InterPro sisältää kolme pääkokonaisuutta: proteiinit, allekirjoitukset (joita kutsutaan myös ”menetelmiksi” tai ”malleiksi”) ja merkinnät. UniProtKB:n proteiinit ovat myös InterPron keskeisiä proteiiniyksiköitä. Tiedot siitä, mitkä allekirjoitukset vastaavat merkittävästi näitä proteiineja, lasketaan sitä mukaa kuin UniProtKB julkaisee sekvenssejä, ja nämä tulokset asetetaan yleisön saataville (ks. jäljempänä). Allekirjoitusten ja proteiinien vastaavuudet määräävät sen, miten allekirjoitukset yhdistetään InterPro-tietueisiin: vastaavien proteiinijoukkojen vertailevaa päällekkäisyyttä ja allekirjoitusten vastaavuuksien sijaintia sekvensseissä käytetään sukulaisuuden indikaattoreina. Vain riittävän laadukkaiksi katsotut allekirjoitukset integroidaan InterPro-tietueeseen. Versiossa 81.0 (julkaistu 21.8.2020) InterPro-merkinnöissä on annotoitu 73,9 % UniProtKB:sta löytyvistä residuaaleista, ja toiset 9,2 % on annotoitu merkinnöillä, joiden integrointi on vireillä.

InterPro sisältää myös tiedot liitosvarianteista ja UniParc- ja UniMES-tietokantojen sisältämistä proteiineista.
InterPro-konsortion jäsentietokannatEdit
InterPron merkinnät ovat peräisin 13 ”jäsentietokannasta”, jotka on lueteltu alla.
CATH-Gene3D Kuvaa proteiiniperheitä ja domeenien arkkitehtuureja täydellisissä genomeissa. Proteiiniperheet muodostetaan käyttämällä Markovin klusterointialgoritmia, jota seuraa multi-linkage-klusterointi sekvenssi-identiteetin mukaan. Ennustettujen rakenne- ja sekvenssialueiden kartoitus tehdään käyttämällä CATH- ja Pfam-domeeneja edustavia piilotettuja Markov-mallien kirjastoja. Proteiineille annetaan funktionaalinen annotaatio useista lähteistä. Toiminnallinen ennuste ja domain-arkkitehtuurien analyysi on saatavilla Gene3D-verkkosivustolta. CDD Conserved Domain Database on proteiinien annotaatioresurssi, joka koostuu kokoelmasta annotoituja monisekvenssikohdistusmalleja muinaisille domeeneille ja kokopituisille proteiineille. Nämä ovat saatavilla paikkakohtaisina pistemäärämatriiseina (PSSM), joiden avulla voidaan nopeasti tunnistaa konservoituneita domeeneja proteiinisekvensseistä RPS-BLASTin avulla. HAMAP tarkoittaa High-quality Automated and Manual Annotation of microbial Proteomes. Asiantuntijakuraattorit luovat HAMAP-profiilit manuaalisesti, ja ne tunnistavat proteiineja, jotka kuuluvat hyvin konservoituihin bakteerien, arkeoiden ja plastidien (eli kloroplastien, syanellien, apikoplastien ja muiden kuin fotosynteettisten plastidien) proteiiniperheisiin tai -alaperheisiin. MobiDB MobiDB on tietokanta, johon on merkitty proteiinien sisäisiä häiriöitä. PANTHER PANTHER on laaja kokoelma proteiiniperheitä, jotka on jaettu toiminnallisesti toisiinsa liittyviin aliperheisiin ihmisen asiantuntemuksen avulla. Nämä alaryhmät mallintavat erityisten toimintojen eroavaisuuksia proteiiniperheiden sisällä, mikä mahdollistaa tarkemman yhdistämisen toimintaan (ihmisen kuratoidut molekyylitoimintojen ja biologisten prosessien luokittelut ja polkukaaviot) sekä funktionaalisen spesifisyyden kannalta tärkeiden aminohappojen päättelyn. Kullekin perheelle ja alaperheelle rakennetaan Piilotetun Markovin mallit (HMM) lisäproteiinisekvenssien luokittelua varten. Pfam on laaja kokoelma monisekvenssikohdistuksia ja piilotettuja Markovin malleja, jotka kattavat monia yleisiä proteiinialueita ja -perheitä.
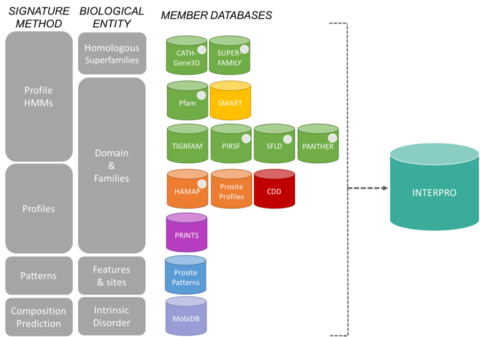
PIRSF-proteiiniluokitusjärjestelmä on verkosto, jossa on useita sekvenssidiversiteettitasoja superperheistä aliperheisiin ja joka kuvastaa kokopituisten proteiinien ja domeenien evolutiivisia suhteita. Ensisijainen PIRSF-luokitusyksikkö on homeomorfinen perhe, jonka jäsenet ovat sekä homologisia (kehittyneet yhteisestä esi-isästä) että homeomorfisia (jakavat täyspitkän sekvenssin samankaltaisuuden ja yhteisen domain-arkkitehtuurin). PRINTS PRINTS on kokoelma proteiinien sormenjälkiä. Sormenjälki on ryhmä konservoituneita motiiveja, joita käytetään proteiiniperheen luonnehtimiseen; sen diagnostista tehoa tarkennetaan UniProtin iteratiivisella skannauksella. Yleensä motiivit eivät ole päällekkäisiä, vaan ne on erotettu toisistaan sekvenssiä pitkin, vaikka ne voivat olla vierekkäisiä 3D-avaruudessa. Sormenjäljet voivat koodata proteiinien poimuja ja toiminnallisuuksia joustavammin ja tehokkaammin kuin yksittäiset motiivit, sillä niiden täysi diagnostinen teho perustuu motiivin naapureiden tarjoamaan keskinäiseen kontekstiin. PROSITE PROSITE on proteiiniperheiden ja -alueiden tietokanta. Se koostuu biologisesti merkittävistä kohdista, malleista ja profiileista, joiden avulla voidaan luotettavasti tunnistaa, mihin tunnettuun proteiiniperheeseen (jos sellainen on) uusi sekvenssi kuuluu. SMART Simple Modular Architecture Research Tool Mahdollistaa geneettisesti liikkuvien domeenien tunnistamisen ja annotoinnin sekä domeeniarkkitehtuurien analysoinnin. Tunnistettavissa on yli 800 domeeniperhettä, joita esiintyy signaloivissa, solunulkoisissa ja kromatiiniin assosioituneissa proteiineissa. Nämä domeenit on annotoitu laajasti fyletisten jakaumien, funktionaalisen luokan, tertiäärirakenteiden ja funktionaalisesti tärkeiden jäännösten osalta. SUPERFAMILY SUPERFAMILY on piilotettujen Markovin profiilimallien kirjasto, joka edustaa kaikkia proteiineja, joiden rakenne tunnetaan. Kirjasto perustuu proteiinien SCOP-luokitukseen: jokainen malli vastaa SCOP-domeenia ja pyrkii edustamaan koko SCOP-superperhettä, johon kyseinen domain kuuluu. SUPERFAMILYn avulla on voitu tehdä rakenteellisia määrityksiä kaikille täysin sekvensoiduille genomeille. SFLD Entsyymien hierarkkinen luokitus, joka yhdistää tietyt sekvenssirakenteen piirteet tiettyihin kemiallisiin ominaisuuksiin. TIGRFAMs TIGRFAMs on kokoelma proteiiniperheitä, joka sisältää kuratoituja monisekvenssikohdistuksia, piilotettuja Markov-malleja (HMM) ja annotaatiota ja joka tarjoaa työkalun funktionaalisesti sukua olevien proteiinien tunnistamiseen sekvenssihomologian perusteella. Ne merkinnät, jotka ovat ”equivalogs”, ryhmittelevät homologisia proteiineja, jotka ovat toiminnaltaan konservoituneita.
TietotyypitEdit
InterPro koostuu seitsemästä eri konsortion jäsenten toimittamasta tietotyypistä:
| Tietotyyppi | Kuvaus | Toimittajatietokannat |
|---|---|---|
| InterPro-tietokannat | Rakennetiedot. ja/tai proteiinien funktionaalisia domeeneja, jotka on ennustettu käyttämällä yhtä tai useampaa allekirjoitusta | Kaikki 13 jäsentietokantaa |
| Jäsentietokantojen allekirjoitukset | Signatuurit jäsentietokannoista. Näihin kuuluvat InterProon integroidut allekirjoitukset, ja ne, jotka eivät ole | Kaikki 13 jäsentietokantaa |
| Proteiini | Proteiinisekvenssit | UniProtKB (Swiss-Prot ja TrEMBL) |
| Proteomi | Kokoelma proteiineista, jotka kuuluvat yhteen organismiin | UniProtKB |
| Rakenne | 3-proteiinien dimensiorakenteet | PDBe |
| Taksonomia | Proteiinien taksonominen informaatio | UniProtKB |
| Set | Evolutiivisesti toisiinsa sukua olevien perheiden ryhmät | Pfam, CDD |

InterPro-merkintätyypitEdit
InterPro-merkinnät voidaan jakaa edelleen viiteen tyyppiin:
- Homologous Superfamily: Ryhmä proteiineja, joilla on yhteinen evolutiivinen alkuperä, mikä näkyy niiden rakenteellisissa yhtäläisyyksissä, vaikka niiden sekvenssit eivät olisikaan hyvin samankaltaisia. Näitä merkintöjä tarjoavat erityisesti vain kaksi jäsentietokantaa: CATH-Gene3D ja SUPERFAMILY.
- Perhe: Ryhmä proteiineja, joilla on yhteinen evolutiivinen alkuperä, joka on määritetty rakenteellisten yhtäläisyyksien, toisiinsa liittyvien toimintojen tai sekvenssihomologian perusteella.
- Domain: Erillinen yksikkö proteiinissa, jolla on tietty funktio, rakenne tai sekvenssi.
- Toisto: Aminohappojen sekvenssi, yleensä enintään 50 aminohappoa, jolla on taipumus toistua useita kertoja proteiinissa.
- Alue: Lyhyt aminohapposekvenssi, jossa vähintään yksi aminohappo on konservoitunut. Näitä ovat muun muassa translaation jälkeiset modifikaatiopaikat, konservoituneet paikat, sitoutumispaikat ja aktiiviset paikat.