InterPro zawiera trzy główne encje: białka, sygnatury (określane również jako „metody” lub „modele”) i wpisy. Białka w UniProtKB są również centralnymi jednostkami białkowymi w InterPro. Informacje dotyczące tego, które sygnatury znacząco pasują do tych białek są obliczane w miarę uwalniania sekwencji przez UniProtKB i wyniki te są udostępniane publicznie (patrz poniżej). Dopasowania sygnatur do białek decydują o tym, jak sygnatury są integrowane razem we wpisach InterPro: porównawcze nakładanie się dopasowanych zestawów białek i lokalizacja dopasowań sygnatur na sekwencjach są używane jako wskaźniki pokrewieństwa. Tylko sygnatury uznane za wystarczającej jakości są włączane do InterPro. Od wersji 81.0 (wydanej 21 sierpnia 2020) wpisy InterPro anotowały 73,9% reszt znalezionych w UniProtKB z kolejnymi 9,2% anotowanymi przez sygnatury, które oczekują na integrację.

InterPro zawiera również dane dla wariantów splice oraz białek zawartych w bazach UniParc i UniMES.
Bazy danych członków konsorcjum InterProEdit
Spisy z InterPro pochodzą z 13 „baz danych członków”, które są wymienione poniżej.
CATH-Gene3D Opisuje rodziny białek i architektury domen w kompletnych genomach. Rodziny białek są tworzone przy użyciu algorytmu grupowania Markowa, po którym następuje grupowanie wielopowiązaniowe według identyczności sekwencji. Mapowanie przewidywanej struktury i sekwencji domen odbywa się przy użyciu bibliotek ukrytych modeli Markowa reprezentujących domeny CATH i Pfam. Funkcjonalna anotacja jest dostarczana do białek z wielu źródeł. Funkcjonalna predykcja i analiza architektury domen jest dostępna na stronie Gene3D. CDD Conserved Domain Database to zasób anotacji białek, który składa się z kolekcji adnotowanych modeli wielokrotnego dopasowania sekwencji dla starożytnych domen i białek o pełnej długości. Są one dostępne jako matryce PSSM (position-specific score matrices) do szybkiej identyfikacji konserwatywnych domen w sekwencjach białkowych poprzez RPS-BLAST. HAMAP to skrót od High-quality Automated and Manual Annotation of microbial Proteomes. Profile HAMAP są ręcznie tworzone przez ekspertów, którzy identyfikują białka należące do dobrze zachowanych rodzin lub podrodzin białek bakteryjnych, archetypowych i plastydowych (np. chloroplasty, cyjanelle, apikoplasty, plastyd niefotosyntetyzujący). MobiDB MobiDB jest bazą danych anotujących wewnętrzne zaburzenia w białkach. PANTHER PANTHER jest dużą kolekcją rodzin białek, które zostały podzielone na funkcjonalnie powiązane podrodziny, przy użyciu ludzkiej wiedzy. Te podrodziny modelują rozbieżność specyficznych funkcji w obrębie rodzin białek, pozwalając na dokładniejsze powiązanie z funkcją (stworzone przez człowieka klasyfikacje funkcji molekularnych i procesów biologicznych oraz diagramy ścieżek), jak również wnioskowanie o aminokwasach ważnych dla specyficzności funkcjonalnej. Ukryte modele Markowa (HMM) są budowane dla każdej rodziny i podrodziny w celu klasyfikacji dodatkowych sekwencji białkowych. Pfam jest dużym zbiorem wielokrotnych dopasowań sekwencji i ukrytych modeli Markowa obejmujących wiele typowych domen i rodzin białek.
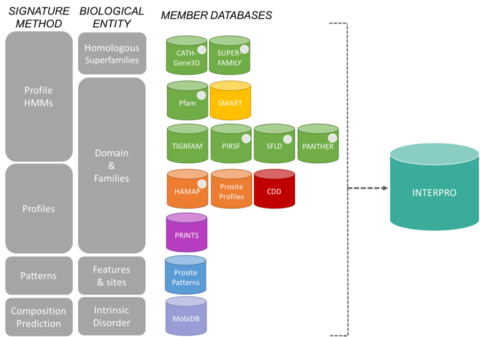
System klasyfikacji białek PIRSF to sieć o wielu poziomach zróżnicowania sekwencji od superrodzin do podrodzin, która odzwierciedla ewolucyjne powiązania białek pełnometrażowych i domen. Podstawową jednostką klasyfikacyjną PIRSF jest rodzina homeomorficzna, której członkowie są zarówno homologiczni (wyewoluowali od wspólnego przodka), jak i homeomorficzni (dzielą podobieństwo sekwencji na całej długości i wspólną architekturę domen). PRINTS PRINTS to kompendium białkowych odcisków palców. Odcisk palca to grupa konserwatywnych motywów służących do charakterystyki rodziny białek; jego moc diagnostyczna jest doskonalona poprzez iteracyjne skanowanie UniProt. Zazwyczaj motywy nie zachodzą na siebie, ale są rozdzielone wzdłuż sekwencji, choć mogą być przylegające w przestrzeni 3D. Odciski palców mogą kodować fałdy i funkcje białek w sposób bardziej elastyczny i skuteczny niż pojedyncze motywy, a ich pełna moc diagnostyczna wynika z wzajemnego kontekstu dostarczanego przez sąsiadów motywów. PROSITE PROSITE jest bazą danych rodzin i domen białkowych. Składa się z biologicznie znaczących miejsc, wzorców i profili, które pomagają w wiarygodnej identyfikacji, do której znanej rodziny białek (jeśli w ogóle) należy nowa sekwencja. SMART Simple Modular Architecture Research Tool Umożliwia identyfikację i anotację genetycznie mobilnych domen oraz analizę architektury domen. Wykryto ponad 800 rodzin domen występujących w białkach sygnałowych, zewnątrzkomórkowych i związanych z chromatyną. Domeny te są obszernie anotowane w odniesieniu do rozmieszczenia filamentów, klasy funkcjonalnej, struktur trzeciorzędowych i funkcjonalnie ważnych reszt. SUPERFAMILY SUPERFAMILY jest biblioteką profilowanych ukrytych modeli Markowa, które reprezentują wszystkie białka o znanej strukturze. Biblioteka oparta jest na klasyfikacji białek SCOP: każdy model odpowiada domenie SCOP i ma za zadanie reprezentować całą nadrodzinę SCOP, do której należy dana domena. SUPERFAMILY został wykorzystany do przeprowadzenia strukturalnego przypisania do wszystkich całkowicie zsekwencjonowanych genomów. SFLD Hierarchiczna klasyfikacja enzymów, która odnosi specyficzne cechy sekwencji-struktury do specyficznych zdolności chemicznych. TIGRFAMs TIGRFAMs jest kolekcją rodzin białek, zawierającą dopasowania sekwencji, ukryte modele Markowa (HMM) i adnotacje, która stanowi narzędzie do identyfikacji funkcjonalnie powiązanych białek w oparciu o homologię sekwencji. Te wpisy, które są „equivalogs” grupują homologiczne białka, które są konserwowane w odniesieniu do funkcji.
Typy danychEdit
InterPro składa się z siedmiu typów danych dostarczanych przez różnych członków konsorcjum:
| Data Type | Description | Contributing Databases |
|---|---|---|
| InterPro Entries | Structural. i/lub funkcjonalne domeny białek przewidywane przy użyciu jednej lub więcej sygnatur | Wszystkie 13 baz członkowskich |
| Sygnatury baz członkowskich | Sygnatury z baz członkowskich. Obejmują one sygnatury, które są zintegrowane z InterPro, i te, które nie są | Wszystkie 13 baz członkowskich |
| Sekwencje białkowe | Sekwencje białkowe | UniProtKB (Swiss-Prot i TrEMBL) |
| Proteome | Zbiór białek należących do jednego organizmu | UniProtKB |
| Struktury | 3-.struktury wymiarowe białek | PDBe |
| Taksonomia | Informacje taksonomiczne o białkach | UniProtKB |
| Zestawy | Grupy rodzin powiązanych ewolucyjnie | Pfam, CDD |

Typy wpisów InterProEdit
Wpisy InterPro mogą być dalej podzielone na pięć typów:
- Homologous Superfamily: Grupa białek, które mają wspólne pochodzenie ewolucyjne, widoczne w ich podobieństwach strukturalnych, nawet jeśli ich sekwencje nie są bardzo podobne. Wpisy te są w szczególności dostarczane tylko przez dwie członkowskie bazy danych: CATH-Gene3D i SUPERFAMILY.
- Rodzina: Grupa białek, które mają wspólne pochodzenie ewolucyjne określone przez podobieństwa strukturalne, pokrewne funkcje lub homologię sekwencji.
- Domena: Odrębna jednostka w białku o określonej funkcji, strukturze lub sekwencji.
- Powtórzenie: Sekwencja aminokwasów, zwykle nie dłuższa niż 50 aminokwasów, która ma tendencję do wielokrotnego powtarzania się w białku.
- Miejsce: Krótka sekwencja aminokwasów, w której co najmniej jeden aminokwas jest konserwowany. Obejmują one miejsca modyfikacji po translacji, miejsca konserwowane, miejsca wiązania i miejsca aktywne.
.