Kunnollisen johdannon antamiseksi Gaussin ytimiin tämän viikon postaus alkaa hieman tavallista abstraktimmin. Tämä abstraktiotaso ei ole ehdottoman välttämätön sen ymmärtämiseksi, miten Gaussin ytimet toimivat, mutta abstrakti näkökulma voi olla erittäin hyödyllinen intuition lähteenä, kun yritetään ymmärtää todennäköisyysjakaumia yleensä. Yritän siis rakentaa abstraktiotasoa hitaasti, mutta jos joskus eksyt toivottomasti tai et vain jaksa enää, voit siirtyä otsikkoon, jossa lukee lihavoituna ”Käytännön osuus” – Siellä siirryn konkreettisempaan kuvaukseen Gaussin ytimen algoritmista. Lisäksi, jos sinulla on vielä ongelmia, älä huolehdi liikaa – Suurin osa tämän blogin myöhemmistä viesteistä ei edellytä, että ymmärrät Gaussin ytimiä, joten voit vain odottaa ensi viikon viestiä (tai hypätä siihen, jos luet tätä myöhemmin).
Muista, että ydin on tapa sijoittaa data-avaruus korkeampiulotteiseen vektoriavaruuteen niin, että data-avaruuden ja korkeampiulotteisen avaruuden hypertasojen risteyskohdat määrittävät monimutkaisemmat, kaarevammat päätöksentekorajaukset data-avaruudessa. Tärkein tarkastelemamme esimerkki oli ydin, joka lähettää kaksiulotteisen data-avaruuden viisiulotteiseen avaruuteen lähettämällä jokaisen pisteen, jonka koordinaatit ovat 


Tällä viikolla siirrymme korkeampiulotteisten vektoriavaruuksien yläpuolelle äärettömän ulottuvuuksisiin vektoriavaruksiin. Voit nähdä, kuinka yllä oleva yhdeksänulotteinen ydin on viisiulotteisen ytimen laajennus – olemme periaatteessa vain lisänneet neljä ulottuvuutta loppuun. Jos jatkamme ulottuvuuksien lisäämistä tällä tavoin, saamme yhä korkeampiulotteisempia ytimiä. Jos jatkaisimme tätä ”ikuisesti”, meillä olisi lopulta äärettömän monta ulottuvuutta. Huomaa, että voimme tehdä tämän vain abstraktisti. Tietokoneet voivat käsitellä vain äärellisiä asioita, joten ne eivät voi tallentaa ja käsitellä laskutoimituksia äärettömän moniulotteisissa vektoriavaruuksissa. Teeskentelemme kuitenkin hetken, että pystymme siihen, jotta näemme, mitä tapahtuu. Sitten käännetään asiat takaisin äärelliseen maailmaan.
Tässä hypoteettisessa ääretönulotteisessa vektoriavaruudessa voimme lisätä vektoreita samalla tavalla kuin tavallisia vektoreita, vain lisäämällä vastaavat koordinaatit. Tässä tapauksessa meidän on kuitenkin lisättävä äärettömän monta koordinaattia. Vastaavasti voimme kertoa skalaareilla kertomalla jokaisen (äärettömän monen) koordinaatin tietyllä luvulla. Määrittelemme äärettömän polynomin ytimen lähettämällä jokaisen pisteen 

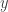


Palataksemme takaisin laskentamaailmaan voimme palauttaa alkuperäisen viisiulotteisen ytimemme unohtamalla kaikki muut paitsi viisi ensimmäistä merkintää. Itse asiassa alkuperäinen viisiulotteinen avaruus sisältyy tähän ääretönulotteiseen avaruuteen. (Alkuperäinen viisiulotteinen ydin on se, mitä saamme projisoimalla äärettömän polynomin ytimen tähän viisiulotteiseen avaruuteen.)
Hengitä nyt syvään, sillä menemme vielä askeleen pidemmälle. Miettikää hetki, mikä on vektori. Jos olet joskus käynyt matemaattisen lineaarialgebran kurssin, saatat muistaa, että vektorit määritellään virallisesti niiden yhteen- ja kertolaskuominaisuuksien perusteella. Mutta aion jättää sen väliaikaisesti huomiotta (pahoittelut kaikille matemaatikoille, jotka lukevat tätä). Tietojenkäsittelymaailmassa ajattelemme yleensä vektorin olevan lista numeroita. Jos olet lukenut tähän asti, olet ehkä valmis antamaan tuon listan olla ääretön. Haluan kuitenkin, että ajattelet vektorin olevan numeroiden kokoelma, jossa jokainen numero on osoitettu tietylle asialle. Esimerkiksi tavanomaisessa vektorityypissämme jokainen numero on osoitettu yhteen koordinaattiin/ominaisuuteen. Yhdessä äärettömässä vektorissamme jokainen numero on osoitettu johonkin kohtaan äärettömän pitkässä luettelossamme.
Mutta entäpä tämä: Mitä tapahtuisi, jos määrittelisimme vektorin osoittamalla numeron jokaiselle pisteelle (äärellisulotteisessa) tietoavaruudessamme? Tällainen vektori ei valitse yksittäistä pistettä data-avaruudessa; pikemminkin, kun olet valinnut tämän vektorin, jos osoitat mihin tahansa pisteeseen data-avaruudessa, vektori kertoo sinulle numeron. No, itse asiassa meillä on jo nimi sille: Jokin, joka antaa numeron jokaiselle data-avaruuden pisteelle, on funktio. Itse asiassa olemme tarkastelleet funktioita paljon tässä blogissa todennäköisyysjakaumia määrittelevien tiheysfunktioiden muodossa. Mutta pointtina on, että voimme ajatella näitä tiheysfunktioita vektoreina äärettömän moniulotteisessa vektoriavaruudessa.
Miten funktio voi olla vektori? No, voimme laskea yhteen kaksi funktiota yksinkertaisesti lisäämällä niiden arvot kussakin pisteessä. Tämä oli ensimmäinen järjestelmä, jota käsittelimme jakaumien yhdistämiseen viime viikon postauksessa seosmalleista. Kahden vektorin (Gaussin pötköjen) tiheysfunktiot ja niiden yhteenlaskun tulos on esitetty alla olevassa kuvassa. Voimme vastaavalla tavalla kertoa funktion jollakin luvulla, jolloin tuloksena on kokonaistiheyden muuttaminen vaaleammaksi tai tummemmaksi. Itse asiassa nämä molemmat ovat operaatioita, joita olet luultavasti harjoitellut paljon algebran tunneilla ja laskennassa. Emme siis tee vielä mitään uutta, ajattelemme vain asioita eri tavalla.

Seuraavaksi määrittelemme ytimen alkuperäisestä data-avaruudestamme tähän äärettömän moniulotteiseen avaruuteen, ja tässä meillä on paljon vaihtoehtoja. Yksi yleisimmistä vaihtoehdoista on Gaussin blob-funktio, jonka olemme nähneet muutaman kerran aiemmissa viesteissä. Tätä kerneliä varten valitsemme Gaussin blobien vakiokoon, eli kiinteän arvon poikkeamalle 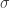
Nyt tässä on ongelma: Palauttaaksemme asiat takaisin laskennalliseen maailmaan meidän on poimittava äärellisen ulottuvuuden vektoriavaruus, joka istuu tässä äärettömän ulottuvuuden vektoriavaruudessa, ja ”projisoitava” äärettömän avaruuden äärellisen avaruuden osa-avaruuteen. Valitsemme äärellisulotteisen avaruuden valitsemalla (äärellisen) määrän pisteitä data-avaruudessa ja ottamalla sitten vektoriavaruuden, jonka keskipisteenä olevat Gaussin pisteet kattavat. Tämä vastaa edellä esitettyä äärettömän polynomin ytimen viiden ensimmäisen koordinaatin määrittelemää vektoritahtia. Näiden pisteiden valinta on tärkeää, mutta palaamme siihen myöhemmin. Toistaiseksi kysymys on, miten projisoimme?
Finite-ulotteisille vektoreille yleisin tapa määritellä projektio on käyttää pistetuotosta: Tämä on luku, jonka saamme kertomalla kahden vektorin vastaavat koordinaatit ja laskemalla ne sitten yhteen. Esimerkiksi kolmiulotteisten vektoreiden 


Voisimme tehdä jotakin vastaavaa funktioiden kanssa kertomalla ne arvot, jotka ne ottavat vastaavissa pisteissä aineistossa. (Toisin sanoen, kerromme kaksi funktiota yhteen.) Mutta emme voi sitten laskea kaikkia näitä lukuja yhteen, koska niitä on äärettömän paljon. Sen sijaan otamme integraalin! (Huomaa, että sivuutan tässä paljon yksityiskohtia, ja pyydän vielä kerran anteeksi kaikilta matemaatikoilta, jotka lukevat tätä). Hienoa tässä on se, että jos kerromme kaksi Gaussin funktiota ja integroimme, luku on yhtä suuri kuin Gaussin funktio keskipisteiden välisestä etäisyydestä. (Tosin uudella Gaussin funktiolla on erilainen poikkeama-arvo.)
Muulla sanoen, Gaussin ydin muuttaa pisteen tulon äärettömän moniulotteisessa avaruudessa Gaussin funktioksi pisteiden välisestä etäisyydestä data-avaruudessa: Jos data-avaruuden kaksi pistettä ovat lähellä toisiaan, niitä kernel-avaruudessa edustavien vektoreiden välinen kulma on pieni. Jos pisteet ovat kaukana toisistaan, niin vastaavat vektorit ovat lähellä ”kohtisuoraa”.
Käytännöllinen osa
Katsotaan siis vielä kerran, mitä meillä on tähän mennessä: Määritelläksemme 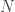
Ymmärtääksemme paremmin, miten tämä kernel toimii, selvitetään, miltä hyperitason ja data-avaruuden leikkauspiste näyttää. (Näin kerneleiden kanssa tehdään joka tapauksessa useimmiten.) Muistetaan, että taso määritellään yhtälöllä, joka on muotoa 


Tätä on vielä aika vaikea purkaa, joten tarkastellaan esimerkkiä, jossa jokainen arvo 

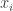





Jos säädämme parametreja
Tämä antaa meille siis enemmän joustavuutta päätöksentekorajan valintaan (tai ainakin erilaista joustavuutta), mutta lopputulos on hyvin riippuvainen
Tällaisen pistekokoelman löytäminen on hyvin erilainen ongelma kuin se, mihin olemme keskittyneet tämän blogin tähänastisissa viesteissä, ja se kuuluu kategoriaan valvomaton oppiminen/kuvaava analytiikka. (Ytimien yhteydessä sitä voidaan ajatella myös ominaisuuksien valintana/tekniikkana). Seuraavissa viesteissä vaihdamme vaihteita ja alamme tutkia näitä ajatuksia.