InterPro bevat drie hoofdentiteiten: eiwitten, handtekeningen (ook wel “methoden” of “modellen” genoemd) en vermeldingen. De eiwitten in UniProtKB zijn ook de centrale eiwitentiteiten in InterPro. Informatie over welke handtekeningen significant overeenkomen met deze eiwitten wordt berekend wanneer de sequenties door UniProtKB worden vrijgegeven en deze resultaten worden aan het publiek beschikbaar gesteld (zie hieronder). De overeenkomsten van handtekeningen met eiwitten bepalen hoe de handtekeningen worden geïntegreerd in InterPro-ingangen: vergelijkende overlap van gematchte eiwitreeksen en de plaats van de overeenkomsten van de handtekeningen op de sequenties worden gebruikt als indicatoren van verwantschap. Alleen handtekeningen die van voldoende kwaliteit worden geacht, worden in InterPro geïntegreerd. Met ingang van versie 81.0 (uitgebracht op 21 augustus 2020) annoteerden InterPro-ingangen 73,9% van de in UniProtKB gevonden residuen, met nog eens 9,2% geannoteerd door handtekeningen die nog moeten worden geïntegreerd.

InterPro bevat ook gegevens voor splice-varianten en de eiwitten die zijn opgenomen in de UniParc- en UniMES-databases.
Databases die lid zijn van het InterPro-consortiumEdit
De handtekeningen van InterPro zijn afkomstig van 13 “lid-databases”, die hieronder worden vermeld.
CATH-Gene3D Beschrijft eiwitfamilies en domeinarchitecturen in complete genomen. Eiwitfamilies worden gevormd met behulp van een Markov-clusteringalgoritme, gevolgd door multi-linkage clustering op basis van sequentie-identiteit. Het in kaart brengen van voorspelde structuur- en sequentiedomeinen gebeurt met behulp van verborgen Markov modelbibliotheken die CATH- en Pfam-domeinen vertegenwoordigen. Functionele annotatie wordt verstrekt aan eiwitten uit meerdere bronnen. Functionele voorspelling en analyse van domeinarchitecturen is beschikbaar op de Gene3D website. CDD Conserved Domain Database is een bron voor eiwitannotatie die bestaat uit een verzameling van geannoteerde meervoudige sequentie-uitlijningsmodellen voor oude domeinen en proteïnen van de volledige lengte. Deze zijn beschikbaar als positie-specifieke score matrices (PSSMs) voor snelle identificatie van geconserveerde domeinen in eiwitsequenties via RPS-BLAST. HAMAP staat voor High-quality Automated and Manual Annotation of microbial Proteomes. HAMAP-profielen worden manueel samengesteld door deskundige curatoren en identificeren eiwitten die deel uitmaken van goed geconserveerde bacteriële, archaeale en plastid-gecodeerde (d.w.z. chloroplasten, cyanellen, apicoplasten, niet-fotosynthetische plastiden) eiwitfamilies of -subfamilies. MobiDB MobiDB is een databank die intrinsieke stoornissen in eiwitten annoteert. PANTHER PANTHER is een grote verzameling van eiwitfamilies die met menselijke expertise zijn onderverdeeld in functioneel verwante subfamilies. Deze subfamilies modelleren de divergentie van specifieke functies binnen eiwitfamilies, waardoor een nauwkeuriger associatie met functie mogelijk wordt (door mensen gecurateerde moleculaire functie- en biologische procesclassificaties en pathway-diagrammen), alsmede de gevolgtrekking van aminozuren die belangrijk zijn voor functionele specificiteit. Voor elke familie en subfamilie worden verborgen Markov modellen (HMM’s) gebouwd voor het classificeren van aanvullende eiwitsequenties. Pfam is een grote verzameling van meervoudige sequentie-uitlijningen en verborgen Markov-modellen voor veel voorkomende eiwitdomeinen en -families.
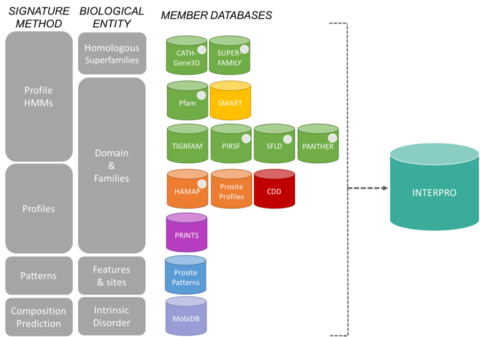
Het PIRSF-indelingssysteem voor proteïnen is een netwerk met meerdere niveaus van sequentiediversiteit, van superfamilies tot subfamilies, dat de evolutionaire relatie van proteïnen op volledige lengte en domeinen weerspiegelt. De primaire PIRSF classificatie eenheid is de homeomorfe familie, waarvan de leden zowel homoloog (geëvolueerd van een gemeenschappelijke voorouder) als homeomorf (het delen van full-length sequentie gelijkenis en een gemeenschappelijke domein architectuur) zijn. PRINTS PRINTS is een compendium van eiwit-fingerprints. Een vingerafdruk is een groep van geconserveerde motieven die worden gebruikt om een eiwitfamilie te karakteriseren; het diagnostische vermogen ervan wordt verfijnd door iteratief scannen van UniProt. Gewoonlijk overlappen de motieven elkaar niet, maar zijn zij langs een sequentie gescheiden, hoewel zij in 3D-ruimte aaneengesloten kunnen zijn. Vingerafdrukken kunnen eiwitplooien en functionaliteiten flexibeler en krachtiger coderen dan afzonderlijke motieven, waarbij hun volledige diagnostische kracht voortkomt uit de wederzijdse context die door motiefburen wordt geboden. PROSITE PROSITE is een database van eiwitfamilies en -domeinen. Zij bestaat uit biologisch significante sites, patronen en profielen die helpen om op betrouwbare wijze vast te stellen tot welke bekende eiwitfamilie (indien aanwezig) een nieuwe sequentie behoort. SMART Simple Modular Architecture Research Tool Maakt de identificatie en annotatie van genetisch mobiele domeinen en de analyse van domeinarchitecturen mogelijk. Meer dan 800 domeinfamilies die voorkomen in signalerings-, extracellulaire en chromatine-geassocieerde proteïnen zijn detecteerbaar. Deze domeinen worden uitvoerig geannoteerd met betrekking tot fyletische distributies, functionele klasse, tertiaire structuren en functioneel belangrijke residuen. SUPERFAMILY SUPERFAMILY is een bibliotheek van profiel verborgen Markov modellen die alle eiwitten van bekende structuur vertegenwoordigen. De bibliotheek is gebaseerd op de SCOP classificatie van eiwitten: elk model komt overeen met een SCOP domein en heeft tot doel de volledige SCOP superfamilie waartoe het domein behoort voor te stellen. SUPERFAMILY is gebruikt om structurele toewijzingen uit te voeren aan alle volledig gesequencete genomen. SFLD Een hiërarchische classificatie van enzymen die specifieke sequentie-structuurkenmerken relateert aan specifieke chemische capaciteiten. TIGRFAMs TIGRFAMs is een verzameling van eiwitfamilies, met gecureerde meervoudige sequentie-uitlijningen, verborgen Markov-modellen (HMM’s) en annotatie, die een hulpmiddel biedt voor het identificeren van functioneel verwante eiwitten op basis van sequentiehomologie. De vermeldingen die “equivalogs” zijn groeperen homologe eiwitten die geconserveerd zijn met betrekking tot functie.
Gegevens typesEdit
InterPro bestaat uit zeven soorten gegevens die door verschillende leden van het consortium worden verstrekt:
| Gegevens type | Beschrijving | Betalende Databases |
|---|---|---|
| InterPro Entries | Structurele en/of functionele domeinen van eiwitten die zijn voorspeld met een of meer handtekeningen | Alle 13 lid-databanken |
| Handtekeningen van lid-databanken | Handtekeningen van lid-databanken. Deze omvatten handtekeningen die zijn geïntegreerd in InterPro, en die welke dat niet zijn | Alle 13 lid-databases |
| Proteïne | Proteïne-sequenties | UniProtKB (Swiss-Prot en TrEMBL) |
| Proteoom | Verzameling eiwitten die tot één organisme behoren | UniProtKB |
| Structuur | 3-dimensionale structuren van eiwitten | PDBe |
| Taxonomie | Proteïne taxonomische informatie | UniProtKB |
| Set | Groepen van evolutionair verwante families | Pfam, CDD |

InterPro-ingangstypenEdit
InterPro-ingangen kunnen verder worden onderverdeeld in vijf typen:
- Homologe superfamilie: Een groep eiwitten die een gemeenschappelijke evolutionaire oorsprong hebben, zoals blijkt uit hun structurele overeenkomsten, zelfs als hun sequenties niet sterk op elkaar lijken. Deze gegevens worden specifiek slechts door twee aangesloten databanken verstrekt: CATH-Gene3D en SUPERFAMILY.
- Family: Een groep eiwitten die een gemeenschappelijke evolutionaire oorsprong hebben, bepaald door structurele overeenkomsten, verwante functies, of sequentiehomologie.
- Domein: Een afzonderlijke eenheid in een eiwit met een bepaalde functie, structuur, of sequentie.
- Herhaling: Een reeks aminozuren, meestal niet langer dan 50 aminozuren, die de neiging hebben om vele malen te herhalen in een eiwit.
- Site: Een korte sequentie van aminozuren waar ten minste één aminozuur geconserveerd is. Deze omvatten post-translation modificatie sites, geconserveerde sites, bindingsplaatsen, en actieve sites.