Aby dać odpowiednie wprowadzenie do jądra Gaussa, w tym tygodniu post zaczniemy nieco bardziej abstrakcyjnie niż zwykle. Ten poziom abstrakcji nie jest ściśle konieczny do zrozumienia jak działają jądra Gaussa, ale abstrakcyjna perspektywa może być niezwykle użyteczna jako źródło intuicji przy próbie zrozumienia rozkładów prawdopodobieństwa w ogóle. A więc sprawa wygląda tak: postaram się powoli budować abstrakcję, ale jeśli kiedykolwiek będziesz beznadziejnie zagubiony, lub po prostu nie będziesz mógł tego dłużej znieść, możesz przeskoczyć w dół do nagłówka, który mówi „Część praktyczna” pogrubioną czcionką – tam przejdę do bardziej konkretnego opisu algorytmu jądra Gaussa. Ponadto, jeśli nadal masz problemy, nie przejmuj się zbytnio – większość późniejszych postów na tym blogu nie będzie wymagać od ciebie zrozumienia jąder Gaussa, więc możesz po prostu poczekać na post w przyszłym tygodniu (lub przeskoczyć do niego, jeśli czytasz to później).
Przypomnij sobie, że jądro jest sposobem umieszczenia przestrzeni danych w przestrzeni wektorowej o wyższym wymiarze, tak aby przecięcia przestrzeni danych z hiperpłaszczyznami w przestrzeni o wyższym wymiarze określały bardziej skomplikowane, zakrzywione granice decyzji w przestrzeni danych. Głównym przykładem, któremu się przyjrzeliśmy, było jądro, które wysyła dwuwymiarową przestrzeń danych do przestrzeni pięciowymiarowej, wysyłając każdy punkt o współrzędnych 


W tym tygodniu wyjdziemy poza przestrzenie wektorowe o wyższych wymiarach do nieskończenie wymiarowych przestrzeni wektorowych. Możesz zobaczyć jak dziewięciowymiarowe jądro powyżej jest rozszerzeniem jądra pięciowymiarowego – w zasadzie dodaliśmy tylko cztery dodatkowe wymiary na końcu. Jeśli będziemy w ten sposób dodawać kolejne wymiary, otrzymamy coraz bardziej wymiarowe jądra. Gdybyśmy mieli robić to „w nieskończoność”, skończylibyśmy z nieskończenie wieloma wymiarami. Zauważ, że możemy to zrobić tylko w abstrakcji. Komputery mogą zajmować się tylko skończonymi rzeczami, więc nie mogą przechowywać i przetwarzać obliczeń w nieskończenie wymiarowych przestrzeniach wektorowych. Ale przez chwilę będziemy udawać, że możemy, tylko po to, by zobaczyć, co się stanie. Następnie przełożymy rzeczy z powrotem do świata skończonego.
W tej hipotetycznej nieskończenie wymiarowej przestrzeni wektorowej, możemy dodawać wektory w ten sam sposób, w jaki robimy to ze zwykłymi wektorami, po prostu dodając odpowiednie współrzędne. Jednak w tym przypadku musimy dodawać nieskończenie wiele współrzędnych. Podobnie, możemy mnożyć przez skalary, mnożąc każdą z (nieskończenie wielu) współrzędnych przez daną liczbę. Zdefiniujemy nieskończone jądro wielomianu, wysyłając każdy punkt 

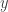


Aby wrócić do świata obliczeniowego, możemy odzyskać nasze oryginalne pięciowymiarowe jądro po prostu zapominając wszystkie oprócz pierwszych pięciu wpisów. W rzeczywistości, oryginalna przestrzeń pięciowymiarowa jest zawarta w tej nieskończonej przestrzeni wymiarowej. (Oryginalne pięciowymiarowe jądro jest tym, co otrzymujemy rzutując nieskończone wielomianowe jądro na tę pięciowymiarową przestrzeń.)
Teraz weź głęboki oddech, ponieważ zamierzamy pójść o krok dalej. Zastanów się, przez chwilę, czym jest wektor. Jeśli kiedykolwiek brałeś udział w zajęciach z algebry liniowej, możesz pamiętać, że wektory są oficjalnie zdefiniowane w kategoriach ich właściwości dodawania i mnożenia. Ale zamierzam to chwilowo zignorować (z przeprosinami dla wszystkich matematyków, którzy to czytają). W świecie komputerów, zazwyczaj myślimy o wektorze jako o liście liczb. Jeśli przeczytałeś do tej pory, możesz być skłonny pozwolić, by ta lista była nieskończona. Ale chcę, żebyś myślał o wektorze jako o zbiorze liczb, w którym każda liczba jest przypisana do konkretnej rzeczy. Na przykład, każda liczba w naszym zwykłym typie wektora jest przypisana do jednej ze współrzędnych/cech. W jednym z naszych nieskończonych wektorów, każda liczba jest przypisana do miejsca na naszej nieskończenie długiej liście.
Ale co powiesz na to: Co by się stało, gdybyśmy zdefiniowali wektor, przypisując liczbę do każdego punktu w naszej (skończonej wymiarowo) przestrzeni danych? Taki wektor nie wybiera pojedynczego punktu w przestrzeni danych; raczej, po wybraniu tego wektora, jeśli wskażesz na dowolny punkt w przestrzeni danych, wektor powie ci liczbę. Cóż, właściwie mamy już na to nazwę: Coś, co przypisuje numer do każdego punktu w przestrzeni danych, jest funkcją. W rzeczywistości na tym blogu często przyglądaliśmy się funkcjom, w postaci funkcji gęstości, które definiują rozkłady prawdopodobieństwa. Ale chodzi o to, że możemy myśleć o tych funkcjach gęstości jako o wektorach w nieskończenie wymiarowej przestrzeni wektorowej.
Jak funkcja może być wektorem? Cóż, możemy dodać dwie funkcje, po prostu dodając ich wartości w każdym punkcie. To był pierwszy schemat, który omawialiśmy przy łączeniu rozkładów w zeszłotygodniowym poście o modelach mieszanych. Funkcje gęstości dla dwóch wektorów (plam gaussowskich) oraz wynik ich dodania pokazane są na poniższym rysunku. W podobny sposób możemy pomnożyć funkcję przez liczbę, co spowoduje, że ogólna gęstość stanie się jaśniejsza lub ciemniejsza. W rzeczywistości są to operacje, z którymi prawdopodobnie miałeś już wiele do czynienia na lekcjach algebry i rachunku. Więc nie robimy jeszcze nic nowego, po prostu myślimy o rzeczach w inny sposób.

Kolejnym krokiem jest zdefiniowanie jądra z naszej oryginalnej przestrzeni danych do tej przestrzeni infintie wymiarowej, i tutaj mamy wiele wyborów. Jednym z najczęstszych wyborów jest funkcja blob Gaussian, którą widzieliśmy już kilka razy w poprzednich postach. Dla tego jądra, wybierzemy standardowy rozmiar dla blobów gaussowskich, tj. stałą wartość odchylenia 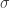
Teraz pojawia się problem: Aby przywrócić rzeczy do świata obliczeniowego, musimy wybrać skończony wymiar przestrzeni wektorowej siedzącej w tej nieskończonej przestrzeni wektorowej i „rzutować” nieskończoną przestrzeń wymiarową na skończoną podprzestrzeń wymiarową. Wybierzemy skończoną przestrzeń wymiarową, wybierając (skończoną) liczbę punktów w przestrzeni danych, a następnie biorąc przestrzeń wektorową rozpiętą przez plamy gaussowskie skupione w tych punktach. Jest to odpowiednik wektorowego tempa zdefiniowanego przez pierwsze pięć współrzędnych nieskończonego wielomianowego jądra, jak powyżej. Wybór tych punktów jest ważny, ale wrócimy do tego później. Na razie pytanie brzmi: jak rzutujemy?
W przypadku wektorów o skończonych wymiarach najczęstszym sposobem definiowania rzutu jest użycie iloczynu kropkowego: Jest to liczba, którą otrzymujemy poprzez pomnożenie odpowiadających sobie współrzędnych dwóch wektorów, a następnie dodanie ich wszystkich razem. Tak więc, na przykład iloczyn kropkowy trójwymiarowych wektorów 


Moglibyśmy zrobić coś podobnego z funkcjami, mnożąc wartości, które przyjmują na odpowiadających im punktach w zbiorze danych. (Innymi słowy, mnożymy dwie funkcje razem.) Ale nie możemy wtedy dodać wszystkich tych liczb razem, ponieważ jest ich nieskończenie wiele. Zamiast tego wykonamy całkę! (Zauważ, że jestem glossing nad tonę szczegółów tutaj, i ponownie przepraszam do wszystkich matematyków, którzy czytają to). Miłą rzeczą jest to, że jeśli pomnożymy dwie funkcje gaussowskie i zintegrujemy, liczba jest równa gaussowskiej funkcji odległości między punktami centralnymi. (Chociaż nowa funkcja gaussowska będzie miała inną wartość odchylenia.)
Innymi słowy, jądro gaussowskie przekształca produkt kropkowy w nieskończonej przestrzeni wymiarowej w gaussowską funkcję odległości między punktami w przestrzeni danych: Jeśli dwa punkty w przestrzeni danych są w pobliżu, wtedy kąt między wektorami, które reprezentują je w przestrzeni jądra będzie mały. Jeśli punkty są daleko od siebie to odpowiadające im wektory będą bliskie „prostopadłym”.
Część praktyczna
Więc, przejrzyjmy to co mamy do tej pory: Aby zdefiniować 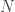
Aby lepiej zrozumieć, jak działa to jądro, dowiedzmy się, jak wygląda przecięcie hiperpłaszczyzny z przestrzenią danych. (To jest to, co robi się z jądrami przez większość czasu, w każdym razie.) Przypomnijmy, że płaszczyzna jest zdefiniowana przez równanie postaci 


To wciąż jest dość trudne do rozpakowania, więc spójrzmy na przykład, w którym każda z wartości 

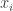





Jeśli dostosujemy parametry
Tak więc, daje nam to większą elastyczność przy wyborze granicy decyzji (lub przynajmniej inny rodzaj elastyczności), ale ostateczny wynik będzie bardzo zależny od
Znalezienie takiego zbioru punktów jest zupełnie innym problemem niż to, na czym skupialiśmy się w dotychczasowych postach na tym blogu, i należy do kategorii uczenia nienadzorowanego/analityki opisowej. (W kontekście kerneli, można również myśleć o selekcji/inżynierii cech). W następnych kilku postach, zmienimy bieg i zaczniemy badać pomysły wzdłuż tych linii.