Om een goede introductie tot Gaussian kernels te geven, begint de post van deze week een beetje abstracter dan gewoonlijk. Dit abstractieniveau is niet strikt noodzakelijk om te begrijpen hoe Gaussiaanse kernels werken, maar het abstracte perspectief kan zeer nuttig zijn als bron van intuïtie bij het proberen te begrijpen van kansverdelingen in het algemeen. Dus het zit zo: ik zal proberen de abstractie langzaam op te bouwen, maar als u ooit hopeloos verdwaalt, of het gewoon niet meer aankunt, dan kunt u naar beneden springen naar het kopje dat vetgedrukt “Het praktische deel” zegt – Daar ga ik over op een meer concrete beschrijving van het Gaussiaanse kernel algoritme. En als je nog steeds problemen hebt, maak je dan niet te veel zorgen – Voor de meeste latere berichten op deze blog is het niet nodig dat je Gaussiaanse kernels begrijpt, dus je kunt gewoon wachten op het bericht van volgende week (of ernaartoe gaan als je dit later leest).
Bedenk dat een kernel een manier is om een gegevensruimte in een hoger dimensionale vectorruimte te plaatsen, zodat de snijpunten van de gegevensruimte met hypervlakken in de hoger dimensionale ruimte meer ingewikkelde, gebogen beslissingsgrenzen in de gegevensruimte bepalen. Het belangrijkste voorbeeld dat we hebben bekeken was de kernel die een tweedimensionale gegevensruimte naar een vijfdimensionale ruimte stuurt door elk punt met coördinaten 


Deze week gaan we verder dan hoger dimensionale vectorruimten naar oneindig-dimensionale vectorruimten. U ziet dat de negen-dimensionale kern hierboven een uitbreiding is van de vijf-dimensionale kern – we hebben er in feite vier dimensies aan het eind aan toegevoegd. Als we op deze manier steeds meer dimensies toevoegen, krijgen we steeds hoger dimensionale kernels. Als we dit “eeuwig” zouden blijven doen, zouden we oneindig veel dimensies krijgen. Merk op dat we dit alleen in het abstracte kunnen doen. Computers kunnen alleen eindige dingen verwerken, dus ze kunnen geen berekeningen opslaan en verwerken in vectorruimten van oneindige dimensies. Maar we doen even alsof we dat wel kunnen, gewoon om te zien wat er gebeurt. Dan vertalen we de dingen terug naar de eindige wereld.
In deze hypothetische oneindig-dimensionale vectorruimte kunnen we vectoren op dezelfde manier optellen als we dat met gewone vectoren doen, door gewoon overeenkomstige coördinaten op te tellen. In dit geval moeten we echter oneindig veel coördinaten optellen. Op dezelfde manier kunnen we vermenigvuldigen met scalars, door elk van de (oneindig vele) coördinaten te vermenigvuldigen met een bepaald getal. We definiëren de oneindige polynoomkern door elk punt 

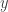


Om terug te keren naar de rekenwereld, kunnen we onze oorspronkelijke vijf-dimensionale kernel terugvinden door gewoon alle ingangen te vergeten, behalve de eerste vijf. In feite is de oorspronkelijke vijfdimensionale ruimte vervat in deze oneindig dimensionale ruimte. (De oorspronkelijke vijfdimensionale kern is wat we krijgen door de oneindige polynoomkern in deze vijfdimensionale ruimte te projecteren.)
Nu diep ademhalen, want we gaan nog een stapje verder. Overweeg, voor een moment, wat een vector is. Als u ooit een wiskundeles lineaire algebra hebt gevolgd, herinnert u zich misschien dat vectoren officieel worden gedefinieerd in termen van hun optel- en vermenigvuldigingseigenschappen. Maar ik ga dat tijdelijk negeren (met excuses aan alle wiskundigen die dit lezen). In de computerwereld denken we gewoonlijk aan een vector als een lijst van getallen. Als je tot hier gelezen hebt, ben je misschien bereid die lijst oneindig te laten zijn. Maar ik wil dat je denkt aan een vector als aan een verzameling getallen waarbij elk getal is toegewezen aan een bepaald ding. Bijvoorbeeld, elk getal in ons gebruikelijke type vector is toegewezen aan een van de coördinaten/kenmerken. In een van onze oneindige vectoren wordt elk getal toegewezen aan een plaats in onze oneindig lange lijst.
Maar hoe zit dit: Wat zou er gebeuren als we een vector definieerden door een getal toe te kennen aan elk punt in onze (eindig dimensionale) dataruimte? Zo’n vector kiest niet één enkel punt in de dataruimte uit; integendeel, als je eenmaal deze vector hebt uitgekozen, en je wijst naar een willekeurig punt in de dataruimte, dan vertelt de vector je een getal. Nou, eigenlijk hebben we daar al een naam voor: Iets dat een nummer toekent aan elk punt in de dataruimte is een functie. In feite hebben we op deze blog al vaak naar functies gekeken, in de vorm van dichtheidsfuncties die waarschijnlijkheidsverdelingen definiëren. Maar het punt is dat we deze dichtheidsfuncties kunnen zien als vectoren in een oneindig-dimensionale vectorruimte.
Hoe kan een functie een vector zijn? Wel, we kunnen twee functies optellen door gewoon hun waarden in elk punt op te tellen. Dit was het eerste schema dat we bespraken voor het combineren van verdelingen in de post van vorige week over mengmodellen. De dichtheidsfuncties voor twee vectoren (Gaussische klodders) en het resultaat van het optellen ervan zijn te zien in de onderstaande figuur. Op soortgelijke wijze kunnen we een functie met een getal vermenigvuldigen, waardoor de totale dichtheid lichter of donkerder wordt. In feite zijn dit beide bewerkingen waar je waarschijnlijk al veel ervaring mee hebt in algebra en calculus. We doen dus niets nieuws, we denken alleen op een andere manier over de dingen na.

De volgende stap is het definiëren van een kernel van onze oorspronkelijke gegevensruimte naar deze oneindig dimensionale ruimte, en hier hebben we een heleboel keuzemogelijkheden. Een van de meest gebruikelijke is de Gaussische blobfunctie, die we in eerdere berichten al een paar keer hebben gezien. Voor deze kernel kiezen we een standaardgrootte voor de Gaussische blobs, d.w.z. een vaste waarde voor de afwijking 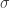
Nu komt het probleem: om de zaken terug te brengen naar de computationele wereld, moeten we een eindig dimensionale vectorruimte kiezen die in deze oneindig dimensionale vectorruimte zit en de oneindig dimensionale ruimte “projecteren” in de eindig dimensionale deelruimte. We kiezen een eindig dimensionale ruimte door een (eindig) aantal punten in de dataruimte te kiezen, en dan de vectorruimte te nemen die wordt opgespannen door de Gaussische blobs met het middelpunt in die punten. Dit is het equivalent van het vectortempo gedefinieerd door de eerste vijf coördinaten van de oneindige polynoomkern, zoals hierboven. De keuze van deze punten is belangrijk, maar daar komen we later op terug. Voor nu is de vraag: hoe projecteren we?
Voor eindig-dimensionale vectoren is de meest gebruikelijke manier om een projectie te definiëren, het gebruik van het dot-product: Dit is het getal dat we krijgen door de coördinaten van twee vectoren te vermenigvuldigen en bij elkaar op te tellen. Dus, bijvoorbeeld, het scalair product van de driedimensionale vectoren 


We kunnen iets soortgelijks doen met functies, door de waarden te vermenigvuldigen die ze aannemen op overeenkomstige punten in de gegevensverzameling. (Met andere woorden, we vermenigvuldigen de twee functies met elkaar.) Maar we kunnen dan niet al deze getallen bij elkaar optellen, omdat er oneindig veel van zijn. In plaats daarvan nemen we een integraal! (Merk op dat ik hier heel wat details over het hoofd zie, en ik verontschuldig me bij deze voor alle wiskundigen die dit lezen). Het mooie hier is dat als we twee Gaussische functies vermenigvuldigen en integreren, het getal gelijk is aan een Gaussische functie van de afstand tussen de middelpunten. (Hoewel de nieuwe Gaussische functie een andere afwijkingswaarde zal hebben.)
Met andere woorden, de Gaussische kernel transformeert het dot-product in de oneindig dimensionale ruimte in de Gaussische functie van de afstand tussen de punten in de dataruimte: Als twee punten in de dataruimte dicht bij elkaar liggen, zal de hoek tussen de vectoren die hen in de kernelruimte voorstellen klein zijn. Als de punten ver uit elkaar liggen, zullen de overeenkomstige vectoren dicht bij “loodrecht” liggen.
Het praktische gedeelte
Dus, laten we eens bekijken wat we tot nu toe hebben: Om een 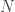
Om beter te begrijpen hoe deze kernel werkt, laten we eens nagaan hoe de doorsnijding van een hypervlak met de dataruimte eruit ziet. (Dit is trouwens wat men meestal doet met kernels.) Herinner u dat een vlak gedefinieerd wordt door een vergelijking van de vorm 


Dat is nog vrij moeilijk uit te pakken, dus laten we eens kijken naar een voorbeeld waarin elk van de waarden 

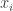





Als we de parameters
Dus, dit geeft ons meer flexibiliteit bij het kiezen van de beslissingsgrens (of, tenminste, een ander soort flexibiliteit) maar het eindresultaat zal zeer afhankelijk zijn van de
Het vinden van zo’n verzameling punten is een heel ander probleem dan waar we ons tot nu toe op hebben gericht in de berichten op deze blog, en valt onder de categorie van unsupervised learning/descriptive analytics. (In de context van kernels kan het ook worden gezien als feature selectie/engineering). In de volgende paar berichten zullen we van versnelling veranderen en ideeën in die richting beginnen te verkennen.