La gestione degli errori è una parte essenziale di RxJs, in quanto ne avremo bisogno in quasi tutti i programmi reattivi che scriviamo.
La gestione degli errori in RxJS probabilmente non è così ben compresa come altre parti della libreria, ma in realtà è abbastanza semplice da capire se ci concentriamo a comprendere prima il contratto Observable in generale.
In questo post, forniremo una guida completa contenente le strategie di gestione degli errori più comuni di cui avrete bisogno per coprire la maggior parte degli scenari pratici, partendo dalle basi (il contratto Observable).
- Tabella dei contenuti
- Il contratto Observable e la gestione degli errori
- RxJs subscribe and error callbacks
- Esempio di comportamento di completamento
- Limitazioni del gestore di errori subscribe
- L’operatore catchError
- Come funziona catchError?
- Cosa succede quando viene lanciato un errore?
- La strategia di cattura e sostituzione
- La strategia Catch and Rethrow
- Riduzione di Catch e Rethrow
- Usare catchError più volte in una catena Observable
- L’operatore Finalize
- Esempio di operatore finalize
- La strategia del retry
- Quando riprovare?
- Diagramma di marmo dell’operatore retryWhen
- Smontare come funziona retryWhen
- Creare un Notification Observable
- Strategia di retry immediato
- Immediate Retry Console Output
- Strategia di recupero ritardato
- La funzione di creazione del timer Observable
- L’operatore delayWhen
- delayWhen Operator breakdown
- Implementazione della strategia di ritentamento ritardato
- Retry Strategy Console Output
- Repository Github in esecuzione (con esempi di codice)
- Conclusioni
Tabella dei contenuti
In questo post, tratteremo i seguenti argomenti:
- Il contratto Observable e la gestione degli errori
- RxJs subscribe e error callback
- L’operatore catchError
- La strategia Catch and Replace Strategia
- throwError e la strategia Catch and Rethrow
- Usare catchError più volte in una catena Observable
- L’operatore finalize
- La strategia Retry Strategia
- Quindi ritentareWhen Operatore
- Creazione di un osservabile di notifica
- Strategia di ritentare immediatamente
- Strategia di ritentare in ritardo
- Il delayWhen Operator
- La funzione di creazione del timer Observable
- Esecuzione del repository Github (con esempi di codice)
- Conclusioni
Quindi, senza ulteriori indugi, iniziamo con la nostra immersione profonda nella gestione degli errori di RxJs!
Il contratto Observable e la gestione degli errori
Per capire la gestione degli errori in RxJs, dobbiamo prima capire che qualsiasi flusso può dare errore solo una volta. Questo è definito dal contratto Observable, che dice che un flusso può emettere zero o più valori.
Il contratto funziona così perché è proprio così che tutti i flussi che osserviamo nel nostro runtime funzionano in pratica. Le richieste di rete possono fallire, per esempio.
Un flusso può anche completare, il che significa che:
- il flusso ha terminato il suo ciclo di vita senza alcun errore
- dopo il completamento, il flusso non emetterà più alcun valore
In alternativa al completamento, un flusso può anche dare errore, il che significa che:
- il flusso ha terminato il suo ciclo di vita con un errore
- dopo il lancio dell’errore, il flusso non emetterà altri valori
Si noti che il completamento o l’errore si escludono a vicenda:
- se il flusso completa, non può dare errore dopo
- se il flusso dà errore, non può completare dopo
Nota anche che non c’è obbligo per il flusso di completare o dare errore, queste due possibilità sono opzionali. Ma solo una di queste due può verificarsi, non entrambe.
Questo significa che quando un particolare flusso va in errore, non possiamo più usarlo, secondo il contratto Observable. A questo punto starete pensando: come possiamo recuperare da un errore?
RxJs subscribe and error callbacks
Per vedere il comportamento di gestione degli errori di RxJs in azione, creiamo uno stream e sottoscriviamolo. Ricordiamo che la chiamata subscribe prende tre argomenti opzionali:
- una funzione success handler, che viene chiamata ogni volta che lo stream emette un valore
- una funzione error handler, che viene chiamata solo se si verifica un errore. Questo gestore riceve l’errore stesso
- una funzione gestore di completamento, che viene chiamata solo se il flusso completa
Esempio di comportamento di completamento
Se il flusso non dà errore, allora questo è ciò che vedremmo nella console:
HTTP response {payload: Array(9)}HTTP request completed.Come possiamo vedere, questo flusso HTTP emette solo un valore, e poi completa, il che significa che non si sono verificati errori.
Ma cosa succede se il flusso lancia invece un errore? In questo caso, vedremo invece quanto segue nella console:

Come possiamo vedere, lo stream non ha emesso alcun valore ed è andato immediatamente in errore. Dopo l’errore, non si è verificato alcun completamento.
Limitazioni del gestore di errori subscribe
Gestire gli errori usando la chiamata subscribe è talvolta tutto ciò di cui abbiamo bisogno, ma questo approccio alla gestione degli errori è limitato. Usando questo approccio, non possiamo, per esempio, recuperare dall’errore o emettere un valore di fallback alternativo che sostituisca il valore che ci aspettavamo dal backend.
Impariamo quindi alcuni operatori che ci permetteranno di implementare alcune strategie più avanzate di gestione degli errori.
L’operatore catchError
Nella programmazione sincrona, abbiamo la possibilità di avvolgere un blocco di codice in una clausola try, catturare qualsiasi errore che potrebbe lanciare con un blocco catch e poi gestire l’errore.
Ecco come appare la sintassi catch sincrona:
Questo meccanismo è molto potente perché possiamo gestire in un unico posto qualsiasi errore che accade all’interno del blocco try/catch.
Il problema è che in Javascript molte operazioni sono asincrone, e una chiamata HTTP è uno di questi esempi dove le cose avvengono in modo asincrono.
RxJs ci fornisce qualcosa di simile a questa funzionalità, attraverso l’operatore RxJs catchError.
Come funziona catchError?
Come al solito e come per ogni operatore RxJs, catchError è semplicemente una funzione che prende in input un Observable e produce un Output Observable.
Con ogni chiamata a catchError, dobbiamo passargli una funzione che chiameremo funzione di gestione degli errori.
L’operatore catchError prende come input un Observable che potrebbe andare in errore, e inizia a emettere i valori dell’Observable di input nel suo Observable di output.
Se non si verifica alcun errore, l’Observable di output prodotto da catchError funziona esattamente allo stesso modo dell’Observable di input.
Cosa succede quando viene lanciato un errore?
Tuttavia, se si verifica un errore, allora la logica di catchError si attiva. L’operatore catchError prenderà l’errore e lo passerà alla funzione di gestione dell’errore.
Questa funzione dovrebbe restituire un Observable che sarà un Observable sostitutivo per il flusso che è appena andato in errore.
Ricordiamoci che il flusso di input di catchError è andato in errore, quindi secondo il contratto Observable non possiamo più usarlo.
Questo Observable sostitutivo sarà quindi sottoscritto e i suoi valori saranno usati al posto dell’Observable di input andato in errore.
La strategia di cattura e sostituzione
Facciamo un esempio di come catchError può essere usato per fornire un Observable sostitutivo che emette valori di fallback:
Sottolineiamo l’implementazione della strategia di cattura e sostituzione:
- stiamo passando all’operatore catchError una funzione, che è la funzione di gestione degli errori
- la funzione di gestione degli errori non viene chiamata immediatamente, e in generale, di solito non viene chiamata
- solo quando si verifica un errore nell’Observable di input di catchError, la funzione di gestione degli errori sarà chiamata
- se si verifica un errore nel flusso di input, questa funzione restituisce un osservabile costruito con la funzione
of() - la funzione
of()costruisce un osservabile che emette un solo valore () e poi completa - la funzione di gestione degli errori restituisce l’osservabile di recupero (
of()), che viene sottoscritto dall’operatore catchError - i valori dell’osservabile di recupero vengono poi emessi come valori di sostituzione nell’osservabile di uscita restituito da catchError
Come risultato finale, l’osservabile http$ non darà più errore! Ecco il risultato che otteniamo nella console:
HTTP response HTTP request completed.Come possiamo vedere, il callback di gestione degli errori in subscribe() non viene più invocato. Invece, ecco cosa succede:
- il valore dell’array vuoto
viene emesso - l’osservabile
http$viene poi completato
Come possiamo vedere, l’osservabile sostitutivo è stato usato per fornire un valore di fallback predefinito () ai sottoscrittori di http$, nonostante il fatto che l’osservabile originale ha dato errore.
Si noti che avremmo anche potuto aggiungere un po’ di gestione locale degli errori, prima di restituire l’Observable sostitutivo!
E questo copre la strategia Catch and Replace, ora vediamo come possiamo anche usare catchError per rilanciare l’errore, invece di fornire valori di fallback.
La strategia Catch and Rethrow
Iniziamo notando che l’Observable sostitutivo fornito tramite catchError può anche andare in errore, proprio come qualsiasi altro Observable.
E se ciò accade, l’errore sarà propagato ai sottoscrittori dell’Observable di uscita di catchError.
Questo comportamento di propagazione degli errori ci dà un meccanismo per rilanciare l’errore catturato da catchError, dopo aver gestito l’errore localmente. Possiamo farlo nel modo seguente:
Riduzione di Catch e Rethrow
Disaggiamo passo dopo passo l’implementazione della strategia di Catch e Rethrow:
- proprio come prima, stiamo catturando l’errore, e restituendo un Observable sostitutivo
- ma questa volta, invece di fornire un valore di output sostitutivo come
, stiamo gestendo l’errore localmente nella funzione catchError - in questo caso, stiamo semplicemente registrando l’errore nella console, ma potremmo invece aggiungere qualsiasi logica locale di gestione dell’errore che vogliamo, come ad esempio mostrare un messaggio di errore all’utente
- Stiamo quindi restituendo un Observable sostitutivo che questa volta è stato creato usando throwError
- throwError crea un Observable che non emette mai alcun valore. Invece, va in errore immediatamente usando lo stesso errore catturato da catchError
- questo significa che anche l’Observable di uscita di catchError andrà in errore con lo stesso identico errore lanciato dall’input di catchError
- questo significa che siamo riusciti a rilanciare con successo l’errore inizialmente lanciato dall’Observable di ingresso di catchError al suo Observable di uscita
- l’errore può ora essere ulteriormente gestito dal resto della catena Observable, se necessario
Se ora eseguiamo il codice sopra, ecco il risultato che otteniamo nella console:

Come possiamo vedere, lo stesso errore è stato registrato sia nel blocco catchError che nella funzione di gestione degli errori di sottoscrizione, come previsto.
Usare catchError più volte in una catena Observable
Si noti che possiamo usare catchError più volte in punti diversi della catena Observable, se necessario, e adottare strategie di errore diverse in ogni punto della catena.
Possiamo, per esempio, catturare un errore su nella catena Observable, gestirlo localmente e rilanciarlo, e poi più in basso nella catena Observable possiamo catturare nuovamente lo stesso errore e questa volta fornire un valore di fallback (invece di rilanciarlo):
Se eseguiamo il codice di cui sopra, questo è l’output che otteniamo nella console:
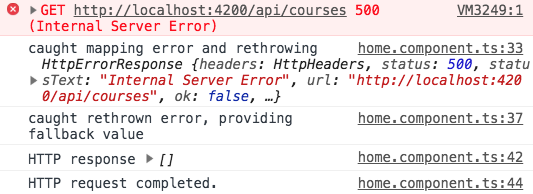
Come possiamo vedere, l’errore è stato effettivamente rigettato inizialmente, ma non ha mai raggiunto la funzione subscribe error handler. Invece, il valore di fallback è stato emesso, come previsto.
L’operatore Finalize
Oltre a un blocco catch per la gestione degli errori, la sintassi sincrona di Javascript fornisce anche un blocco finally che può essere usato per eseguire il codice che vogliamo sempre eseguito.
Il blocco finally è tipicamente usato per rilasciare risorse costose, come per esempio chiudere le connessioni di rete o rilasciare la memoria.
A differenza del codice nel blocco catch, il codice nel blocco finally verrà eseguito indipendentemente dal fatto che venga lanciato o meno un errore:
RxJs ci fornisce un operatore che ha un comportamento simile alla funzionalità finally, chiamato operatore finalize.
Nota: non possiamo chiamarlo l’operatore finally, perché finally è una parola chiave riservata in Javascript
Esempio di operatore finalize
Proprio come l’operatore catchError, possiamo aggiungere più chiamate finalize in diversi punti della catena Observable, se necessario, al fine di assicurarci che le risorse multiple siano rilasciate correttamente:
Eseguiamo ora questo codice, e vediamo come vengono eseguiti i blocchi multipli di finalize:

Nota che l’ultimo blocco finalize viene eseguito dopo le funzioni subscribe value handler e completion handler.
La strategia del retry
In alternativa al lancio dell’errore o alla fornitura di valori di fallback, possiamo anche semplicemente riprovare a sottoscrivere l’Observable andato in errore.
Ricordiamoci che una volta che lo stream va in errore non possiamo recuperarlo, ma nulla ci impedisce di sottoscrivere nuovamente l’Observable da cui lo stream è derivato, e creare un altro stream.
Ecco come funziona:
- Prendiamo l’osservabile in ingresso e lo sottoscriviamo, il che crea un nuovo flusso
- se questo flusso non dà errore, lasciamo che i suoi valori compaiano nell’output
- ma se il flusso dà errore, allora sottoscriviamo di nuovo l’osservabile in ingresso e creiamo un nuovo flusso
Quando riprovare?
La grande domanda qui è, quando ci iscriveremo di nuovo all’input Observable, e riproveremo ad eseguire il flusso di input?
- Lo riproveremo immediatamente?
- Aspetteremo un piccolo ritardo, sperando che il problema sia risolto e poi riprovare?
- faremo un numero limitato di tentativi e poi manderemo in errore il flusso di uscita?
Per rispondere a queste domande, abbiamo bisogno di un secondo Observable ausiliario, che chiameremo Notifier Observable. E’ il Notifier
Observable che determinerà quando il tentativo di retry avviene.
Il Notifier Observable sarà usato dall’operatore retryWhen, che è il cuore della Retry Strategy.
Diagramma di marmo dell’operatore retryWhen
Per capire come funziona l’osservabile retryWhen, diamo un’occhiata al suo diagramma di marmo:

Nota che l’osservabile che viene riprovato è l’osservabile 1-2 nella seconda riga dall’alto, e non l’osservabile nella prima riga.
L’osservabile sulla prima linea con i valori r-r è l’osservabile di notifica, che determinerà quando un tentativo di riprova dovrebbe avvenire.
Smontare come funziona retryWhen
Smontare cosa succede in questo diagramma:
- L’Osservabile 1-2 viene sottoscritto, e i suoi valori si riflettono immediatamente nell’Osservabile di uscita restituito da retryWhen
- anche dopo che l’Osservabile 1-2 è completato, può ancora essere riprovato
- l’Osservabile di notifica emette quindi un valore
r, molto dopo che l’Observable 1-2 ha completato - Il valore emesso dall’Observable di notifica (in questo caso
r) potrebbe essere qualsiasi cosa - ciò che conta è il momento in cui il valore
rviene emesso, perché questo è ciò che fa scattare l’osservabile 1-2 da riprovare - l’osservabile 1-2 viene sottoscritto nuovamente da retryWhen, e i suoi valori si riflettono nuovamente nell’osservabile di uscita di retryWhen
- L’osservabile di notifica emetterà nuovamente un altro valore
r, e la stessa cosa accade: i valori di un nuovo flusso 1-2 sottoscritto inizieranno a riflettersi nell’output di retryWhen - ma poi, l’osservabile di notifica alla fine completerà
- in quel momento, anche il tentativo di retry in corso dell’osservabile 1-2 viene completato in anticipo, il che significa che solo il valore 1 è stato emesso, ma non il 2
Come possiamo vedere, retryWhen semplicemente riprova l’osservabile di input ogni volta che l’osservabile di notifica emette un valore!
Ora che abbiamo capito come funziona retryWhen, vediamo come possiamo creare un Notification Observable.
Creare un Notification Observable
Dobbiamo creare il Notification Observable direttamente nella funzione passata all’operatore retryWhen. Questa funzione prende come argomento di input un Errors Observable, che emette come valori gli errori dell’Observable di input.
Quindi, sottoscrivendo questo Errors Observable, sappiamo esattamente quando si verifica un errore. Vediamo ora come potremmo implementare una strategia di retry immediato usando l’Errors Observable.
Strategia di retry immediato
Per ritentare l’osservabile fallito immediatamente dopo il verificarsi dell’errore, tutto quello che dobbiamo fare è restituire l’Errors Observable senza ulteriori modifiche.
In questo caso, stiamo solo pipettando l’operatore tap a scopo di logging, quindi l’Errors Observable rimane invariato:
Ricordiamoci che l’Observable che stiamo restituendo dalla chiamata alla funzione retryWhen è il Notification Observable!
Il valore che emette non è importante, è importante solo quando il valore viene emesso, perché è quello che innesca un tentativo di retry.
Immediate Retry Console Output
Se ora eseguiamo questo programma, troveremo il seguente output nella console:

Come possiamo vedere, la richiesta HTTP è fallita inizialmente, ma poi è stato tentato un retry e la seconda volta la richiesta è andata a buon fine.
Diamo ora un’occhiata al ritardo tra i due tentativi, ispezionando il log di rete:

Come possiamo vedere, il secondo tentativo è stato emesso immediatamente dopo l’errore, come previsto.
Strategia di recupero ritardato
Impieghiamo ora una strategia alternativa di recupero degli errori, in cui aspettiamo per esempio 2 secondi dopo il verificarsi dell’errore, prima di riprovare.
Questa strategia è utile per cercare di recuperare da certi errori come per esempio richieste di rete fallite causate da un alto traffico del server.
In quei casi in cui l’errore è intermittente, possiamo semplicemente riprovare la stessa richiesta dopo un breve ritardo, e la richiesta potrebbe passare la seconda volta senza alcun problema.
La funzione di creazione del timer Observable
Per implementare la strategia di ritentamento ritardato, dobbiamo creare un Notification Observable i cui valori vengono emessi due secondi dopo ogni errore.
Provo a creare un Notification Observable usando la funzione di creazione del timer. Questa funzione timer prenderà un paio di argomenti:
- un ritardo iniziale, prima del quale non saranno emessi valori
- un intervallo periodico, nel caso in cui vogliamo emettere nuovi valori periodicamente
Diamo un’occhiata al diagramma di marmo della funzione timer:

Come possiamo vedere, il primo valore 0 sarà emesso solo dopo 3 secondi, e poi abbiamo un nuovo valore ogni secondo.
Nota che il secondo argomento è opzionale, il che significa che se lo lasciamo fuori il nostro Osservabile emetterà un solo valore (0) dopo 3 secondi e poi si completerà.
Questo Osservabile sembra un buon inizio per essere in grado di ritardare i nostri tentativi di retry, quindi vediamo come possiamo combinarlo con gli operatori retryWhen e delayWhen.
L’operatore delayWhen
Una cosa importante da tenere a mente sull’operatore retryWhen, è che la funzione che definisce l’osservabile Notification viene chiamata solo una volta.
Quindi abbiamo solo una possibilità di definire il nostro Notification Observable, che segnala quando i tentativi di retry dovrebbero essere fatti.
Definiremo il Notification Observable prendendo l’Errors Observable e applicando l’operatore delayWhen.
Immaginate che in questo diagramma di marmo, l’osservabile sorgente a-b-c è l’osservabile Errors, che sta emettendo errori HTTP falliti nel tempo:

delayWhen Operator breakdown
Seguiamo il diagramma, e impariamo come funziona l’operatore delayWhen:
- ogni valore nell’osservabile Errors in ingresso sarà ritardato prima di apparire nell’osservabile in uscita
- il ritardo per ogni valore può essere diverso, e sarà creato in modo completamente flessibile
- per determinare il ritardo, chiameremo la funzione passata a delayWhen (chiamata funzione di selezione della durata) per ogni valore dell’input Errors Observable
- questa funzione emetterà un Observable che determinerà quando il ritardo di ogni valore di input è trascorso
- ogni valore a-b-c ha il suo Observable di selezione della durata, che alla fine emetterà un valore (che potrebbe essere qualsiasi cosa) e poi completerà
- quando ognuno di questi Osservabili selettori di durata emette dei valori, allora il corrispondente valore di input a-b-c apparirà nell’output di delayWhen
- nota che il valore
bappare nell’output dopo il valorec, questo è normale - questo è perché il
bduration selector Observable (la terza linea orizzontale dall’alto) ha emesso il suo valore solo dopo il duration selector Observable dic, e questo spiega perchécappare nell’output prima dib
Implementazione della strategia di ritentamento ritardato
Mettiamo ora insieme tutto questo e vediamo come possiamo ritentare consecutivamente una richiesta HTTP fallita 2 secondi dopo ogni errore:
Ripercorriamo cosa sta succedendo qui:
- ricordiamo che la funzione passata a retryWhen sarà chiamata solo una volta
- restituiamo in quella funzione un Observable che emetterà valori ogni volta che sarà necessario un retry
- ogni volta che ci sarà un errore, l’operatore delayWhen creerà un Observable selettore di durata, chiamando la funzione timer
- questo Observable selettore di durata emetterà il valore 0 dopo 2 secondi, e poi completerà
- quando ciò accade, l’osservabile delayWhen sa che il ritardo di un dato errore di input è trascorso
- solo una volta che questo ritardo è trascorso (2 secondi dopo che l’errore si è verificato), l’errore appare nell’output dell’osservabile di notifica
- una volta che un valore viene emesso nell’osservabile di notifica, l’operatore retryWhen eseguirà allora e solo allora un tentativo di retry
Retry Strategy Console Output
Vediamo ora come appare nella console! Ecco un esempio di una richiesta HTTP che è stata ritentata 5 volte, dato che le prime 4 volte erano in errore:

Ed ecco il log di rete per la stessa sequenza di ritentamento:

Come possiamo vedere, i ritentativi sono avvenuti solo 2 secondi dopo l’errore, come previsto!
E con questo, abbiamo completato la nostra visita guidata di alcune delle strategie di gestione degli errori RxJs più comunemente usate, ora concludiamo le cose e forniamo un po’ di codice di esempio.
Repository Github in esecuzione (con esempi di codice)
Per provare queste strategie multiple di gestione degli errori, è importante avere un playground funzionante in cui si possa provare a gestire le richieste HTTP che falliscono.
Questo playground contiene una piccola applicazione in esecuzione con un backend che può essere utilizzato per simulare errori HTTP in modo casuale o sistematico. Ecco come appare l’applicazione:

Conclusioni
Come abbiamo visto, capire la gestione degli errori di RxJs significa prima capire i fondamenti del contratto Observable.
Dobbiamo tenere a mente che ogni dato stream può dare errore solo una volta, e questo è esclusivo con il completamento dello stream; solo una delle due cose può accadere.
Per riprendersi da un errore, l’unico modo è quello di generare in qualche modo uno stream sostitutivo in alternativa allo stream in errore, come accade nel caso degli operatori catchError o retryWhen.
Spero che questo post vi sia piaciuto, se volete imparare molto di più su RxJs, vi consigliamo di controllare il corso RxJs In Practice Course, dove molti pattern e operatori utili sono trattati in maniera molto più dettagliata.