Per dare una corretta introduzione ai kernel gaussiani, il post di questa settimana inizierà un po’ più astratto del solito. Questo livello di astrazione non è strettamente necessario per capire come funzionano i kernel gaussiani, ma la prospettiva astratta può essere estremamente utile come fonte di intuizione quando si cerca di capire le distribuzioni di probabilità in generale. Quindi ecco il patto: cercherò di costruire lentamente l’astrazione, ma se mai vi perdete irrimediabilmente, o semplicemente non ne potete più, potete saltare fino al titolo che dice “La parte pratica” in grassetto – è lì che passerò ad una descrizione più concreta dell’algoritmo del kernel gaussiano. Inoltre, se hai ancora problemi, non preoccuparti troppo – La maggior parte dei post successivi su questo blog non richiederanno che tu capisca i kernel gaussiani, quindi puoi semplicemente aspettare il post della prossima settimana (o saltarlo se stai leggendo questo dopo).
Ricorda che un kernel è un modo di collocare uno spazio di dati in uno spazio vettoriale di dimensione superiore in modo che le intersezioni dello spazio dei dati con gli iperpiani nello spazio di dimensione superiore determinino confini decisionali più complicati e curvi nello spazio dei dati. L’esempio principale che abbiamo guardato è stato il kernel che invia uno spazio dati bidimensionale a uno spazio a cinque dimensioni inviando ogni punto con coordinate 


In questo ipotetico spazio vettoriale infinito-dimensionale, possiamo aggiungere vettori nello stesso modo in cui facciamo con i vettori regolari, semplicemente aggiungendo le coordinate corrispondenti. Tuttavia, in questo caso, dobbiamo aggiungere infinite coordinate. Allo stesso modo, possiamo moltiplicare per scalari, moltiplicando ciascuna delle coordinate (infinitamente molte) per un dato numero. Definiremo il kernel dei polinomi infiniti inviando ogni punto 

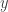


Per tornare al mondo computazionale, possiamo recuperare il nostro kernel originale a cinque dimensioni semplicemente dimenticando tutte le prime cinque delle voci. Infatti, lo spazio originale a cinque dimensioni è contenuto in questo spazio infinito. (Il kernel originale a cinque dimensioni è quello che otteniamo proiettando il kernel polinomiale infinito in questo spazio a cinque dimensioni.)
Ora fate un respiro profondo, perché stiamo per fare un passo avanti. Considerate, per un momento, cos’è un vettore. Se avete mai seguito un corso di algebra lineare matematica, ricorderete che i vettori sono ufficialmente definiti in termini delle loro proprietà di addizione e moltiplicazione. Ma lo ignorerò temporaneamente (con le mie scuse a tutti i matematici che stanno leggendo questo articolo). Nel mondo dell’informatica, di solito pensiamo a un vettore come a una lista di numeri. Se avete letto fin qui, potreste essere disposti a lasciare che quella lista sia infinita. Ma voglio che pensiate a un vettore come a una collezione di numeri in cui ogni numero è assegnato a una cosa particolare. Per esempio, ogni numero nel nostro solito tipo di vettore è assegnato a una delle coordinate/caratteristiche. In uno dei nostri vettori infiniti, ogni numero è assegnato a un punto della nostra lista infinitamente lunga.
Ma che ne dite di questo: Cosa succederebbe se definissimo un vettore assegnando un numero ad ogni punto del nostro spazio dati (di dimensione finita)? Un tale vettore non sceglie un singolo punto nello spazio dei dati; piuttosto, una volta scelto questo vettore, se si punta a qualsiasi punto nello spazio dei dati, il vettore ci dice un numero. In realtà, abbiamo già un nome per questo: Qualcosa che assegna un numero ad ogni punto dello spazio dei dati è una funzione. In effetti, abbiamo guardato molto le funzioni su questo blog, sotto forma di funzioni di densità che definiscono le distribuzioni di probabilità. Ma il punto è che possiamo pensare a queste funzioni di densità come a vettori in uno spazio vettoriale infinito.
Come può una funzione essere un vettore? Bene, possiamo sommare due funzioni semplicemente aggiungendo i loro valori in ogni punto. Questo è stato il primo schema che abbiamo discusso per combinare le distribuzioni nel post della settimana scorsa sui modelli a miscela. Le funzioni di densità per due vettori (bolle gaussiane) e il risultato della loro somma sono mostrati nella figura qui sotto. Possiamo moltiplicare una funzione per un numero in modo simile, il che risulterebbe nel rendere la densità complessiva più chiara o più scura. In effetti, queste sono entrambe operazioni con cui probabilmente avete fatto molta pratica nelle lezioni di algebra e di calcolo. Quindi non stiamo ancora facendo nulla di nuovo, stiamo solo pensando alle cose in un modo diverso.

Il prossimo passo è definire un kernel dal nostro spazio dati originale in questo spazio infinitesimale, e qui abbiamo molte scelte. Una delle scelte più comuni è la funzione blob gaussiana che abbiamo visto alcune volte nei post passati. Per questo kernel, sceglieremo una dimensione standard per i blob gaussiani, cioè un valore fisso per la deviazione 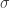
Ora, ecco il problema: per riportare le cose nel mondo computazionale, abbiamo bisogno di scegliere uno spazio vettoriale di dimensioni finite situato in questo spazio vettoriale di dimensioni infinite e “proiettare” lo spazio di dimensioni infinite nel sottospazio di dimensioni finite. Sceglieremo uno spazio a dimensione finita scegliendo un numero (finito) di punti nello spazio dei dati, poi prenderemo lo spazio vettoriale attraversato dai blob gaussiani centrati in quei punti. Questo è l’equivalente del passo vettoriale definito dalle prime cinque coordinate del kernel polinomiale infinito, come sopra. La scelta di questi punti è importante, ma ci torneremo più tardi. Per ora, la domanda è come proiettare?
Per i vettori a dimensione finita, il modo più comune di definire una proiezione è usando il prodotto di punti: Questo è il numero che si ottiene moltiplicando le coordinate corrispondenti di due vettori, poi sommandole. Così, per esempio, il prodotto di punto dei vettori tridimensionali 


Si potrebbe fare qualcosa di simile con le funzioni, moltiplicando i valori che esse assumono nei punti corrispondenti del set di dati. (In altre parole, moltiplichiamo insieme le due funzioni.) Ma non possiamo poi sommare tutti questi numeri perché ce ne sono infiniti. Invece, prenderemo un integrale! (Notate che sto sorvolando su una tonnellata di dettagli qui, e mi scuso di nuovo con tutti i matematici che stanno leggendo questo). La cosa bella qui è che se moltiplichiamo due funzioni gaussiane e integriamo, il numero è uguale a una funzione gaussiana della distanza tra i punti centrali. (Anche se la nuova funzione gaussiana avrà un valore di deviazione diverso.)
In altre parole, il kernel gaussiano trasforma il prodotto di punti nello spazio infinito dimensionale nella funzione gaussiana della distanza tra punti nello spazio dei dati: Se due punti nello spazio dei dati sono vicini, allora l’angolo tra i vettori che li rappresentano nello spazio del kernel sarà piccolo. Se i punti sono lontani, allora i vettori corrispondenti saranno vicini alla “perpendicolare”.
La parte pratica
Perciò, rivediamo quello che abbiamo finora: Per definire un kernel gaussiano 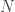
Per capire meglio come funziona questo kernel, cerchiamo di capire come appare l’intersezione di un iperpiano con lo spazio dei dati. (Questo è ciò che si fa con i kernel la maggior parte delle volte, comunque.) Ricordiamo che un piano è definito da un’equazione della forma 


Questo è ancora piuttosto difficile da decomprimere, quindi guardiamo un esempio in cui ciascuno dei valori 

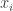





Se regoliamo i parametri
Quindi, questo ci dà più flessibilità per scegliere il confine decisionale (o, almeno, un diverso tipo di flessibilità) ma il risultato finale sarà molto dipendente dai
Trovare una tale collezione di punti è un problema molto diverso da quello su cui ci siamo concentrati nei post finora su questo blog, e rientra nella categoria dell’apprendimento non supervisionato/analisi descrittiva. (Nel contesto dei kernel, può anche essere pensato come selezione/ingegnerizzazione delle caratteristiche). Nei prossimi post, cambieremo marcia e cominceremo ad esplorare idee lungo queste linee.