisz UPDATE).
Więc jak wykonujemy wszystkie nasze aktualizacje?
Rozważmy zapytanie podane poniżej:
select * from person
where id = 10
update person
set dob = '1990-01-01′
where id = 10
W powyższym zapytaniu, najpierw wybieramy rekordy z tabeli Person, których id jest równe 10. Poniższy obrazek pokazuje wartość, która zostaje wybrana.

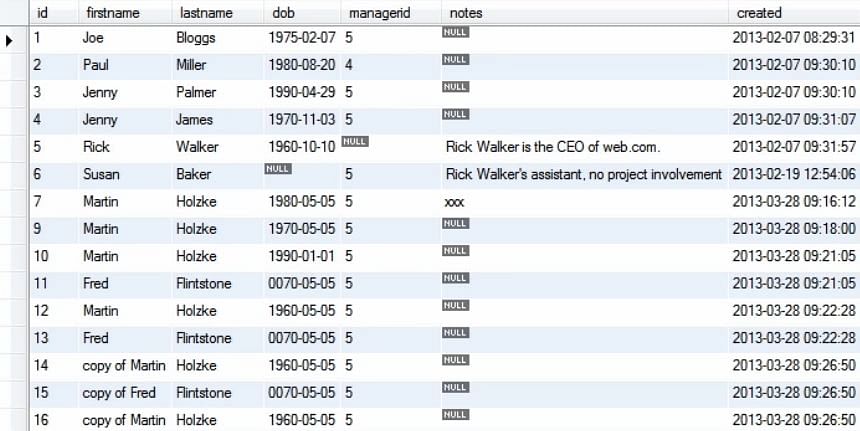
Następnie używamy zapytania Update, aby ustawić DOB dla rekordu, którego id jest równe 10. Jeśli nie użyjemy instrukcji where, zaktualizuje ona każdy rekord w naszej tabeli do ustawionej wartości.
Po wykonaniu powyższego zapytania widzimy, że wartość dob dla 10 wpisu w tabeli została zaktualizowana.
 Teraz, aby zaktualizować wiele rzeczy w rekordzie, możemy użyć listy oddzielonej przecinkami.
Teraz, aby zaktualizować wiele rzeczy w rekordzie, możemy użyć listy oddzielonej przecinkami.
Rozważmy zapytanie przedstawione poniżej:
select * from person
where id = 10
update person
set dob = '1990-01-01′, firstname = 'Mike’
where id = 10
Po wykonaniu powyższego zapytania otrzymujemy zaktualizowaną tabelę jak na rysunku:
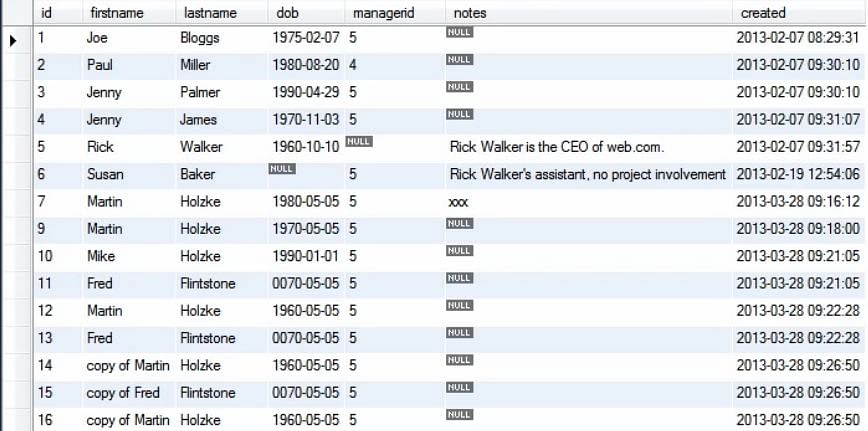
Następnie, jeśli chcemy zmienić więcej niż jeden rekord, możemy wykonać następujące czynności:
select * from person
where firstname = 'Martin’
update person
set firstname = 'Mike’
where firstname = 'Martin’
W powyższym zapytaniu zmieniliśmy wartość firstname z Martin na Mike, gdziekolwiek wcześniej występowała w tabeli Person.
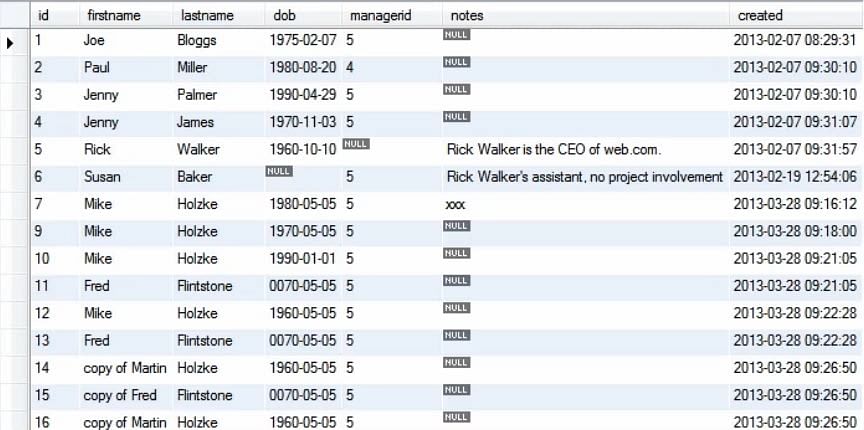
Rozważmy inny przykład:
W tabeli Osoba nie było miejsca na robienie nieco bardziej numerycznych rzeczy, więc rozważmy tabelę Projekt.
Próbujemy tutaj przyjąć scenariusz, w którym obsługa całej tabeli może być pożądana.
Tabela projektu ma w tej chwili trzy rekordy, jak pokazano na rysunku.
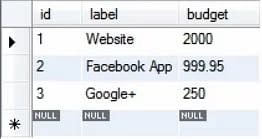
Każdy rekord ma wartość budżetu. Załóżmy, że chcemy je wszystkie podnieść o około 20%. Możemy to zrobić za pomocą zapytania przedstawionego poniżej:
select * from project
update project
set budget = budget*1.2
Więc powyższe zapytanie zwiększyłoby teraz wszystkie rekordy w tabeli project o dwadzieścia procent.
Zaktualizowane rekordy są takie, jak pokazano poniżej:
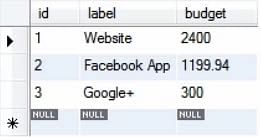
Więc, wiele operacji matematycznych może być wykonywanych na wartościach, jak w przykładzie pokazanym powyżej.
Jedną rzeczą do zapamiętania podczas używania instrukcji UPDATE jest użycie klauzuli 'where’, gdziekolwiek ma to zastosowanie. W przeciwnym razie zaktualizuje wartości wszystkich wpisów w tabeli.
SQL Instrukcja DELETE
Zapoznajmy się teraz z instrukcją DELETE, która jest ostatnią z trzech instrukcji języka manipulacji danymi. Polecenie DELETE ma możliwość usunięcia jednego lub więcej rekordów w całości. Nie mówimy tu o usuwaniu zawartości poszczególnych kolumn, ponieważ nie możemy tego zrobić.
Jeśli chcesz to zrobić, musisz użyć instrukcji UPDATE, aby zmienić zawartość poszczególnych kolumn. Tak więc DELETE to usunięcie pełnego rekordu lub wielu pełnych rekordów.
Jak to ma zastosowanie w przypadku instrukcji INSERT i UPDATE, po usunięciu serii rekordów, już ich nie ma i nie ma sposobu, aby je odzyskać.
Musimy również upewnić się, że kiedy usuwamy jakikolwiek rekord z tabeli, ten wpis (lub jego wartość) nie jest używany przez żadną inną tabelę.
Tabela osoby ma następujące początkowe wpisy.
Konstatkcja DELETE może być użyta w sposób przedstawiony w następującym zapytaniu:
select * from person
where id = 10
delete from person
where id = 10
W przedstawionym powyżej zapytaniu usunęliśmy rekord, którego wartość id wynosiła 10.
Uwaga: Pamiętaj, aby używać klauzuli 'where’ z instrukcją DELETE. W przeciwnym razie, instrukcja szybko opróżni tabelę osób bez klauzuli 'where’
Gdy wykonamy powyższe zapytanie, stwierdzimy, że wpis o wartości id 10 został usunięty, a zaktualizowana tabela wygląda jak pokazano. Wszystko inne pozostało, oprócz tego z kluczem głównym ten.
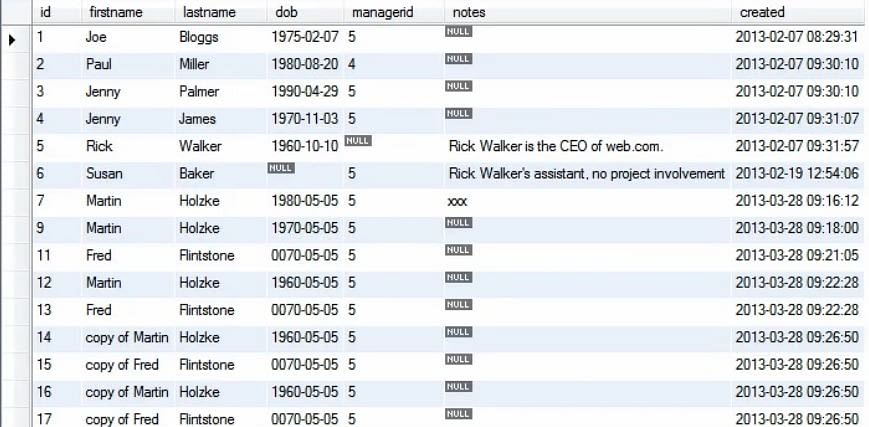
Są sytuacje, w których chcemy się pozbyć całego bloku. Na przykład, chcemy usunąć wszystkie wpisy kopii z tabeli osoby, jak pokazano na rysunku.
Kwerenda usuwająca wszystkie rekordy kopii z tabeli osoby jest przedstawiona poniżej:
select * from person
where firstname like 'kopia%’
delete from person
where firstname like 'kopia%’
W powyższym zapytaniu 'kopia%’ wskazuje na wypowiedzi rozpoczynające się od kopia i kontynuowane dowolnym słowem dalej.
Po wykonaniu powyższego zapytania widzimy, że wszystkie rekordy, które zaczęły się od 'Kopiuj’ zostały usunięte z tabeli osoby.
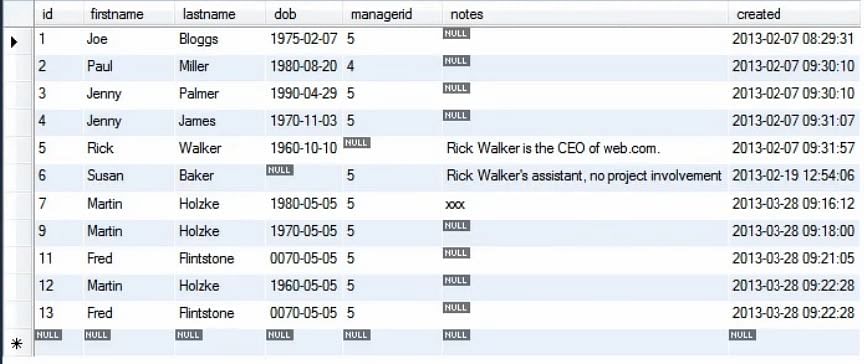
Uwaga: Zawsze zaleca się używanie instrukcji DELETE dla jednej tabeli na raz. Nie zaleca się używania tej instrukcji w przypadku wspólnych tabel.
Zakończenie
Tym samym, zakończyliśmy tę lekcję na temat „Manipulacji danymi w SQL.” Następna lekcja skupia się na Kontroli transakcji.
{{lectureCoursePreviewTitle}} View Transcript Watch Video
Aby dowiedzieć się więcej, skorzystaj z Kursu
SQL Szkolenie Certyfikacyjne
Go to Course
Aby dowiedzieć się więcej, skorzystaj z Kursu
Szkolenie Certyfikacyjne SQL Przejdź do Kursu
.