InterPro には、タンパク質、シグネチャー(「メソッド」または「モデル」とも呼ばれる)、エントリーの3つの主要なエンティティが含まれています。 UniProtKBのタンパク質は、InterProの中心的なタンパク質実体でもあります。 UniProtKBでは、配列の公開に伴い、どのシグネチャーがこれらのタンパク質と有意にマッチするかという情報が計算され、その結果が一般に公開されています(下記参照)。 シグネチャとタンパク質のマッチングは、シグネチャをどのようにInterProエントリに統合するかを決定するものです。マッチしたタンパク質セットの重複度の比較と、配列上のシグネチャのマッチングの位置が関連性の指標として使用されています。 十分な品質があると判断されたシグネチャーのみがInterProに統合されます。 8867>

InterProはスプライスバリアント、UniParcおよびUniMESデータベースに含まれるタンパク質のデータも含んでいる。
InterProコンソーシアムのメンバーデータベース 編集
InterProからのサインは、以下に示す13の「メンバーデータベース」からのもの。 タンパク質ファミリーはMarkovクラスタリングアルゴリズムにより形成され、その後配列の同一性によりmulti-linkageクラスタリングが行われる。 予測された構造と配列ドメインのマッピングは、CATHとPfamドメインを表す隠れマルコフモデルライブラリを用いて行われる。 機能アノテーションは、複数のリソースからタンパク質に提供される。 機能予測やドメイン構造の解析はGene3Dウェブサイトから行うことができる。 CDD Conserved Domain Databaseは、古代のドメインおよび全長タンパク質の注釈付き多重配列アラインメントモデルのコレクションからなるタンパク質注釈リソースです。 RPS-BLASTによるタンパク質配列中の保存ドメインを高速に同定するための位置特異的スコア行列(PSSM)として公開されている。 HAMAPとは、High-quality Automated and Manual Annotation of microbial Proteomesの略で、微生物プロテオームの自動的かつ手動的なアノテーションを意味する。 HAMAPプロファイルは、専門キュレーターが手作業で作成し、保存状態の良いバクテリア、古細菌、プラスティド(葉緑体、シアネル、アピコプラスト、非光合成プラスティド)タンパク質ファミリーまたはサブファミリーの一部を構成するタンパク質を同定している。 タンパク質に内在する無秩序をアノテーションしたデータベース。 PANTHER PANTHERは、タンパク質ファミリーを機能的に関連するサブファミリーに細分化し、人間の専門知識を用いて収集した大規模なデータベースです。 これらのサブファミリは、タンパク質ファミリー内の特定の機能の分岐をモデル化しており、より正確な機能との関連付け(人間がキュレーションした分子機能および生物学的プロセスの分類とパスウェイ図)、機能特異性に重要なアミノ酸の推定が可能である。 隠れマルコフモデル(HMM)をファミリーおよびサブファミリーごとに構築し、さらにタンパク質配列を分類している。 Pfamは、多くの一般的なタンパク質ドメインとファミリーをカバーする、多重配列アラインメントと隠れマルコフモデルの大規模なコレクションである。
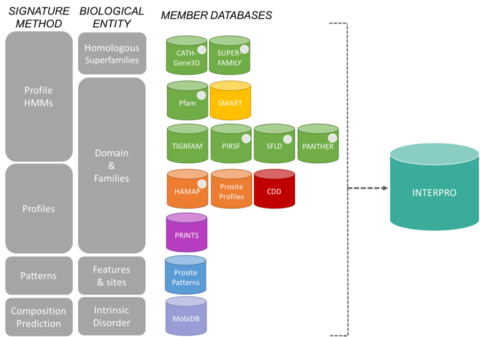
PIRSF タンパク質分類システムは、全長タンパク質とドメインの進化的関係を反映した、スーパーファミリーからサブファミリーまでの複数レベルの配列多様性を持つネットワークである。 PIRSFの主要な分類単位は同型ファミリーで、そのメンバーは相同性(共通の祖先から進化した)と同型性(全長配列の類似性と共通のドメイン構造を持つ)の両方を持っている。 PRINTS PRINTSはタンパク質フィンガープリントの大要である。 フィンガープリントはタンパク質ファミリーを特徴付けるために使われる保存されたモチーフのグループであり、その診断力はUniProtの反復スキャンにより改良されている。 通常、モチーフは重ならず、配列に沿って分離しているが、3次元空間では連続していることもある。 フィンガープリントは、単一のモチーフよりも柔軟かつ強力にタンパク質の折り畳みと機能性をコード化することができ、その診断能力はモチーフの近傍によって与えられる相互文脈に由来している。 タンパク質ファミリーおよびドメインを収集したデータベース。 また、このデータベースは、生物学的に重要な部位、パターン、プロファイルから構成されており、新しい配列が既知のタンパク質ファミリーに属するかどうかを確実に同定するのに役立つ。 遺伝子発現を測定し、その結果をデータベース化したデータベース。 シグナル伝達、細胞外、クロマチン関連タンパク質に見られる800以上のドメインファミリーを検出することができる。 これらのドメインは、植物学的分布、機能クラス、3次構造、機能的に重要な残基に関して広範にアノテーションされている。 SUPERFAMILY SUPERFAMILYは、構造が既知の全てのタンパク質を表現するプロファイル隠れマルコフモデルのライブラリである。 このライブラリは、タンパク質のSCOP分類に基づいています。各モデルはSCOPドメインに対応し、そのドメインが属するSCOPスーパーファミリー全体を表現することを目的としています。 SUPERFAMILYは、完全に配列決定されたすべてのゲノムの構造解析を行うために使用されている。 SFLD 酵素の階層的な分類で、特定の配列-構造の特徴と特定の化学的能力を関連付ける。 TIGRFAMs TIGRFAMsは、タンパク質ファミリーのコレクションで、複数の配列アラインメント、隠れマルコフモデル(HMM)、アノテーションを精選し、配列相同性に基づき機能的に関連するタンパク質を特定するためのツールを提供している。 配列の相同性から機能的に関連するタンパク質を同定するツール。
Data typesEdit
InterPro は、コンソーシアムの異なるメンバーから提供される7種類のデータで構成されている。
| Data Type | Description | Contributing Databases | ||
|---|---|---|---|---|
| InterPro Entries | Structural 1つ以上のシグネチャを用いて予測されたタンパク質のドメインおよび/または機能ドメイン | All 13 member databases | ||
| Member Database signatures | Signatures from member databases.All 13 member databases | Member Database signatures | Signatures from member databases. InterProに統合されているシグネチャも含まれます。 412> | 13のメンバーデータベースすべて |
| タンパク質 | タンパク質配列 | UniProtKB (Swiss-)ProtおよびTrEMBL) | ||
| プロテオーム | 単一の生物に属するタンパク質のコレクション | UniProtKB | ||
| 構造 | 3-… 続きを読むタンパク質の立体構造 | PDBe | ||
| 分類情報 | UniProtKB | |||
| セット | 進化に関連したファミリーのグループ | Pfam.Nii |

InterPro エントリーの種類編集
InterPro エントリーはさらに5種類に分類されます:
- Homologous Superfamily(同種スーパーファミリー)。 配列の類似性は高くないが、構造の類似性から進化的に共通の起源を持つタンパク質のグループ。 これらの項目は、特に2つのメンバーデータベースでのみ提供されている。 CATH-Gene3DとSUPERFAMILYの2つのデータベースで提供されている。 構造的な類似性、関連する機能、配列の相同性によって決定される共通の進化的起源を持つタンパク質のグループ
- Domain(ドメイン)。
- リピート:タンパク質の中で何度も繰り返す傾向がある、通常50アミノ酸以下のアミノ酸の配列。 少なくとも1つのアミノ酸が保存されているアミノ酸の短い配列。 翻訳後修飾部位、保存部位、結合部位、活性部位などが含まれる